


pandas进阶

内容主要内容

一.数据计算
1.1求和(sum函数)
DataFrame.sum([axis,skipna,level,......)参数说明:axis=1表示按行相加,axis=0表示按列相加,默认按列相加;skipna=1表示NaN值自动转换为0,skipna=0则不自动转换,默认为自动转换为0,level表示层级
#求和
import pandas as pd
data=[[110,105,99],[105,88,115],[109,120,130]]
index=[1,2,3]
columns=['语文','数学','英语']
df=pd.DataFrame(data=data,index=index,columns=columns)
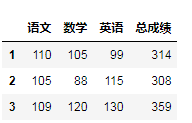
df['总成绩']=df.sum(axis=1)
1.2求均值(mean函数)
DataFrame.mean([axis,skipna,level,......])示例:
#求均值
import pandas as pd
data=[[110,105,99],[105,88,115],[109,120,130],[112,115]]
index=[1,2,3,4]
columns=['语文','数学','英语']
df=pd.DataFrame(data=data,index=index,columns=columns)
new=df.mean()
#增加一行数据(“语文”、“数学”、“英语”的平均成绩,忽略索引)
df=df.append(new,ignore_index=True)
df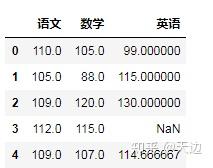
1.3求最大值(max函数)
DataFrame.max([axis,skipna,level,......])示例:
#计算各科成绩的最高分
import pandas as pd
data=[[110,105,99],[105,88,115],[109,120,130],[112,115]]
index=[1,2,3,4]
columns=['语文','数学','英语']
df=pd.DataFrame(data=data,index=index,columns=columns)
new=df.max()
#增加一行数据(“语文”、“数学”、“英语”的最高成绩,忽略索引)
df=df.append(new,ignore_index=True)
df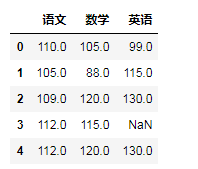
1.4求最小值(min函数)
DataFrame.max([axis,skipna,level,......])示例:
#计算各科成绩的最低分
import pandas as pd
data=[[110,105,99],[105,88,115],[109,120,130],[112,115]]
index=[1,2,3,4]
columns=['语文','数学','英语']
df=pd.DataFrame(data=data,index=index,columns=columns)
new=df.min()
#增加一行数据(“语文”、“数学”、“英语”的最高成绩,忽略索引)
df=df.append(new,ignore_index=True)
df
1.5求中位数(median函数)
DataFrame.median(axis=None,skipna=None,level=None,numberic_only=None,**kwargs)参数说明
axis: axis=1表示行,axis=0表示列,默认值为None(无)
skipna: 布尔型,表示计算结果是否排除了Nan/Null值,默认为True
level:表示索引层级,默认无
numberic_only:仅数字,默认无
**kwargs:要传递给函数的附加关键字参数示例:
#求中位数
import pandas as pd
data=[[110,120,110],[130,130,130],[130,120,130]]
columns=['语文','数学','英语']
df=pd.DataFrame(data=data,columns=columns)
df.median()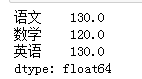
1.6求众数(mode函数)
DataFrame.mode(axis=0,numberic_only=False,dropna=True)参数说明:
axis:axis=1表示行,axis=0表示列,默认为0
numberic_only:仅数字,布尔型,默认为False;如果为True,则仅用于数字列
dropna:是否删除缺失值,布尔型,默认为True.示例:
#计算学生各科成绩的众数
import pandas as pd
data=[[110,120,110],[130,130,130],[130,120,130]]
columns=['语文','数学','英语']
df=pd.DataFrame(data=data,columns=columns)
print(df.mode()) #三科成绩的众数
print(df.mode(axis=1)) #每一行的众数
print(df['数学'].mode()) #“数学”的众数
1.7求方差(Var函数)
DataFrame.var(axis=None,skipna=None,level=None,ddof=1,numberic_only=None,**kwargs)参数说明
axis:axis=1表示行,axis=0表示列,默认为None
skipna:布尔型,表示计算结果是偶排除NaN/Null值,默认为True
level:表示索引层级,默认值为None(无)
ddof:整型,默认为1,自由度,计算中使用的除数是N-ddof,其中N表示元素的数量。
numberic_only:仅数字,布尔型,默认无
**kwargs:要传递给函数的附加关键字参数示例:
#通过方差判断谁的物理成绩更稳定
import pandas as pd
data =[[110,113,102,105,108],[118,98,119,85,118]]
index=['小黑','小白']
columns=['物理1','物理2','物理3','物理4','物理5']
df=pd.DataFrame(data=data,index=index,columns=columns)
df['方差']=df.var(axis=1)
df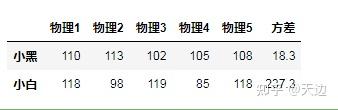
1.8求标准差(std函数)
DataFrame.std(axis=None,skipna=None,level=None,ddof=1,numberic_only=None,**kwargs)std的用法跟var函数一样,这里不再赘述
#计算各科成绩的标准差
import pandas as pd
data=[[110,120,110],[130,130,130],[130,120,130]]
columns=['语文','数学','英语']
df=pd.DataFrame(data=data,columns=columns)
new=df.std()
df=df.append(new,ignore_index=True)
df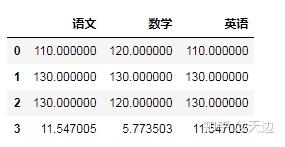
1.9求分位数(quantile函数)
DataFrame.quantile(q=0.5,axis=0,numberic_only=True,interpolation='linear')参数说明:
q: 浮点型或数组,默认为0.5(50%分位数),其值在0~1之间
axis:axis=1表示行,axis=0表示列。默认为0
numberic_only:仅数字,布尔型,默认为True
interpolation:内插值,可选参数,用于指定要使用的插值方法示例:
#通过分位数确定被淘汰的35%的学生
import pandas as pd
data=[120,89,98,78,65,102,112,56,79,45]
columns=['数学']
df=pd.DataFrame(data=data,columns=columns)
#计算出35%的分位数
x=df['数学'].quantile(0.35)
#输出淘汰学生
print(df[df['数学']<=x])
二.数据格式化
2.1 设置小数位数
DataFrame.round(decimals=0,args,**kwargs)参数说明:
decimals:每一列四舍五入的小数位数,整型、字典或Series对象。
args:附加的关键字参数
**kwargs:附加的关键字参数示例:
###设置小数点
import pandas as pd
import numpy as np
df=pd.DataFrame(np.random.random([5,5]),columns=['A1','A2','A3','A4','A5'])
print(df)
print(df.round(2))#保留2位小数
print(df.round({'A1':1,'A2':2})) #A1列保留小数点后1位,A2列保留小数点后2位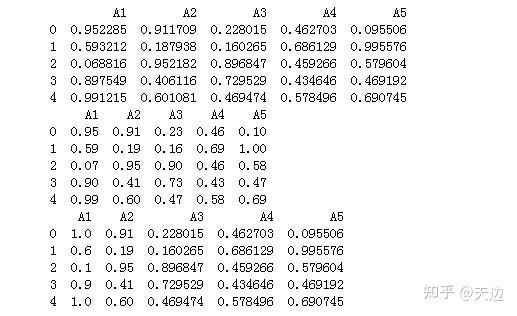

2.2 设置百分比
在数据分析中,有时候需要百分比数据。那么,利用自定义函数将数据进行格式处理,处理后的数据就可以从浮点型转换成带指定小数位数的百分比数据,主要用apply函数与format函数
#将制定数据格式化为百分比数据
import pandas as pd
import numpy as np
df=pd.DataFrame(np.random.random([5,5]),columns=['A1','A2','A3','A4','A5'])
df['百分比_1']=df['A1'].apply(lambda x :format(x,'.0%'))#整列保留0位小数
df['百分比_2']=df['A1'].apply(lambda x:format(x,'.2%'))#整列保留2位小数
df['百分比_3']=df['A1'].map(lambda x:'{:.0%}'.format(x))#使用map函数整列保留0位小数
df

2.3 设置千位分隔符
由于业务需要,有时候需要将数据格式化为带千位分隔符的数据,那么,处理后的数据不再是浮点型而是对象型
###将金额格式化为带千位分隔符的数据
import pandas as pd
import numpy as np
data=[['零基础学python','1月',49768889],['零基础学python','2月',11777775],['零基础学Python','3月',13799990]]
columns=['t图书','月份','码洋']
df=pd.DataFrame(data=data,columns=columns)
df['码洋']=df['码洋'].apply(lambda x :format(int(x),','))
df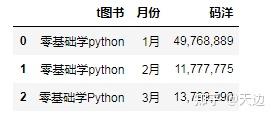
三.数据分组统计
3.1 分组统计groupby()函数
DataFrame.groupby(by=None,axis=0,level=None,asindex=True,sort=True,group_keys=True,squeeze=False,.......)参数说明
by :确定组
axis:axis=1表示行,axis=0表示列,默认值为0
level:表示索引层级,默认无
as_index:布尔型,默认为True
sort:对组进行排序,布尔型,默认为True
group_keys:布尔型,默认为True
squeeze :布尔型,默认为True例子1:按照一列分组统计
#按照一列分组统计
import pandas as pd
df=pd.read_csv(r'D:\Code\04\15\JD.csv',encoding='gbk')
df1=df[['一级分类','7天点击量','订单预定']]
df_sum=df1.groupby('一级分类').sum()
df_sum

例子2:按照"两级分类"统计订单数据
#例子2:按照"两级分类"统计订单数据
df2=df[['一级分类','二级分类','7天点击量','订单预定']]
df2.head()
df2_sum=df2.groupby(['一级分类','二级分类']).sum()#分组统计求和
df2_sum
例子3:统计各编程语言的7天点击量
#例子3:统计各编程语言的7天点击量
df3=df[['二级分类','7天点击量']]
df3_sum=df3.groupby('二级分类').sum()
df3_sum
3.2 对分组数据进行迭代
通过for循环对分组统计数据进行迭代(遍历分组数据)
例子1:迭代“一级分类”的订单数据
#迭代“一级分类”的订单数据
#抽取数据
df1=df[['一级分类','7天点击量','订单预定']]
for name ,group in df1.groupby('一级分类'):
print (name)
print(group)上述代码中的name 是groupby中“一级分类”的值,group是分组后的数据。如果groupby对多列进行分组,那么需要在for循环中指定多列
例子2:迭代“两级分类”的订单数据
##迭代“一级分类”、“二级分类”的订单数据
import pandas as pd
import numpy as np
df=pd.read_csv(r'D:\Code\04\15\JD.csv',encoding='gbk')
df2=df[['一级分类','二级分类','7天点击量','订单预定']]
for (key1,key2),group in df2.groupby(['一级分类','二级分类']):
print(key1,key2)
print(group)

3.3 对分组的某列或多列进行聚合(agg函数)
Python也可以实现像SQL中的分组聚合运算操作,主要通过groupby函数与agg函数实现
对分组统计结果使用聚合函数
例题1:按“一级分类”分组统计“7天点击量”和“订单预定”的平均值和总和
#按“一级分类”分组统计“7天点击量”和“订单预定”的平均值和总和
import pandas as pd
import numpy as np
df=pd.read_csv(r'D:\Code\04\15\JD.csv',encoding='gbk')
df1=df[['一级分类','7天点击量','订单预定']]
df_agg=df1.groupby('一级分类').agg(['mean','sum'])
df_agg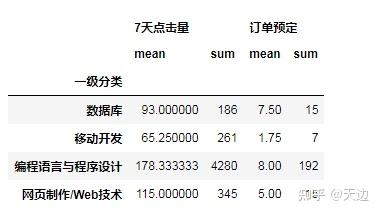
例题2:按“一级分类”分组统计“7天点击量”的平均值值总和一级“订单预定”总和
#例题2:按“一级分类”分组统计“7天点击量”的平均值值总和一级“订单预定”总和
import pandas as pd
import numpy as np
df=pd.read_csv(r'D:\Code\04\15\JD.csv',encoding='gbk')
df1=df[['一级分类','7天点击量','订单预定']]
df_agg =df1.groupby('一级分类').agg({'7天点击量':['mean','sum'],'订单预定':['sum']})
df_agg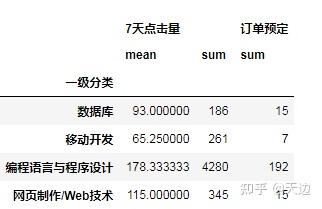
3.4 通过字典和Series对象进行分组统计
3.4.1 通过字典进行分组统计
首先创建字典建立的对应关系,然后将字典传递给groupby函数,从而实现数据分组统计。
例子1:通过字典分组统计“北上广”的销量
#例子1:通过字典分组统计“北上广”的销量
import pandas as pd
df=pd.read_csv(r'D:\Code\04\23\JD.csv',encoding='gbk')#导入数据
df=df.set_index(['商品名称'])
dict1={'上海出库销量':'北上广','北京出库销量':'北上广',
'成都出库销量':'成都','武汉出库销量':'武汉',
'西安出库销量':'西安'}
df1=df.groupby(dict1,axis=1).sum()
df1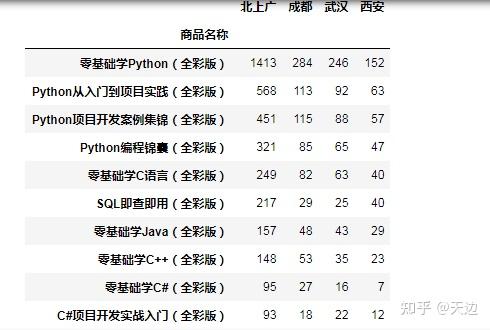

3.4.2 通过Series对象进行分组统计
通过Series对象分组统计时,它与字典的方法类似
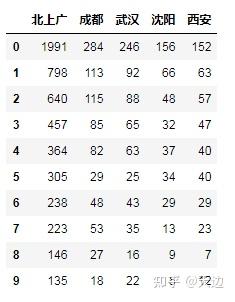
#通过Series对象分组统计“北上广”销量
import pandas as pd
df=pd.read_csv(r'D:\Code\04\24\JD.csv',encoding='gbk')
data={'上海出库销量':'北上广','北京出库销量':'北上广','广州出库销量':'北上广',
'成都出库销量':'成都','武汉出库销量':'武汉','沈阳出库销量':'沈阳','西安出库销量':'西安'}
s1=pd.Series(data)
df1=df.groupby(s1,axis=1).sum()
四.数据移位
什么是数据移位呢?例如,分析数据时需要上一条数据怎么办?当然是移动至上一条,从而得到该条数据,这就是数据移位。shift方法是一个非常有用的方法,用于数据移位与其他方法结合。
DataFrame.shift(periods=1,freq=None,axis=0)
参数说明:
periods:表示移动的幅度,可以是正数;也可以是负数,默认值是1,1表示移动一次,注意这里移动的都是数据, 而索引是不移动的,移动之后没有对应值的,就赋值为NaN。
freq:可选参数,默认值为None,只适用于时间序列,如果这个参数存在,那么会按照参数值里移动时间索引,而数据值不会发生变化。
axis:axis表示行,axis=0表示列,默认值为0。
#统计学生英语周测试成绩的升降情况:
import pandas as pd
data=[110,105,99,120,115]
index=[1,2,3,4,5]
df=pd.DataFrame(data=data ,index=index,columns=['英语'])
df['升降']=df['英语']-df['英语'].shift()
df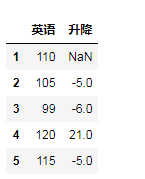
shift方法还有很多方面的应用,后续在慢慢学吧
五.数据转换
4.5.1 一列数据转换为多列数据
例子1:分割“收货地址”数据中的“省、市、区”
#例子1:分割“收货地址”数据中的“省、市、区”
import pandas as pd
#导入数据,指定列数据“买家会员名”、“收货地址”
df= pd.read_excel(r'D:\Code\04\26\mrbooks.xls',usecols=['买家会员名','收货地址'])
#split方法分割“收货地址”
series=df['收货地址'].str.split(' ',expand=True)
df['省']=series[0]
df['市']=series[1]
df['区']=series[2]
df.head()

split方法
saplit方法的DataFrame对象中的str.split内置方法可以实现分割字符串
Series.str.split(pat=None,n=-1,expand=False)参数说明:
pat:字符串、符号、正则表达式,表示字符串分割的依据,默认以空格分割字符串
n:整型,分割次数,默认值是-1。0或-1都将返回所有拆分的字符串
expand:布尔型,分割后的结果是否转换为DataFrame,默认值是False。例子2:以逗号分割多种商品数据
通过join方法与split方法结合,以逗号“,”分割“宝贝标题”
#通过join方法与split方法结合,以逗号“,”分割“宝贝标题”
df= pd.read_excel(r'D:\Code\04\27\mrbooks.xls',usecols=['买家会员名','宝贝标题'])
df=df.join(df['宝贝标题'].str.split(',',expand=True))
df#对元祖数据进行分割
#对元祖数据进行分割
import pandas as pd
#创建包含一组元祖数据
df=pd.DataFrame({'a':[1,2,3,4,5], 'b':[(1,2),(3,4),(5,6),(7,8),(9,10)]})
#使用apply函数对元祖进行分割
df=df.join(df['b'].apply(pd.Series))
df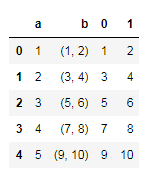
4.5.2 行列转换
在pandas处理数据的过程中,有时需要对数据进行行转列或重排,这时主要使用stack方法、unstack方法和pivot方法
(1)stack方法
DataFrame.stack(level=-1,dropna=True)参数说明:
level:索引层级,定义为一个标签或索引或标签列表,默认值是-1。
dropna:布尔型,默认值是True例子:对英语成绩表进行行列转换
#对英语成绩进行行转列
import pandas as pd
df=pd.read_excel(r'D:\Code\04\29\grade.xls')
df=df.set_index(['班级','序号'])
df=df.stack()
df
(2) unstack()方法
unstack方法是stack方法的逆操作,即将最内层的行索引转换成列索引
DataFrame.unstack(level=-1,fill_value=None)参数说明:
level:索引层级,定义为一个标签或索引或标签列表,默认值是-1
fill_value:整型,字符串或字典,如果unstack方法产生丢失值,则用这个值替换NaN。例子:使用unstack方法转换学生成绩表
#用unstack()方法转换学生成绩表
import pandas as pd
df=pd.read_excel(r'D:\Code\04\30\grade.xls',sheet_name='英语2')
df=df.set_index(['班级','序号','Unnamed: 2'])
df.unstack()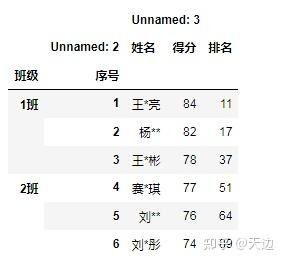
(3)使用pivot方法转换学生成绩表
pivot方法针对列的值,即指定某列的值作为索引,指定某列的值作为索引,然后再指定哪些列作为索引对应的值。unstack方法针对索引进行操作;pivot方法针对值进行操作。但,实际上,两者在功能方面往往可以互相实现。
DataFrame.pivot(index=None,columns=None,values=None)参数说明:
index:字符串或对象,可选参数。列用于创建新DataFrame数据的索引。如果没有,则使用现有索引
columns:字符串或对象,列来创建新DataFrame 数据的列
values:列用于填充新DataFrame数据的值,如果未指定,则将使用所有剩余的列,结果将具有分层索引列。示例:
#使用pivot方法转换学生成绩表
import pandas as pd
df=pd.read_excel(r'D:\Code\04\31\grade.xls',sheet_name='英语3')
df_1=df.pivot(index='序号',columns='班级',values='得分')
df_1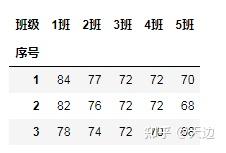
4.5.3 DataFrame 转换为字典
将DataFrame转换为字典主要使用DataFrame对象中的to_dict方法,以索引作为字典的键(key),以列作为字典的值(value).
例子:将Excel表的销售数据转换为字典
#例子:将Excel表的销售数据转换为字典
import pandas as pd
df=pd.read_excel(r'D:\Code\04\32\mrbooks.xls')
df1=df.groupby(['宝贝标题'])['宝贝总数量'].sum().head()
mydict=df1.to_dict()
for i,j in mydict.items():
print(i,':\t',j)

4.5.4 DataFrame 转换为列表
将DataFrame 对象转换为列表时,主要使用DataFrame的tolist方法
例子:将电商数据转换为列表
import pandas as pd
df=pd.read_excel(r'D:\Code\04\33\mrbooks.xls')
df1=df[['买家会员名']].head()
list1=df1['买家会员名'].values.tolist()
for s in list1 :
print(s)
4.5.5 DataFrame 转换为元组
将DataFrame转换为元组时,首先通过循环语句按行读取DataFrame数据,然后使用元祖函数tuple将其转换为元组。
例子:将EXCEL数据转换为元组
#将excel表中的人物关系部分数据转换为元组:
import pandas as pd
df=pd.read_excel(r'D:\Code\04\34\fl4.xls')
df1=df[['label1','label2']].head()
tuples=[tuple(x) for x in df1.values]
for t in tuples :
print(t)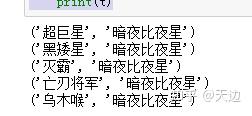
4.5.6 Excel转换为HTML网页格式
例子:将EXCEL订单数据转换为HTML格式
#例子:将EXCEL订单数据转换为HTML格式
import pandas as pd
df=pd.read_excel(r'D:\Code\04\35\mrbooks.xls')
df.to_html('mrbooks.html',header=True,index=False)六.数据合并
DataFrame 数据合并主要使用Merge方法,Concat方法。
6.1 Merge方法:
Pandas 模块的Merge方法是按照两个DataFrame对象列名相同的列进行连接合并,两个DataFrame对象必须具有同名的列。
语法:
DataFrame.merge(right,how='inner',on=None,righton=None,left_index=False,sort=False,suffiex=('_x,'_y),copy=True,indicator=False,validate=None)参数说明:
right:合并对象,DataFrame对象或Series对象
how:合并类型,参数值可以是left、right、outer或inner,默认值是inner
on:标签、列表或数组,默认None。DataFrame对象联接的列或索引级别名称;也可以是DataFrame对象长度的数组或数组列表
left_on :标签、列表或数组,默认值为None,要连接的左数据集的列或索引级名称;也可以是左数据集长度的数组或
数组列表。
right_on:标签、列表或数组,默认值为None,要连接的右数据集列或索引级名称;也可以是右数据集长度的数组或数组列表
left_index:布尔型,默认为False。使用左数据集的索引作为连接键。如果是多重索引,则其他数据中的键数(索引或列数)
必须匹配索引级别数。
right_index:布尔型,默认为False。使用右数据集的索引作为连接键。
suffixes:元组类型,默认值为('_x','_y')。当左侧数据集和右侧数据集的列名相同时,数据合并后列名将带上“_x”和
“_y”后缀
copy:是否复制数据,默认值为True ,如果为False,则不复制数据。
indicator:布尔型或字符串,默认值为False。如果值为True,则添加一个列以输出名为“_merge”的DataFrame对象,
其中包含每一行的信息,如果 字符串,将向输出的DataFrame对象中添加包含每一行信息的列,并将列命名为
字符型的值。
validata:字符串,检查合并数据是否为指定类型。可选参数。6.1.1 常规合并
例子:合并学生成绩单
#合并学生成绩单
import pandas as pd
df1=pd.DataFrame({'编号':['mr001','mr002','mr003'],
'语文':[110,105,109],
'数学':[105,88,120],
'英语':[99,115,130]})
df2=pd.DataFrame({'编号':['mr001','mr002','mr003'],
'体育':[34.5,39.7,38]})
df_merge=pd.merge(df1,df2,on='编号')
df_merg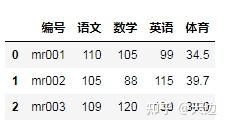
通过索引列合并数据
df_merge=pd.merge(df1,df2,right_index=True,left_index=True)
df_merge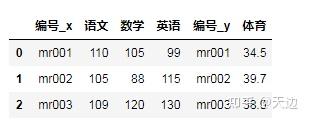
对合并数据去重
#对合并数据去重
df_merge=pd.merge(df1,df2,on='编号',left_index=True,right_index=True)
df_merge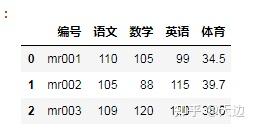
#用how合并
#合并学生成绩单
import pandas as pd
df1=pd.DataFrame({'编号':['mr001','mr002','mr003'],
'语文':[110,105,109],
'数学':[105,88,120],
'英语':[99,115,130]})
df2=pd.DataFrame({'编号':['mr001','mr002','mr003'],
'体育':[34.5,39.7,38]})
df_merge=pd.merge(df1,df2,on='编号',how='left')
df_merge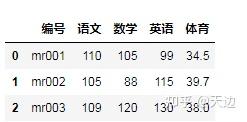
left就是让df1保留所有的行列数据,df2则根据df1的行列进行补全。
6.1.2 多对一的数据合并
多对一是两个数据集(df1,df2)的共有列中的数据不是一对一的关系,例如df1中的“编号”是唯一的,而df2中的“编号”中有重复的数据
例子:根据共有列进行合并
#根据共有列中的数据进行合并,df2根据df1的行进行补全
import pandas as pd
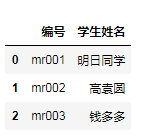
df1=pd.DataFrame({'编号':['mr001','mr002','mr003'],
'学生姓名':['明日同学','高袁圆','钱多多']})
df2=pd.DataFrame({'编号':['mr001','mr001','mr003'],
'语文':[110,105,109],
'数学':[105,88,120],
'英语':[99,115,130],
'时间':['1月','2月','1月']})
df_merge=pd.merge(df1,df2,on='编号')
df_merge

6.1.3 多对多的数据合并
多对多是指两个数据集(df1、df2)的共有列中的数据不全是一对一的关系,都包含了重复数据
例子:合并数据并相互补全
#多对多的合并
import pandas as pd
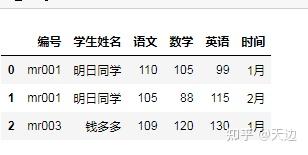
df1=pd.DataFrame({'编号':['mr001','mr002','mr003','mr001','mr001'],
'体育':[34.5,39.7,38,33,35]})
df2=pd.DataFrame({'编号':['mr001','mr002','mr003','mr003','mr003'],
'语文':[110,105,109,110,108],
'数学':[105,88,120,123,119],
'英语':[99,115,130,109,128]})
df_merge=pd.merge(df1,df2)
df_merge6.2 Concat方法:
Concat方法可以根据不同的方式将数据合并,语法如下
pandas.concat(objs,axis=0,join='outer',ignoreindex: bool=False,keys=None,levels=None,names=None,
verify_integrity:bool=False,sort:bool=False,copy:bool=True)6.2.1 表结构相同的数据直接合并,即首尾相接
dfs=[df1,df2,df3]
result=pd.concat(dfs)6.2.2 如果想要在合并数据时标记源数据来自哪张表,则需要在代码中加入参数keys
result=pd.concat([df1,df2],axis=1,join_axes=[df2.index])七.数据导出
7.1 to_excel
语法:
DataFrame.toexcel(excel_writer,sheet_name='sheet1',np_rep='' ,
float_format=None,columns=None,header=True,index=True,index_lable=None,
startrow=0,startcol=0,engine=None,merge_cells=True,encoding=None,inf_rep='inf',
verbose=True,freeze_panes=None)案例代码:
##将结果导出为excel文件
df_merge.to_excel(excel_writer=r'D:\导出文件.xlsx',#s设置导出路径
sheet_name='测试文档',#设置导出sheet名称
index=False,#设置索引
columns=['编号','语文','数学','英语'],#设置要导出的列
encoding='utf-8',#设置编码
na_rep=0,#缺失值处理
inf_rep=0)#无穷值填充为0
7.2 to_csv
语法:
DataFrame.tocsv(path_or_buf,sep,na_rep,float_format,columns,header,index,
index_lable,mode,encoding,line_terminator,quotechar,doublequote,escapechar,
chunksize,tupleize_cols,date_format)案例 代码:
df_merge.to_csv(path_or_buf =r'D:\导出csv文件.csv',#存放路径
index=False,#设置索引
columns=['编号','语文','数学','英语'],#设置要导出的列
sep = ',',#设置分隔符号
na_rep=0,#缺失值处理
encoding='utf-8-sig')#'utf-8'设置编码格式
7.3 将文件导出到多个sheet中
将多个文件存放在多个sheet中时就需要用ExcelWriter()函数
#7.3将多个文件存放在多个sheet中
#声明一个读写对象writer
writer = pd.ExcelWriter(r'D:\多个sheet文件.xlsx',engine = 'xlsxwriter')
#分别将df1、df2、df_merge写入Excel中的sheet1,sheet2,sheet3中。
df1.to_excel(writer,sheet_name='表1',index = False)
df2.to_excel(writer,sheet_name='表2',index = False)
df_merge.to_excel(writer,sheet_name='表3',index = False)
#保存要读写的文件
writer.save()八.日期处理
8.1 DataFrame的日期数据转换
pandas中的to_datetime方法可以用来批量进行日期转换,对于处理大数据非常的实用和方便,它可以将日期转换成所需的各种格式。
语法:
pandas.to_datetime()
示例1:将各种日期字符串转换为指定的日期格式
#pd.to_datetime()
#将“2020年2月14日”的各种格式转换为日期格式
import pandas as pd
df=pd.DataFrame({'原日期':['14-Feb-20','02/14/2020','2020.02.14','2020/2/14','20200214']})
df['转换后的日期']=pd.to_datetime(df['原日期'])

示例2:将一组数据组合为日期数据
#示例2:将一组数据组合为日期数据
df=pd.DataFrame({'year':[2018,2019,2020],
'month':[1,3,2],
'day':[4,5,14],
'hour':[13,8,2],
'minute':[23,12,14],
'second':[2,4,0]})
df['组合后的日期']=pd.to_datetime(df)
df

8.2 df对象的使用
df对象是Series 对象中用于获取日期属性的一个访问器对象,通过它可以获取日期中的年、月、日、星期数、季节等,还可以判断日期是否处在年底。
语法:
Series.dt()
示例:获取日期中的年月日等
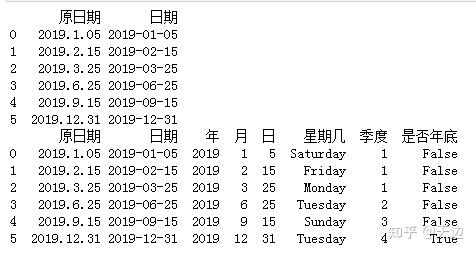
import pandas as pd
df=pd.DataFrame({'原日期':['2019.1.05','2019.2.15','2019.3.25','2019.6.25','2019.9.15','2019.12.31']})
df['日期']=pd.to_datetime(df['原日期'])
print(df)
df['年'],df['月'],df['日']=df['日期'].dt.year,df['日期'].dt.month,df['日期'].dt.day
df['星期几']=df['日期'].dt.day_name()
df['季度']=df['日期'].dt.quarter
df['是否年底']=df['日期'].dt.is_year_end
print(df)

8.3 获取日期区间的数据
获取日期区间的数据的方法是直接在DataFrame对象中输入日期或日期区间,但前提必须设置日期为索引
df['2018'] #获取2018年的数据
df['2017':'2018'] #获取2017年至2018年的数据
df['2018-07'] #获取2018年7月份数据
df['2018-05-06':'2018-05-06'] #获取某一天的数据示例1:获取指定日期区间的订单数据
#获取指定日期区间的订单数据
import pandas as pd
df=pd.read_excel(r'D:\Code\04\47\mingribooks.xls')
df1=df[['订单付款时间','买家会员名','联系手机','买家实际支付金额']]
df1=df1.sort_values(by=['订单付款时间'])
df1=df1.set_index('订单付款时间')
df1['2018-5-11':'2018-6-10']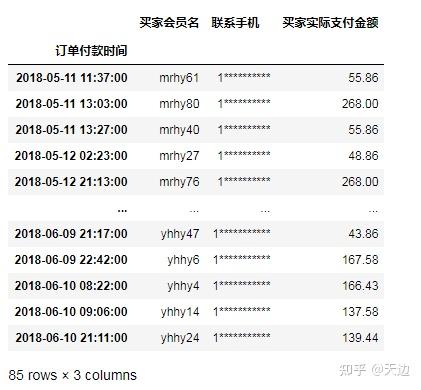

8.4 按不同时期统计并显示数据
8.4.1 按不同时期统计数据
按时期统计数据主要通过DataFrame对象中的resample方法结合数据计算函数实现,resample方法主要应用于时间序列的频率转换和重采样,它可以从日期中获取年、月、日、星期、季节等,结合数据计算函数就可以按年、月、日、周、季度等不同时期来统计数据。需要注意的是,resample函数要求索引必须是日期型
示例:
df1=df1.resample('AS').sum()
df2=df1.resample('Q').sum()
df3=df1.resample('M').sum()
df4=df1.resample('w').sum()
df5=df1.resample('D').sum()
8.4.2 按不同时期显示数据(period)
DataFrame.period(freq=None,axis=0,copy=True)
示例:从日期中获取不同的时期
#按不同时期显示数据(period)
df1.to_period('A')#按年
df1.to_period('Q')#按季度
df1.to_period('M')#按月
df1.to_period('W')#按周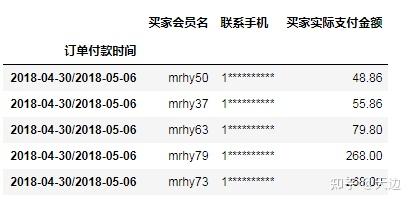
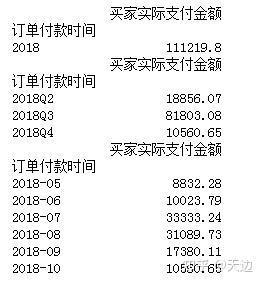
示例:按时期统计并显示数据
import pandas as pd
#获取数据
df=pd.read_excel(r'D:\Code\04\47\mingribooks.xls')
df1=df[['订单付款时间','买家会员名','联系手机','买家实际支付金额']]
df1=df1.sort_values(by=['订单付款时间'])
#将索引设置好
df1=df1.set_index('订单付款时间')
#按年统计并显示数据
df2=df1.resample('AS').sum().to_period('A')
print(df2)
#按季度统计并显示数据
df3=df1.resample('Q').sum().to_period('Q')
print(df3)
#按月统计并显示数据
df4=df1.resample('M').sum().to_period('M')
print(df4)
九.时间序列
9.1 重采样(Resample方法)
通过前面的学习,我们学会了如何生成不同频率的时间索引,如按小时、按天、按周、按月等。如果想对数据进行不同频率的转换,该怎么办呢?在pandas中,对时间序列的频率的调整称之为重新采用,即将时间序列从一个频率转换到另一个频率的处理过程,例如将每天一个频率,转换为每5天为一个频率。
函数及语法:
DataFrame.resample(rule,how=None,axis=0,fill_method=None,closed=None,lable=None,convention='start',kind=None,
limit=None,base=0,on=None,level=None)参数说明:
# rule:字符串,偏移量表示目标字符串或对象转换
# how : 用于产生聚合值的函数名或数组函数。例如sum、mean、first、last、max、min等
# axis:整型,表示行列,0表示列,1表示行,默认值为0
# fill_method :升采样时所使用的填充方法,ffill方法(用前值填充)或bfill方法(用后值填充),默认值为None
# closed:当降采样时,时间区间的开和闭,"right"表示左开右闭,"left"表示左闭右开,默认值是right。
# lable:当降采样时,如何设置聚合值的标签。默认值为None
# convention:当重采样时,降低频率转换到高频率所采用的约定,其值为‘start’或‘end’,默认值为‘start’
# kind:聚合到时期(“period”)或时间戳(“timestamp”),默认聚合到时间序列的索引类型,默认值为None.
# loffset:聚合标签的时间校正值,默认值为None
# limit:向前或向后填充时,允许填充的最大期数,默认值为None
# base:整型,默认值为0,对于均匀细分1天的频率,聚合间隔为原点
# on :字符串,可选参数,默认值为None,用于多索引,重新采样的级别名称或级别编号,级别必须与日期区间类似。示例:将一分钟的时间序列转换为3分钟
#首先创建一个包含9个一分钟的时间序列,然后使用resample方法转换为3分钟的时间序列并对索引列进行求和计算
import pandas as pd
index = pd.date_range('02/02/2020',periods=9,freq='T')
series=pd.Series(range(9),index=index)
print(series)
#使用resample方法转换为3分钟的时间序列并对索引列进行求和
print(series.resample('3T').sum())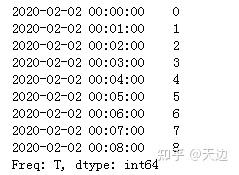
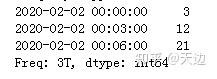
9.2 降采样处理
降采样是周期由高频转向低频,例如将5min的股票交易数据转换为日交易,按天统计的销售数据转换为按周统计。
数据降采样会涉及到数据的聚合,例如,“天数据”变成“周数据”那么就要对一周7天的数据进行聚合,聚合的方式主要包括求和、求均值等。
示例:按周统计销售数据
#按周统计销售数据
import pandas as pd
df=pd.read_excel(r'D:\Code\04\50\time.xls')
df1=df.set_index('订单付款时间')#设置索引
df1.resample('W').sum()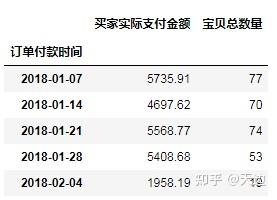
closed参数:左闭右开
#按周统计销售数据
import pandas as pd
df=pd.read_excel(r'D:\Code\04\50\time.xls')
df2=df.set_index('订单付款时间')#设置索引
df2.resample('W',closed='left').sum()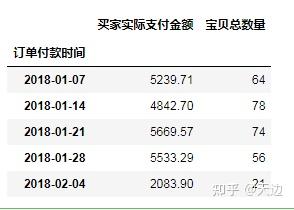
9.3 升采样处理
升采样是由低频率转向高频率,将数据从低频率转向高频率时,就不需要聚合了,将其重采样到日频率,默认会引入缺失值。
例如,原来是按周统计的数据,现在变成按天统计。升采样会涉及到数据的填充,根据的填充的方法不同,填充的数据也就不同。
9.3.1 不填充:控制用NaN代替,使用asfreq方法
9.3.2 用前值填充:用前面的值填充空值,使用ffill方法或者pad方法,为了方便记忆,ffill方法可以使用它的第一个字母“f”代替,代表forward,向前的意思
9.3.3 用后值填充:使用bfill方法,可以使用字母“b”代替,代表back,向后的意思
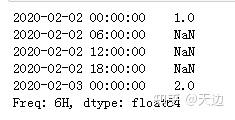
示例:每6个小时进行一次统计
创建一个时间序列,起始日期是‘2020-02-02’,一共2天,每天对应的数值分别是1和2,通过升采样处理为每6个小时统计一次数据,空值以不同的方式填
#空值填充
import pandas as pd
import numpy as np
rng=pd.date_range('20200202',periods=2)
s1=pd.Series(np.arange(1,3),index=rng)
s1_6h_asfreq=s1.resample('6H').asfreq()
print(s1_6h_asfreq)#用空值填充
#用前值填充
import pandas as pd
import numpy as np
rng=pd.date_range('20200202',periods=2)
s1=pd.Series(np.arange(1,3),index=rng)
s1_6h_asfreq=s1.resample('6H').ffill()
print(s1_6h_asfreq)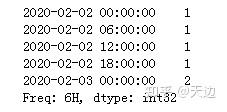
#用后值填充
import pandas as pd
import numpy as np
rng=pd.date_range('20200202',periods=2)
s1=pd.Series(np.arange(1,3),index=rng)
s1_6h_asfreq=s1.resample('6H').bfill()
print(s1_6h_asfreq)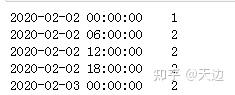
9.4 时间序列汇总(ohlc函数)
ohlc函数返回DataFrame对象,即每组数据的open(开)、high(高)、low(低)、close(关)
示例:统计数据的open、high、low和close值
下面是一组5分钟的时间序列,通过ohlc函数获取该时间序列中每组时间的open、high、low和close值
import pandas as pd
import numpy as np
rng=pd.date_range('2/2/2020',periods=12,freq='T')
s1=pd.Series(np.arange(12),index=rng)
s1.resample('5min').ohlc()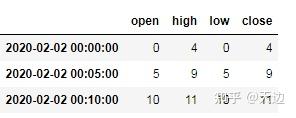
9.5 移动窗口数据计算(rolling函数)
rolling函数语法:
DataFrame.rolling(window,min_periods=None,center=False,win_type=None,on=None,axis=0,closed=None)参数说明:
# window :时间窗口的大小,有两种形式(int或offest),如果使用int,则数值表示计算统计量的观测值的数量,即向前
几个数据;如果是offset类型,则表示时间窗口的大小
# min_periods :每个窗口最少包含的观测值数量,小于这个值的窗口结果为NA。值可以是int,默认值为None。
在offset情况下,默认值为1
# center :把窗口的标签设置为居中。布尔型,默认值为False,居右。
# win_type : 窗口的类型。截取窗的各种函数。字符串类型,默认值为None.
# on : 可选参数。对于DataFrame对象,是指定要计算移动窗口的列,值为列名。
# axis :整型、字符串、默认值为0,即对列进行计算。
# closed :区间的开闭,支持int类型的窗口,对于offset类型,默认值是左开右闭(默认值为right)
# 返回值:为特定操作而生成的窗口的子类。示例1:使用rolling函数计算三天的均值
#首先创建一组淘宝每日销量数据
import pandas as pd
index=pd.date_range('20200201','20200215')
data=[3,6,7,4,2,1,3,8,9,10,12,15,13,22,14]
s1_data=pd.Series(data,index=index)
s1_data
#计算每3天的均值,窗口个数为3
s1_data.rolling(3).mean()
示例2:用当天的数据代表窗口数据
s1_data.rolling(3,min_periods=1).mean()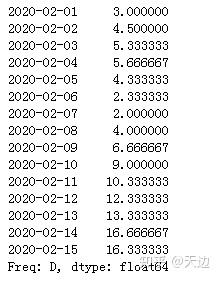
十.综合应用
案例1:Excel多表合并
数据描述:aa 文件夹中有每个月的数据,表结构相同,现在的需求是把它们合并在一张表里
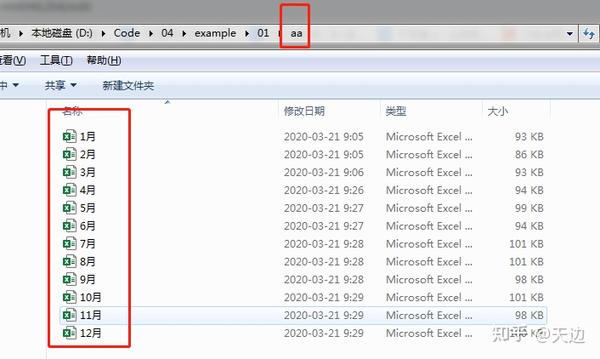

#案例1:Excel多表合并
import pandas as pd
import glob
filearray=[]
filelocation=glob.glob(r'D:\Code\04\example\01\aa\*.xlsx')
#遍历指定目录
for filename in filelocation :
filearray .append(filename)
print(filename)
res=pd.read_excel(filearray[0])#读取第一个Excel文件
#顺序读取Excel文件并进行合并
for i in range(1,len(filearray)):
A=pd.read_excel(filearray[i])
res=pd.concat([res,A],ignore_index=True,sort=False)
print(res.index)
#写入Excel文件,并保存
writer=pd.ExcelWriter(r'D:\Code\04\example\01\all2.xlsx')
res.to_excel(writer,'sheet1',index=False)
writer.save()

案例2:分析股票行情数据
股票数据包括开盘价、收盘价、最高价、最低价、成交量等很多个指标,其中收盘价是当日行情的标准,也是下一个交易日开盘价的依据,可以预测未来证券的市场行情,所以投资者对行情分析时,一般会采用收盘价作为计算依据。
下面使用rolling函数计算某股票20天、50天和200天的收盘价均值并生成走势图。
#股票行情数据
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
aa=r'D:\Code\04\example\02\000001.xlsx'
df=pd.DataFrame(pd.read_excel(aa))
df['date']=pd.to_datetime(df['date'])#将数据转换为日期格式
df=df.set_index('date') #设置dete参数设置为index
df=df[['close']]
df['20天']=np.round(df['close'].rolling(window=20,center=False).mean(),2)