Cassandra读写过程

Cassandra
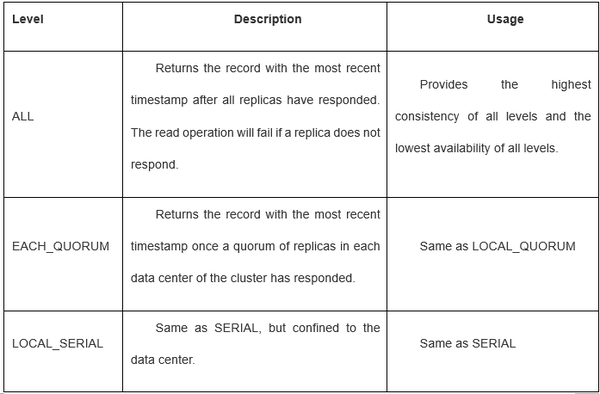
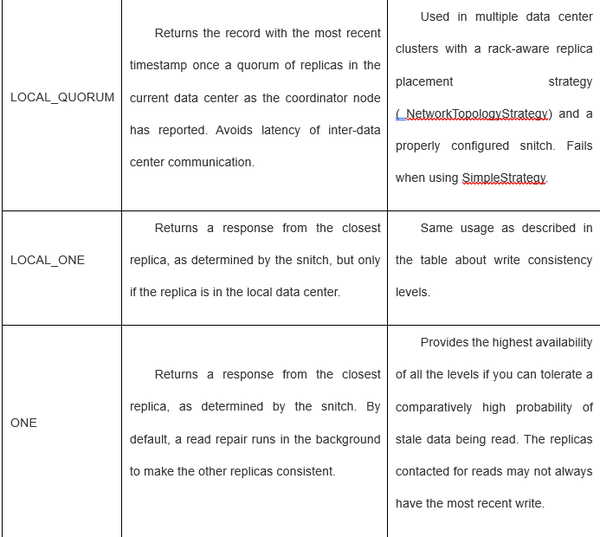
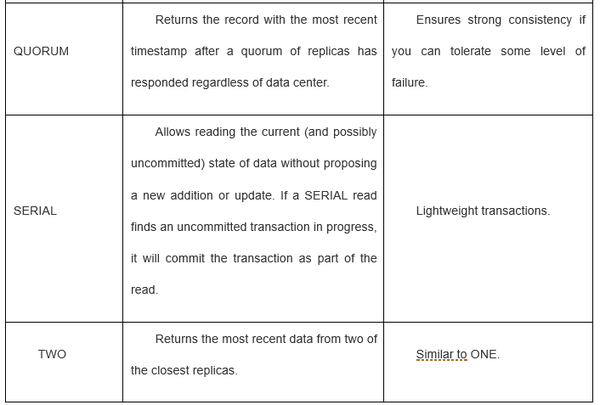
Cassandra一般认为是eventual consistent,属于CAP理论中的 AP 类型。但其实MongoDB和Cassandra都可以设置成strong consistent或者eventual consistent。
Cassandra的读写过程:
1.选择连接的节点
选择连接哪个节点由客户端驱动配置,两个主要的配置是“连接点配置”和“负载均衡策略”。
1.1连接点配置(Contact Points)
连接点设置是一个或多个的list,当在客户端创建集群实例时,驱动按照list顺序连接。如果失败就连下一个,直到成功,就不再连后面的了。
为什么不连所有的连接点,因为每个节点包含所有节点的metadata,只要连上一个,就可以得到集群里所有节点的信息。然后驱动用得到的metadata信息创建一个连接池。这样也不用在连接点设置中添加所有节点。最好的方法是把连接点设置成响应最快的节点。
1.2 负载均衡策略
默认的,一个客户端集群实例管理集群里所有节点的连接,然后对任意客户端请求会随机连接一个节点,当有多个data centers时可能会效率不高。
比如,你有一个集群分布在两个DC上,一个在中国一个在US,如果客户端在中国,就不会想要去连US的节点。
负载均衡策略设置集群对这种情况分配连接的策略。最常用的是DCAwareLoadBalancePolicy,可以对任意客户端请求分配连接到指定集群。
1.3 协调者(Coodinator)
当一个客户端连接一个节点并发出读写请求时,这个节点就是协调者。协调者的作用就像客户端和集群节点之间的代理一样。协调者在基于分片和副本策略的情况下决定环中的哪个节点会得到请求。
2. 写请求
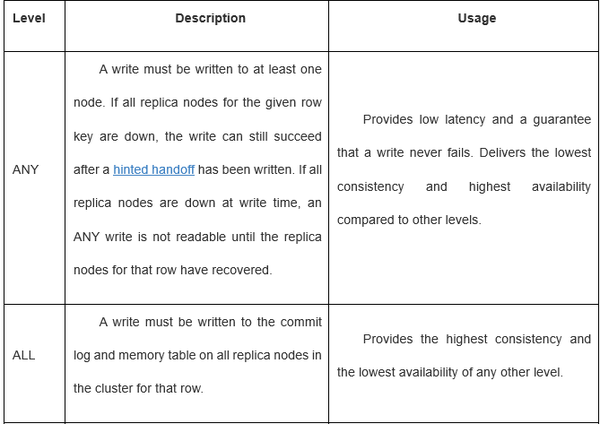
对于节点在同一个本地data center中的协调者,它把写请求发给所有拥有这一行的副本。只要所有副本节点都可用,他们会忽略客户端设置的一致性级别得到写请求。写一致性级别决定了多少副本节点一定要写成功确认才表示这个写请求成功。
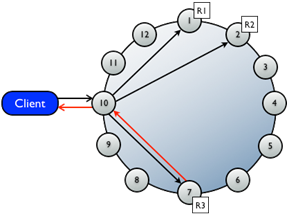
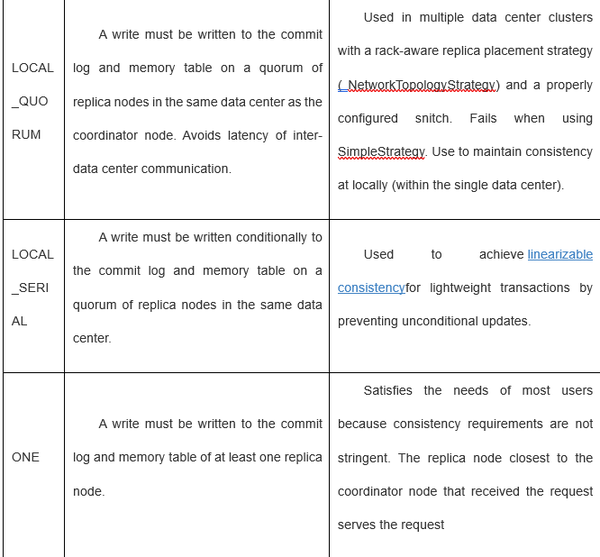
在一个data center中,10个节点,replication factor是3,一个写请求会同时送到3个拥有这行的节点中。如果一致性级别是1,第一个节点完成写请求返回给协调者时,就代表写成功返回给用户。当一个节点写和回应了,就意味着写入了commit log并把变化写到了memtable里。
在多数据中心部署方案中,Cassandra优化写请求通过选择在远端data center中选择一个协调者节点,处理到副本集的请求。
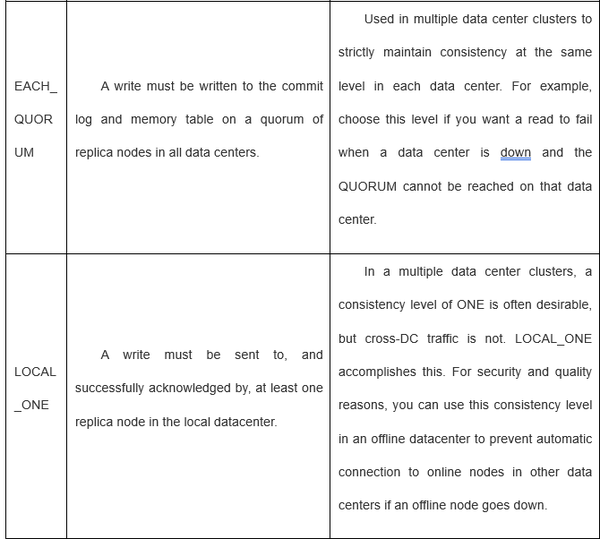
如果用的一致性级别是ONE或者LOCAL_QUORUM,只有当在同一个data center中的节点正确响应时这个写请求才算成功。这样地理位置引起的延迟不会影响客户端请求。(发给DC1的R1,只有DC1上的节点正确响应才行,而不是等DC2。)
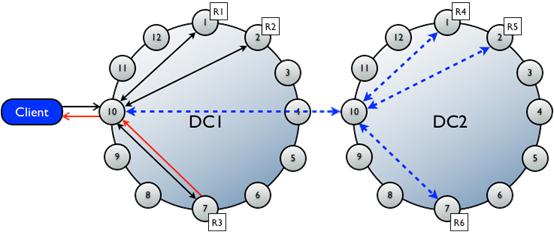

2.1 写失败时,Hinted Handoff
有时,因为硬件,网络,或因为经历长时间的垃圾回收暂停导致的超载,节点无法回应。Hinted handoff可以允许在集群容量减小的情况下继续执行写请求。
在检测到节点down,错过的写请求会在一段时间内存到协调者中,如果在cassandra.yaml文件中开启了hinted handoff。在DataStax5.0后面的版本中,hint存在一个hints的目录中。Hint包含了,down节点的target ID,一个Hint
ID(即是一个time UUID),一个message ID(DataStax Enterprise的版本),和数据(blob存储)。Hints每10秒写一次磁盘,避免hints过时。当gossip发现节点恢复时,协调者把保存的写请求线索里的数据写进去,然后删除hint文件。如果一个节点down掉3个小时以上(默认值),协调者不再写入新的hints。
协调者会每10分钟检查写hints,可能由于短时间的停电超时以至于gossip没有监测到。如果一个副本超载或者不可用,failure detector还不会把节点标记成down,直到大多数或全部写到那个节点时超时触发失败(默认10秒)。协调者会返回一个TimeOutException异常,写失败了但是hint会被存下来。如果几个节点同时断电,会造成协调者大量的内存压力。协调者追踪有多少hints,如果实在太多,协调者拒绝写,并抛出OverloadedException。
coordinator挂掉怎么办?
一致性级别会影响hints是否会被写入和后续写请求会不会失败。一个集群有两个节点A和B,RF=1,CL=ONE,每一个行都只存在一个节点中。假设A是协调者,但是在row K写入前down,这种情况,不会满足一致性,因为A是协调者,它不能存hint了。B也不能写数据,因为没有接受到协调者发来的数据也没有hint存下来。协调者检查在线副本数量,如果客户端指定的一致性不能满足不会尝试写hint。一个hinted handoff 错误发生,返回UnavailableException异常。写请求失败,hint没有被写入。
通常来说,建议有集群有足够的节点,和足够的RF避免写请求失败。比如一个集群有3个节点A,B,C,RF=2。当row K写入协调者A时,即使down,CL=ONE或者CL=QUORUM也是可以满足的。因为A和B都会接受数据,所以一致性满足。A节点会存储C的hint当C恢复时写入。
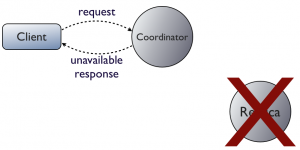
在非分布式架构中,客户端请求并得到回复如图。
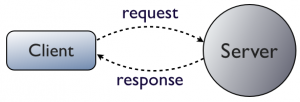
如果在服务器回复前挂掉了,客户端不知道发生了什么,只有当服务器重新上线后重发请求
客户端可能会连接集群里的任一节点,不管它是不是要读数据的那个节点,叫协调者。它负责路由客户端请求到合适的副本集。
如果协调者在途中挂了,和非分布式架构一样,客户端也只能重试。不同的是客户端可以 立马连接集群里别的节点。
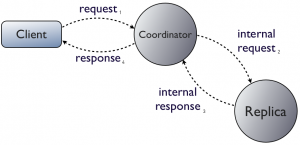
如果是副本挂了,协调者没有。有两种情况,第一种是协调者failure detector在请求之前知道副本挂了,所以它都不会再把请求路由到那个节点上面。相反,它立刻回复客户端一个UnavilableException。这是Cassandra唯一会写失败的时候(当太少的副本集在线时,协调者收到了请求,这是唯一会写失败的时候)。
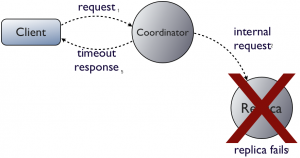
如果协调者收到了请求,在发送给副本的时候挂了,协调者返回一个TimedOutException。读写更新这些超时时间可以配置。超时不是失败。协调者把这个操作更新在本地,然后记录在hint里,当副本重新上线时再发给它。这是强制更新后处理(post-update)
3. 读请求
由客户端决定一个读请求送到多少个副本当中。协调者把这些请求送到当前回应最快的副本中。如果有多个节点连接,来自各个副本的数据将在内存中比较看是否一致。如果不一致,那个有最新timestamp数据的副本请求,会被当作结果送给客户端。
为了保证所有副本有最新版本频繁读过的数据,协调者会在后台联系比较那些拥有相同row的副本。如果副本不一致,协调者发布写请求到过时的副本中更新成最新的数据。
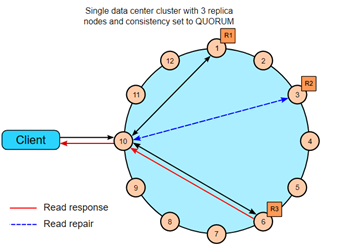
在单data center中,一致性级别是QUORUM,副本因子3,需要3个副本中的2个都回应读请求。如果读出的数据不一样,副本中有最新版本的作为结果返回。在图中,R2和前两个节点检查一致性,如果需要,一个读修复会发送到过时的副本中。
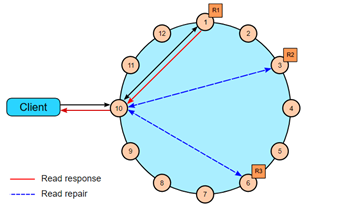
RF=3,一致性级别1,最近的副本返回读请求。图中,一个读修复可能会被发起,基于table中的设置read_repair_chance。
2dc,RF=3,CL=QUORUM,4个副本需要回应读请求。这4个副本可以来自任意的dc中。在图中,剩下的副本会和返回的4个副本作比较,如果必要会读修复。
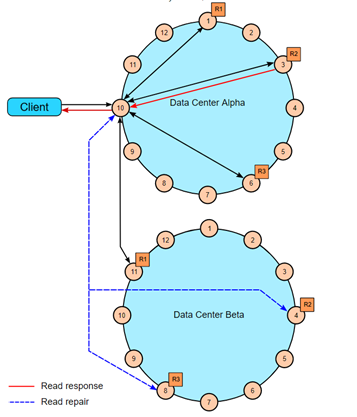
DC=2,CL=LOCAL_QUORUM,RF=3,任意一个DC中的2个副本必须要回应请求。剩余的所有节点会检查一致性。
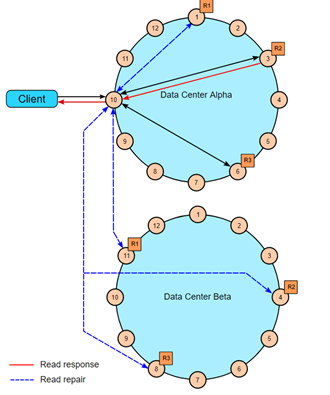
通过推理重试来快速读保护。
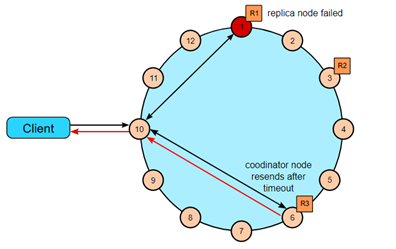
快速读保护允许Cassandra在原来选择的副本down掉或者回应时间太长时,继续发送读请求。如果配置了speculative_retry属性,当原来的副本超出相应时间时,协调者会尝试把读请求发给别的副本。



读