|
|
|
相关文章推荐

|
19924827915 · 豆瓣查发言记录方法。(刘宇宁)· 2 月前 · |
|
|
聪明伶俐的跑步鞋 · 网站内搜索结果|大和房屋集团官网· 1 年前 · |
|
|
纯真的鼠标垫 · 一吸沙船撞广东西江铁路大桥导致大桥横梁受损 ...· 1 年前 · |
|
|
苦闷的黄豆 · PHP混淆zym解密-CSDN博客· 2 年前 · |

导航
ByteHouse 企业版
搜索目录或文档标题
用户指南
连接集群
数据管理
数据查询
SQL 参考
函数
- 文档首页 /
- ByteHouse 企业版
新建库表
更新时间: 2023.05.26 10:25:36
文档反馈
创建数据库 #
用户可以根据业务场景创建多个数据库,同时在创建表时也需要选择目标数据库。因此如果当前集群中未存在数据库时,请先进行创建。具体操作步骤如下:
-
登录 ByteHouse 企业版控制台 。
-
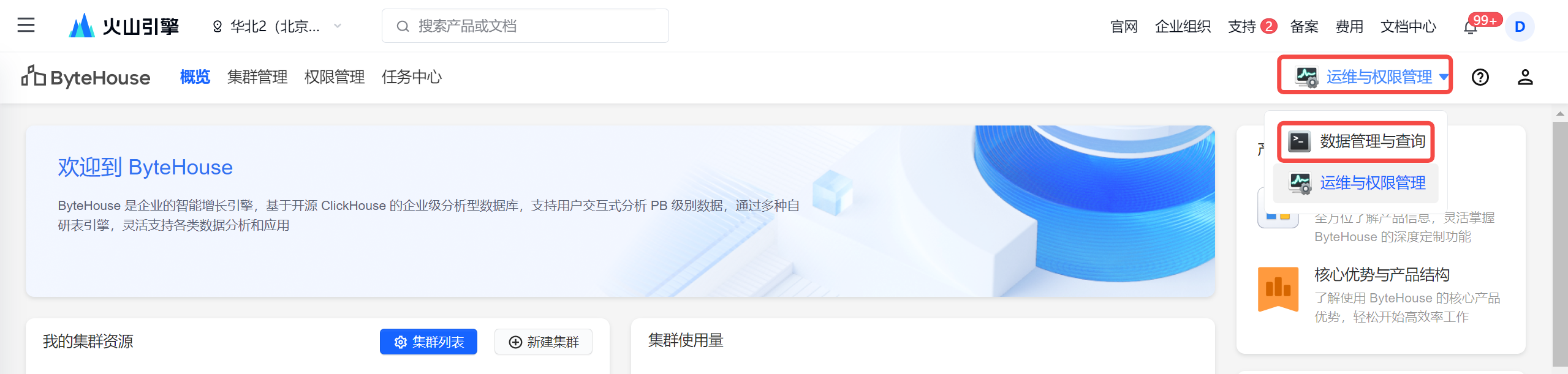
单击右上角 运维与权限管理 > 数据管理与查询 按钮,进入数据管理界面。
-
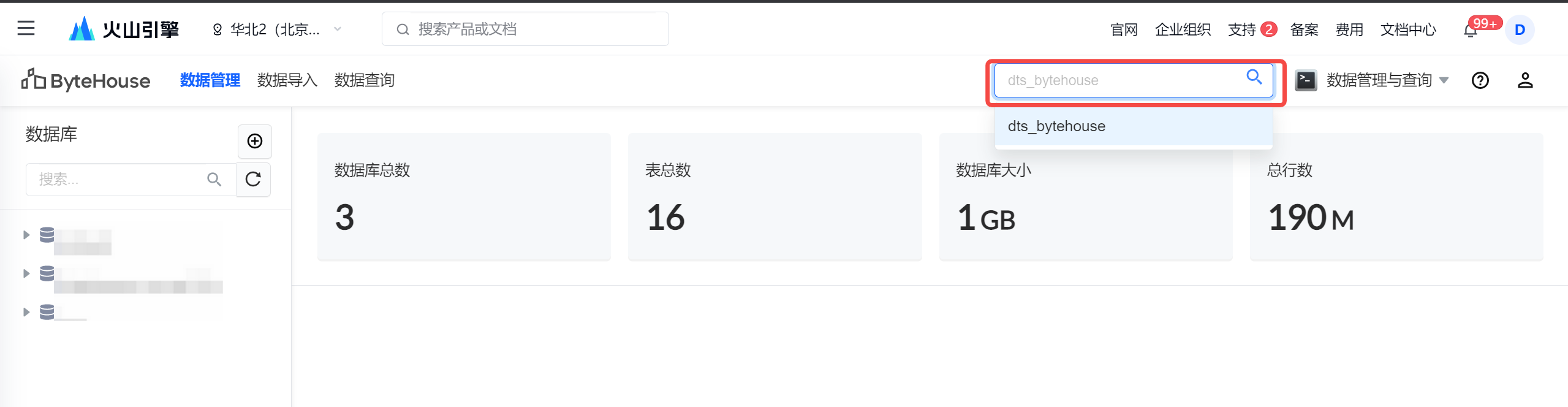
在右上角下拉选择已创建成功的集群信息。集群创建详见 创建集群
-
单击左侧目录树上 新建 按钮
 ,选择
新建数据库
。
,选择
新建数据库
。
-
填写数据库基本信息,如下图所示。其中库名命名规则如下:
- 不支持以字母或下划线开头,支持数字,字母及下划线。
- 不能使用关键字: 'system', 'default' or 'admin'。
- 最大长度不超过 64 字符。
-
单击 创建 按钮,完成数据库创建。
创建数据表 #
-
在对应集群下,单击选择已创建成功的数据库名称。
-
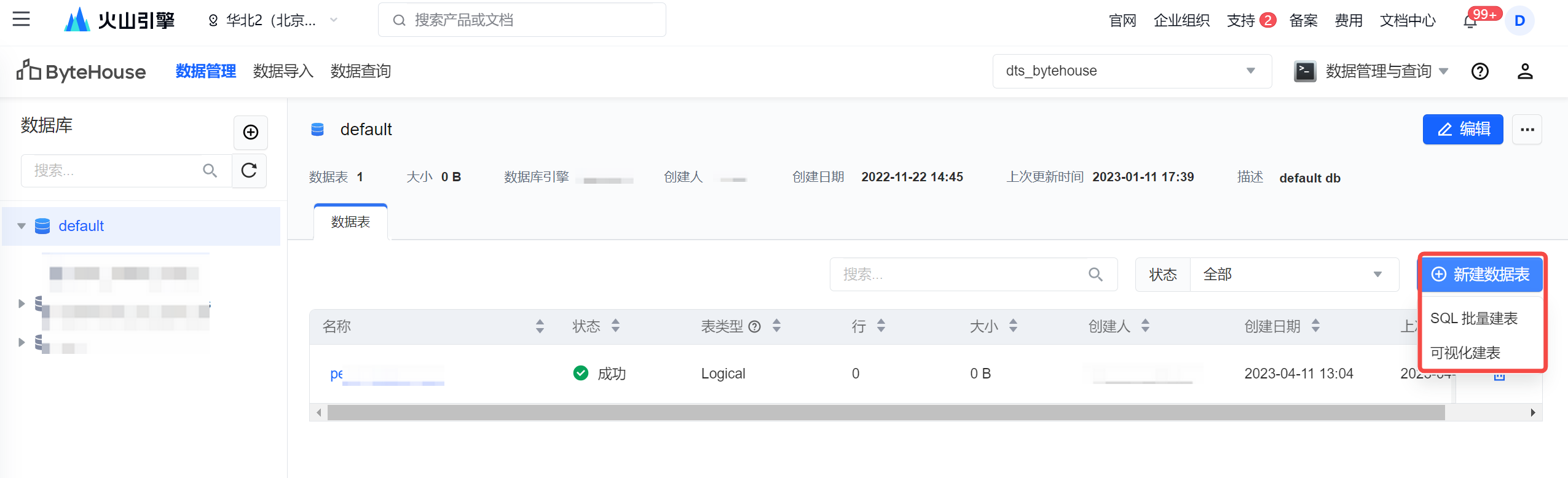
单击 新建数据表 按钮,您可通过 SQL 批量建表 和 可视化建表 ,两种方式来新建数据表。
-
SQL 批量建表
在编辑框中输入相应建表语句,详见 SQL 语法 ,在编辑框中,您还可以执行以下操作:操作 说明 下载 SQL 将编辑器中编辑的 SQL 语句,下载至本地保存。 上传 SQL 将需执行的 SQL 语句,以本地文件的形式,通过上传方式,上传至编辑器中批量执行。 SQL 格式化 将书写的 SQL 进行格式化操作,增加语句可读性。 复制 SQL 可对写好的 SQL 语句进行复制操作。 清除所有 SQL 将编辑器中书写好的所有 SQL 语句,进行清除。 -
可视化建表
进入建表页面后填写如下建表信息,此时可以通过手动输入建表字段信息完成建表,也可以通过右侧的 本地表 或 分布式表 编辑区,以 SQL 方式,快速导入建表配置。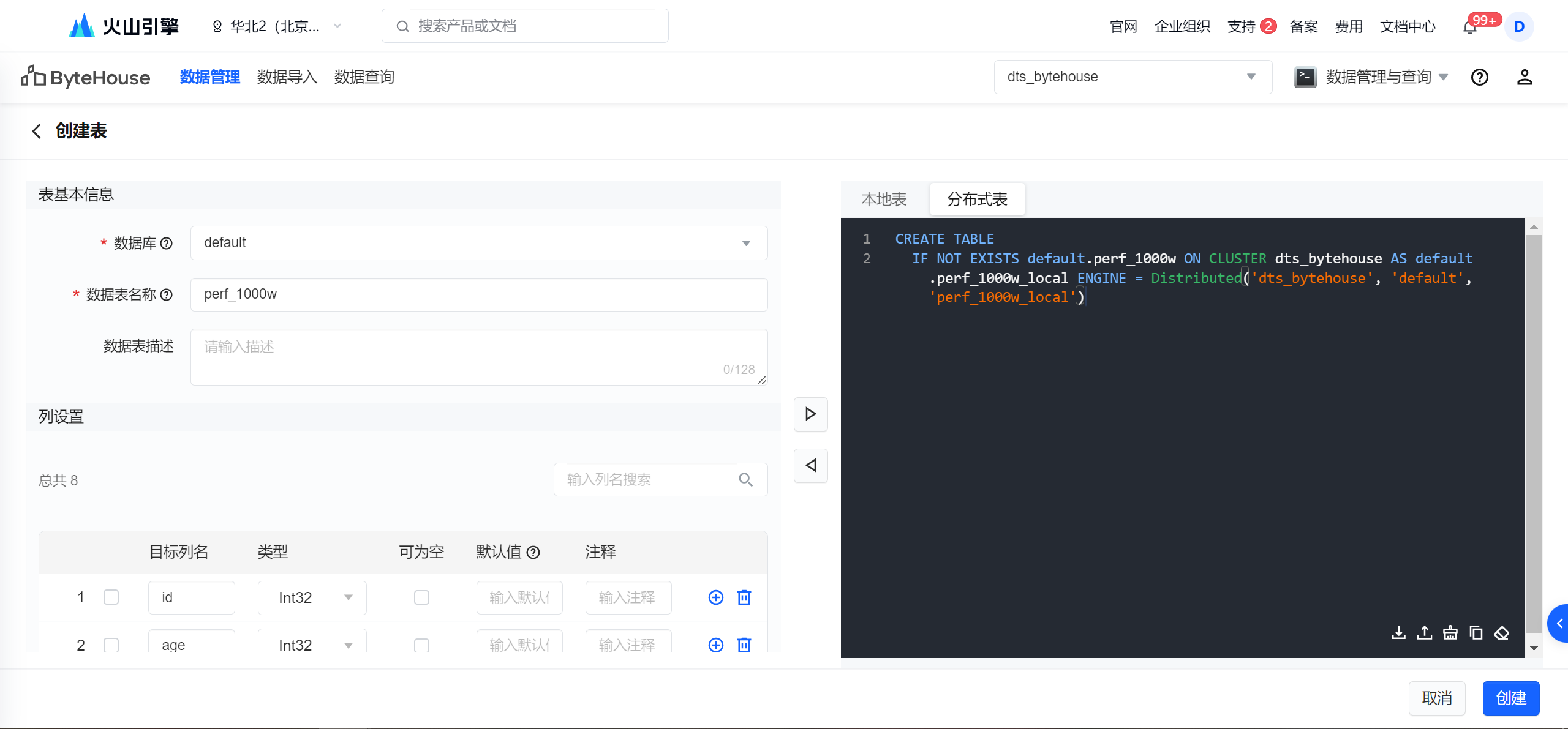
-
-
在窗口左侧,可配置表的列信息:
-
其中,“类型”请参考 ClickHouse 社区支持的类型 。
-
“可为空”即为 ClickHouse 的
Nullable属性。
-
-
在窗口右侧,可以配置表的建表字段。对于各个建表的字段解释如下:
注意
排序键,分区键,主键,采样键,唯一键均不能为空。
-
排序键(ORDER BY):
- ByteHouse 为了提高查询性能, 存储数据时会根据排序索引顺序存储。
- 排序键可以不唯一。但是不能为 Nullable。
- 建议选择 1-3 个经常作为过滤条件的字段作为排序键,使用频率越高,对应顺序越优先。当优先级近似时,选择基数较小的排序索引位于更优先的顺序。
- 分区字段不必为排序索引。
-
主键(PRIMARY KEY):
- 在索引文件(.idx)记录的就是行与主键的对应关系。它默认和排序索引是一致的,通常也不需要额外设置。
- 主键不能包含 Nullable 值。一个数据表只能选择一个主键。
-
抽样字段(SAMPLE BY):
- 默认取第一个主键字段,用于在查询抽样时使用。请参考社区 Sample by 语法。
- 必须是排序索引 / 主键之一。
-
分区字段(PARTITION BY):
-
可选类型:
- 时间类型(Date/DateTime),选择时间类型为最佳实践,仅当选择时间分区时才可设置 TTL(数据生命周期)。分区粒度可选 DAY(按日),HOUR(按小时),MONTH(按月)。
- 数字类型(Int / UInt / Float)
- 字符串类型(String)
- 如果无需进行分区时,可以不选分区键。
- 分区字段不可以为 Nullable
-
可选类型:
注意
建议 单天数据量 > 100 亿才考虑按小时分区,或数据量过小时可选按月分区,否则建议采用按日分区。
-
TTL:
- 设置数据生命周期,生效粒度为表级别。
- 数据保留时间是以“分区字段”作为基础进行计算,因此对于非时间分区的表将无法设置 TTL,系统将强制修改为永久保留。
-
表引擎:
- 默认为 HaMergeTree,和社区的 ReplicatedMergeTree 引擎基本兼容。
- 如果需要根据唯一键去重功能,请选择 HaUniqueMergeTree,使用方式参考:(选此引擎后,才可以选择唯一键、生效范围、版本字段)
-
唯一键:选取字段作为数据去重 (upsert) 的判断标准,可支持多个。
-
唯一键( 必填 ):每个表只能有一个唯一键,支持最多3个字段构成组合键。如果超过3个,用户可以自行计算一个所有唯一字段的64位哈希值,并用该哈希字段作为唯一键(如果是有符号哈希值,CH需要使用Int64类型)。
-
唯一键作用范围( 必填 ):如果是【分区粒度唯一】,保证唯一键在分区内的唯一性。如果是【表粒度唯一】,保证唯一键在表内的唯一性。表粒度唯一有额外的写入开销,建议优先使用分区粒度唯一。
-
版本字段(选填):写入相同唯一键的多条数据时,默认保留最新写入的数据。如果指定了版本字段,将保留版本最大的数据。如果使用表粒度唯一,可以额外使用分区表达式作为版本字段,即相同唯一键保留最新分区的数据。
-
-
排序键(ORDER BY):
-
填写完成后可以单击右下角的 创建 提交建表任务,界面右侧会展示刚创建的表,若无报错信息,则表示创建成功。
同步数据表 #
如果通过 Client,JDBC 或其他非 GUI 的方式建表,也会每相隔 5 分钟的同步到 GUI 上。以下表引擎会被同步:
-
关联了 Distrbuted 表 的 HaMergeTree 表或 HaUniqueMergeTree 表,会被同步为“逻辑表”,该类型的表和 GUI 创建的表(同 2.1.2)无异,也是 ByteHouse 的建表最佳实践,因此,可以正常在 GUI 上进行改表,删除分区,创建导入任务等操作。
-
没有关联 Distrbuted 表的 HaMergeTree 表或 HaUniqueMergeTree 表,或社区的其他 MergeTree 家族表 (如 MergeTree,DuplicatedMergeTree 等)由于不符合 ByteHouse 建表的最佳实践,会被同步为“自定义表”。仅会在 GUI 上展示 / 可被查询,不可进行改表,删除分区,创建导入任务等操作。
-
MySQL、S3、Hive 等 Integration 引擎 的表,会被同步为“外表”。该类表仅会在 GUI 上展示 / 可被查询,不可进行改表,删除分区,创建导入任务等操作。
Integration 引擎中,Kafka 引擎,RabbitMQ 引擎的表因对其查询会导致丢数,暂时不会被同步。
推荐文章
|
|
19924827915 · 豆瓣查发言记录方法。(刘宇宁) 2 月前 |
|
|
聪明伶俐的跑步鞋 · 网站内搜索结果|大和房屋集团官网 1 年前 |
|
|
苦闷的黄豆 · PHP混淆zym解密-CSDN博客 2 年前 |