


Mac下使用python

这学期选修的关于内容安全和数据挖掘的课程,于是作者本人终于开始接触python(大三才开始学python的我错了,不要打我)
关于爬虫
百度官方解释:网络爬虫(又被称为网页蜘蛛,网络机器人,在FOAF社区中间,更经常的称为网页追逐者),是一种按照一定的规则,自动地抓取 万维网 信息的程序或者脚本。另外一些不常使用的名字还有蚂蚁、自动索引、模拟程序或者蠕虫。
关于python
Python是纯粹的自由软件, 源代码和解释器CPython遵循 GPL(GNU General Public License)协议。Python语法简洁清晰,特色之一是强制用空白符(white space)作为语句缩进。
关于python的安装
ps:mac系统自带python,不过版本不超过3,所以建议重新安装
检查python版本的方法:
打开终端,直接输入python,就会显示python的版本
安装python的方法:
mac版指路:
win版指路:
如何运行python
由于作者本人用的是mac系统,这里就说一下如何在mac OX中运行python(至于如何在win下我就不多说了,目前win对我来说就只有word和微软家的vs还可以用一用)主要有以下三种方法:
(1)安装一个sublime,方便快捷
(2)使用mac自带的终端
(3)安装一个PyCharm
方法一指路:
如何安装sublime:
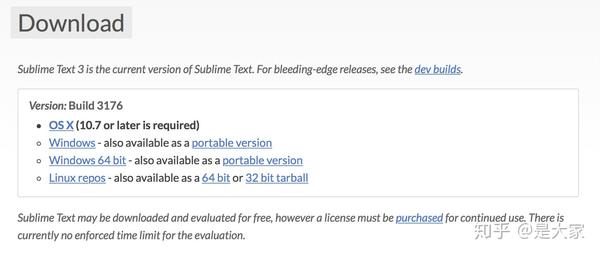
sublime下载网址: A sophisticated text editor for code, markup and prose
选择适合你的版本下载

如何破解:
sublime text 安装以及配置 | Celia‘s blog
如何配置python3:
打开sublime text,工具——》编译系统——〉编译新系统
使用Sublime Text 开发Python如何配置环境(mac)
编译:command+B
方法二:
打开终端,利用cd找到py文件所在位置,然后输入python3 文件名称+回车
方法三指路:
如何安装PyCharm:
直接给下载网址别的就不废话了: PyCharm: Python IDE for Professional Developers by JetBrains
如何破解PyCharm:
这个网上一堆,自己动手丰衣足食。
Ps:虽然安装了PyCharm,但是目前我还没有怎么用过,感觉有点重量级,对于目前我觉得Mac的终端就很好用。。。。
如何用python进行简单的页面抓取
事例:
url:
此链接为电子工业出版社的官方链接
任务:
对指定的链接进行数据抓取
提前准备:
(1)安装pip:打开终端,输入:sudo apt - get install python3 - pip
(2)安装requests:打开终端,输入:sudo pip3 install requests
代码:
import requests
urls_dict = {
'电子工业出版社':'http://www.phei.com.cn',
'在线资源':'http://www.phei.com.cn/module/zygl/zxzyindex.jsp',
'xyz':'www.phei.com.cn',
'网上书店1':
'http://www.phei.com.cn/module/goods/wssd_index.jsp',
'网上书店2':
'http://www.phei.com.cn/module/goods/wssd_index.jsp'
urls_lst = [
('电子工业出版社','http://www.phei.com.cn/'),
('在线资源','http://www.phei.com.cn/module/zygl/.jsp'),
('xyz','www.phei.com.cn'),
('网上书店1',
'http://www.phei.com.cn/module/goods/wssd_index.jsp'),
('网上书店2',
'http://www.phei.com.cn/module/goods/wssd_index.jsp'),
crawled_urls_for_dict = set()
for ind,name in enumerate(urls_dict.keys()):
name_url = urls_dict[name]
if name_url in crawled_urls_for_dict:
print(ind,name,'已经抓取过了')
else:
try:
resp = requests.get(name_url)
except Exception as e:
print(ind,name,':',str(e)[0:50])
continue
content = resp.text
crawled_urls_for_dict.add(name_url)
with open('bydict_'+name+'.html','w',encoding='utf8') as f:
f.write(content)
print("抓取完成:{}{},内容长度为{}".format(ind,name,len(content)))
for u in crawled_urls_for_dict:
print(u)
print('-'*60)
crawled_urls_for_list = set()
for ind,tup in enumerate(urls_lst):
name = tup[0]
name_url = tup[1]
if name_url in crawled_urls_for_list:
print(ind,name,"已经抓取过了")
else:
try:
resp = requests.get(name_url)
except Exception as e:
print(ind,name,':',str(e)[0:50])
continue
content = resp.text
crawled_urls_for_list.add(name_url)
with open('bylist_'+name+'.html','w',encoding='utf8') as f: