


如何使用python进行数据分析?


目录
- 一维数据分析
- NumPy一维数组array
- Pandas一维数组Series
- 二维数据分析
- NumPy二维数组array
- Pandas二维数组DataFrame(数据框)
- 数据查询
- 案例:医院销售数据分析
- 数据分析步骤
- 案例分析:医院销售数据分析
- 明确问题
- 理解数据
- 数据清洗
- 数据分析或构建模型
- 数据可视化
一维数据分析
- NumPy中的一维数据结构叫数组array,Pandas中的一维数据结构叫Series,Series建立在NumPy的基础上,所以Series相比较于array功能更多。
- 导入两种包的方法,如下图:


1.NumPy一维数组array
首先定义一个一维数组array:


可以看出一维数组和列表很相似,其序号也是从0开始,比如元素2的序号就是0。
在一维数组array中我们可以进行四种操作:
(1)查询元素:和列表相同,使用引用序号的方式进行查询。


(2)切片访问:访问一维数组中连续的片段,也是引用序号如a[1:3], 注意序号是前闭后开的。


(3)循环访问:使用for循环进行访问,for i in a:
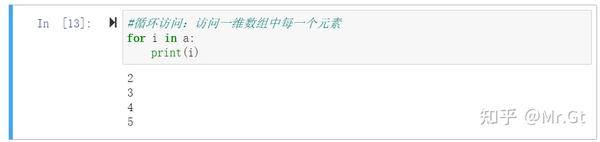

这里可以看出遍历每一种元素并打印出和直接打印一维数组是不同的,前者会单独输出每一个元素,后者直接打印出一维数组(里面包含每一个元素)。
(4)数据类型查看:dtype


可知我们设置的变量a是存放了整型数据的数组。
NumPy的一维数组与列表的区别
- 统计功能:numpy中提供了很多方便统计计算的功能:平均值mean(),标准差std()
- 向量化计算:这是numpy数组的计算功能
- 向量相加
- 乘以标量
- 相比较于列表,array中的数据必须是同一种数据类型,而列表可以包含不同数据类型的数据
2.Pandas一维数组Series
Pandas一维数组与NumPy一维数组的最大区别在于:Series拥有索引的概念,在定义时可以指定索引。
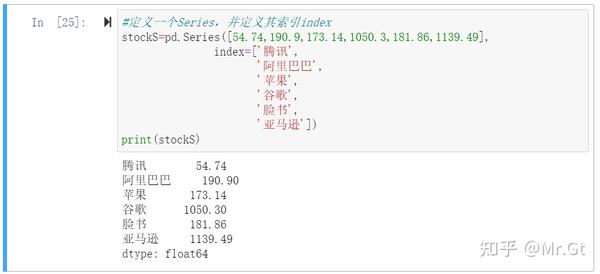

设置索引是为了方便我们后续通过索引访问Series中的数据。
定义好一维数组Series后可以使用describe函数对一维数组中的数据进行描述统计:
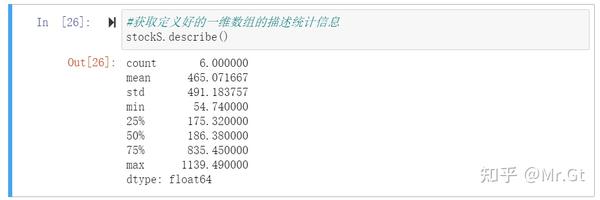

这里描述统计信息包括:计数、平均数、标准差、最小值、下四分位数、中位数、上四分位数和最大值。
如何获取Series中的元素?
- iloc属性:用于根据位置获取元素


- loc属性:用于根据索引获取元素


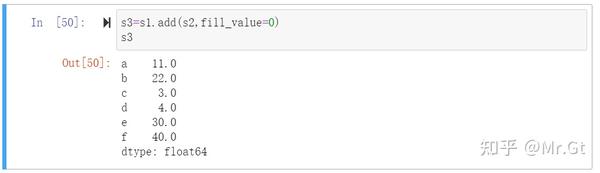
如何处理空值?
首先设置一个包含空值的一维数组s3:
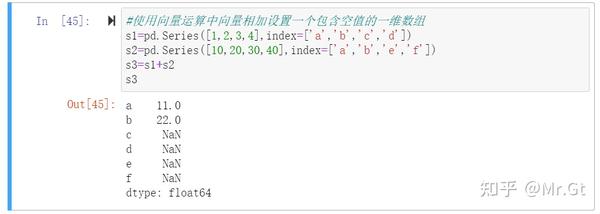

可是使用两种方法对缺失值进行处理:
- 删除缺失值:直接使用dropna对数组s3中的缺失值进行删除处理


- 填充缺失值:使用其他值对缺失值进行填充(比如0)

二维数据分析
- 二维数组类似Excel中的表格,有行和列两个维度
- 在NumPy中使用array(数组)创建二维数组
- 在Pandas中使用DataFrame(数据框)创建二维数组
- DataFrame相比较于array功能更多,处理数据更加方便
1.NumPy二维数组array
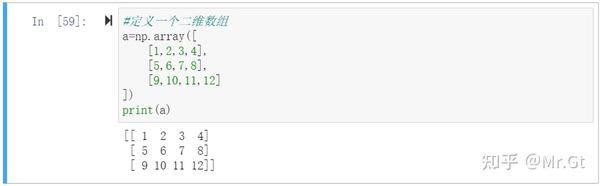
首先定义一个二维数组array

如何查询二维数组中的元素?
- 查询单个元素:使用行号和列号来定位元素, 注意二维数组的行列号都是从0开始的


- 获取某行所有元素:使用行号和“:”来定位某一行


- 获取某列所有元素:使用“:”和列号来定位某一列


数轴参数的概念
如果不指定数轴参数,计算时会统计二维数组array中所有的元素,但是在数据分析中我们通常想要指定行或列进行计算,这是就涉及到数轴参数的概念。
- 按行进行计算统计,使用数轴参数axis=1


- 按列进行计算统计,使用数轴参数axis=0


2.Pandas二维数组DataFrame(数据框)
Pandas二维数组DataFrame与NumPy二维数组array最大的不同在于,后者只能存放同一类型数据,而前者却可以存储不同数据类型的数据,因此有两大优点:
- DataFrame可以存储不同数据类型的数据,更加符合现实工作中我们所拿到的数据情况(每列之间的数据类型不一定相同,可能是字符串、数值或其他数据类型)。
- DataFrame具有类似于一维数组Series的索引功能,这使得Pandas数据框很多容易表达出我们常见的表格数据。
如何创建一个数据框?
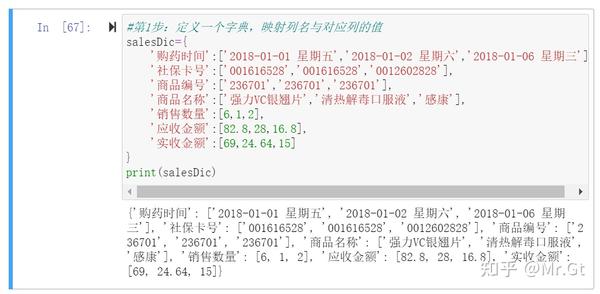
- 第1步:定义一个字典,映射列名与对应的值

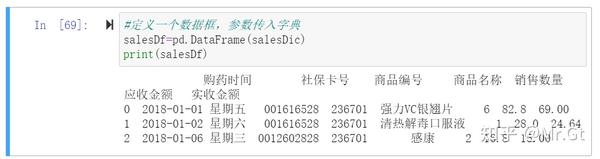
- 第2步:定义数据框,参数传入字典

使用有序字典来定义有序数据框
有序字典的概念见链接中数据结构:
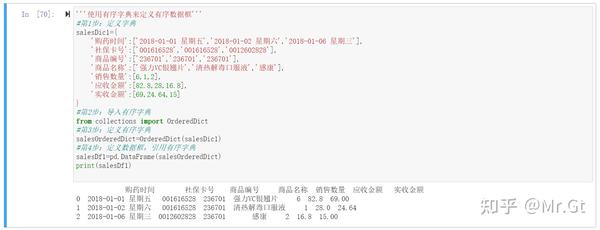

使用数据框来进行描述统计


可见在数据框中进行描述统计计算是直接针对每一列进行的,不像在NumPy二维数组array中需要选择数轴参数才能进行行或列的计算。
另外可以看到,对数值类的数据求和是可以得到算数计算结果的(如“应收金额”、“销售数量”等),而对于字符串类的数据求和是会将所有字符串串联起来(如“购药时间”、“社保卡号”等)。
如何获取DataFrame中的元素?
与Series相同,可以通过iloc引用位置进行获取,也可以使用loc引用索引进行获取。
- 使用iloc属性根据位置查询值
- 查询单个元素


- 获取某一行


- 获取某一列


- 使用loc属性根据索引查询值
- 查询单个元素


- 获取某一行


- 获取某一列


3.数据查询
前面说到了在数据框中如何查询某一列的数据,在实际工作中我们通常需要一次查询多个列,这种情况如何处理呢?
如何查询多列数据?
对于查询多个列的方式,我们有两种方法:
- 引用列名列表: 可以不使用属性即可完成查询
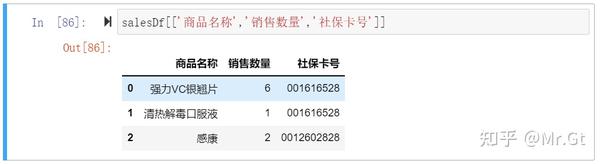

图中,我们将需要查询的列名作为元素放在列表里,然后将整个列表作为参数进行查询。
- 使用切片功能:指定范围, 使用切片时需要使用loc属性
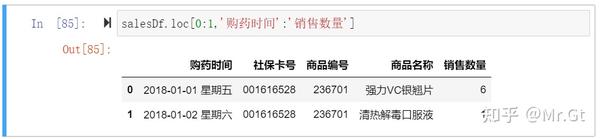

其中0:1表示第1行到第2行数据,‘购药时间’:'销售数量'指查询从“购药时间”列到“销售数量”列。
从中可以看出,当我们仅需要一次性查询单独几个不相连的列时,选择第一种方法,当我们需要一次性查询多个相连的列时,选择第二种方法。
如何通过条件判断筛选查询符合我们要求的数据?
- 构建查询条件
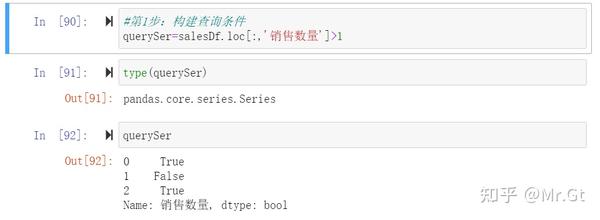

可以看到对于“销售数量”这一列,如果符合查询条件,则反回True,否则返回False
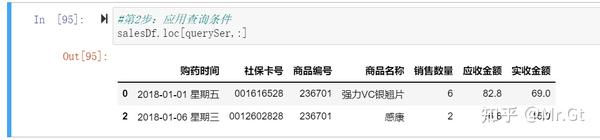
- 应用查询条件


其中‘商品编号’:‘销售数量’指显示范围,如果参数为":"则显示所有列,如图:

如何使用数据框进行描述统计分析?
- 第1步:读取Excel数据


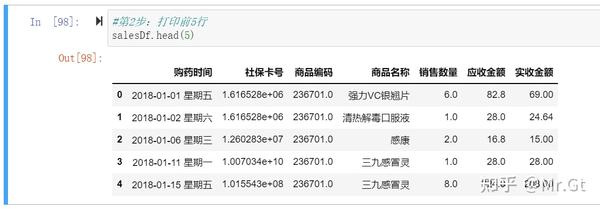
- 第2步:打印前5行进行预览(可以随意打印多少行都行),使用salesDf.head()

- 第3步:查看数据类型,使用dtype


- 第4步:查看数据集的行列数,使用shape


表示行数6578行,列数7列
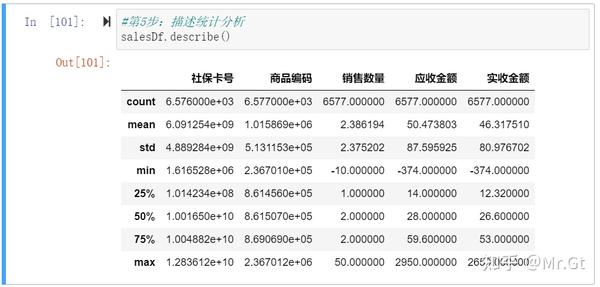
- 第5步:进行每一列的描述统计分析,使用describe

案例:医院销售数据分析
1.数据分析步骤
- 明确问题
- 理解数据
- 数据清洗
- 数据分析或构建模型
- 数据可视化
数据分析步骤我们在上一个专栏里就讲过:
Python和Excel一样都是数据分析的工具,而在解决问题时,最重要的是选择合适的工具进行分析,从明确问题开始,到最后的问题解决与呈现,这才是作为数据分析师应该重点掌握的东西,要知道的是数据分析师不是工具使用师,而是问题解决师。
2.案例分析:医院销售数据分析
Excel数据集:
- 明确问题
这里针对原始数据集提出几个问题指标:
(1)月均消费次数
(2)月均消费金额
(3)客单价
(4)消费趋势
- 理解数据
(1)导入第三方库Pandas,并导入Excel数据,构建数据框


上图第三行代码表示:以字符串类型(dtype=str)读取该Excel文件的第1页(sheet_name='Sheet1')。
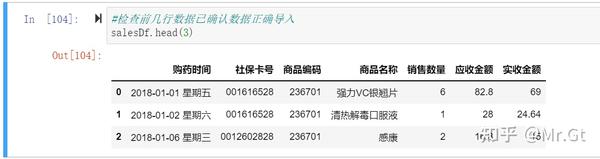
(2)检查前几行数据已确认数据正确导入

(3)检查导入数据集的整体行列数,确保导入正确没有丢失数据



可见Excel中也是6578行,7列数据,说明数据导入完整。
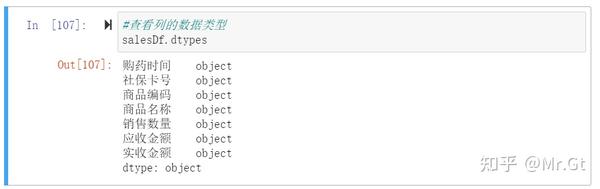
(4)查看列的数据类型,了解每一列数据数据类型是什么(这里我们曾经说过,如果数据类型不对会影响描述统计分析)

- 数据清洗
(1)选择子集
这里可以使用切片的方式选择子集,如图:
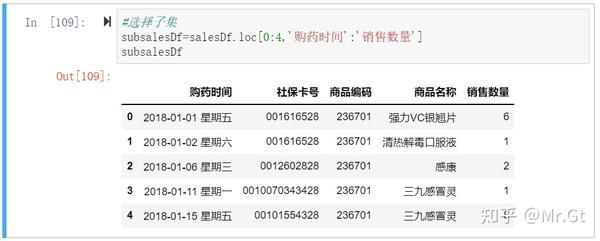

这里只是做个示例,实际上本次案例需要全部列的数据,所以不需要选择子集,我们仍然使用数据框salesDf。
(2)列名重命名
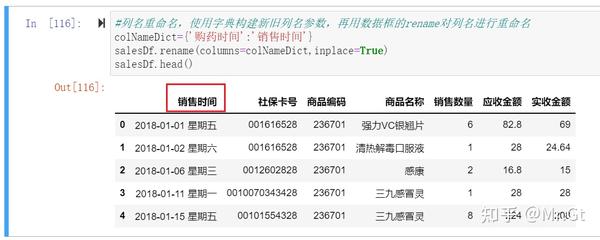

这里需要说明一下:rename()中的参数inplace=True表示覆盖重命名前的数据框,相当于保存,如果为inplace=False则表示另存一个数据框,不覆盖重命名前的数据框,相当于另存为,默认的inplace是False。
(3)缺失数据处理
缺失数据处理一般有两种方法:
第一种:删除缺失数据(缺失数据较少的情况)
第二种:建立模型进行插值(缺失数据较多的情况)
第二种方法将会在后续机器学习结合算法一起讲解,这里由于缺失数据较少,使用第一种方法。


这里说明一下:删除使用dropna,其后面的第一个参数subset的意义是用于存放指定列的列表,第二个参数how表示如何删除数据,这里'any'表示在给定的任意一列中有缺失值就进行删除操作。
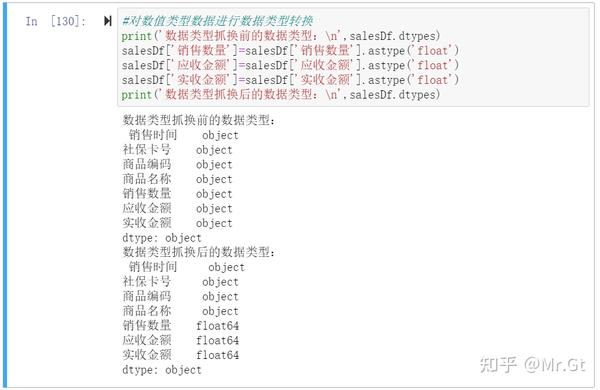
(4)数据类型转换(astype)
前面为了保证导入数据的正确性,我们使用字符串格式导入了所有列的数据,这里我们就要针对每一列的实际数据类型进行数据类型转换。
首先对数值类型数据进行数据类型转换:

接着单独时间类型数据进行数据类型转换:
我们观察到,这里的时间格式为“2018-01-01 星期五”,在Excel中我们可以使用分列的功能对该列数据进行类型转换,这里我们也可以使用类似的方式,使用空格作为分列依据,将原始数据分列成2018-01-01和星期五两列,如下图:

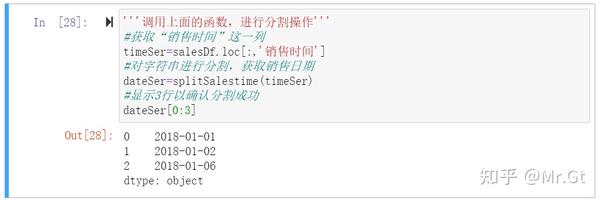
那么类比到数据框中对某一列数据进行分割,为了方便操作,我们可以定义一个函数,然后之后在进行分割时调用这个函数就可以实现分割操作了,如下图:



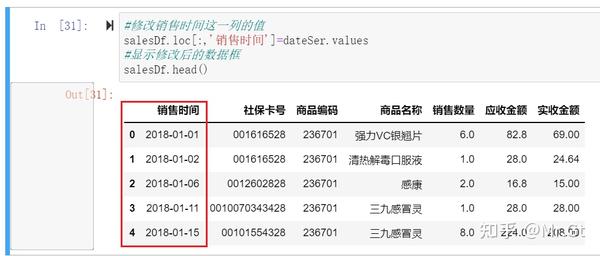
最后将一维数组的值赋值到数据框的"销售时间"这一列中,完成分割处理:

完成分割处理后,“销售时间”这一列仍然是字符串格式,那么如何将字符串转换成日期格式呢?这里我们 使用to_datetime将字符串格式改为日期格式:
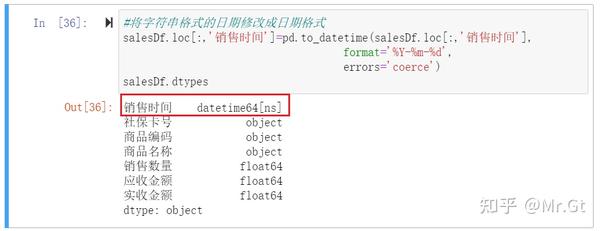

这里说明一下:errors='coerce'表示如果原始数据不符合日期格式,转化后的值为NaT
因为上一步骤中不符合日期格式的值转化后会变成空值,所以这里我们需要再运行一次删除重复值的操作:


这里注意一点:当我们在对数据进行分析时很多步骤不是只进行一步就可以了,往往都是反复不断得进行处理,因此使用jupyter notebook分步骤保存代码,可以方便我们随时查并使用每一个步骤的代码。
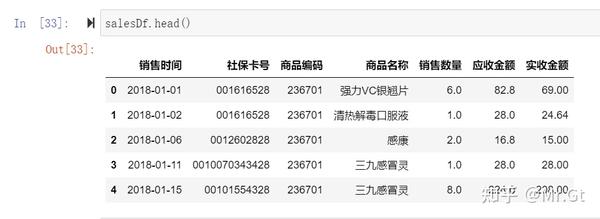
(5)数据排序
排序前的数据框:

排序后的数据框:
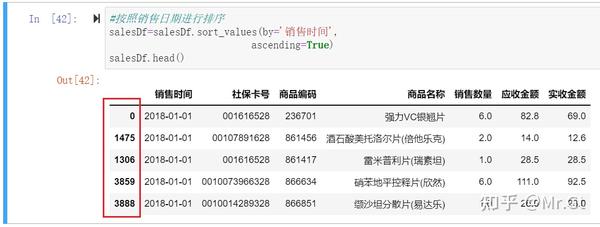

说明:这里使用sort_values进行排序,其中参数by后面指定排序的依据,这里依据“销售时间”列的数据,另一个参数ascending表示排序规则,如果为True表示升序,如果为False表示降序。
为了方便后续利用行号查询数据,我们可以对行号进行重命名,这里我们使用reset_index的方法:
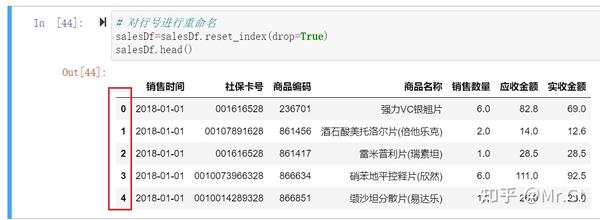

(6)异常值处理
这里使用描述统计describe对清理排序后的数据进行描述统计分析,大致了解是否有异常值:
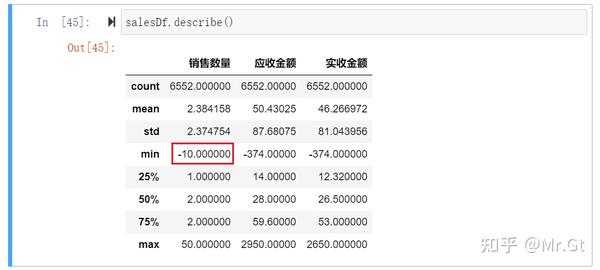

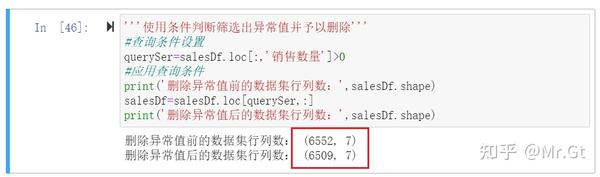
通过常识判断我们知道,销售数量不可能小于0 ,一定是数据有问题,这里使用条件判断筛选出错误数据予以删除:

- 构建模型
在进行分析前需要对提出的问题和指标构成与业务人员进行核对,明确指标含义才能针对问题进行分析。
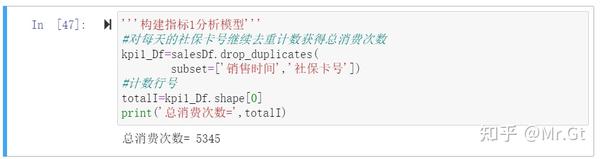
指标1:月均消费次数=总消费次数/月份数(总消费次数指同一天,同一人发生的所有消费算作一次消费)
那么对于指标1就变成了如何求出总消费次数了,观察数据集我们不难发现,可以通过对社保卡号进行计数得到消费次数,但同一天消费多次只能当作消费一次,因此可以对每天的社保卡号继续去重计数获得总消费次数。

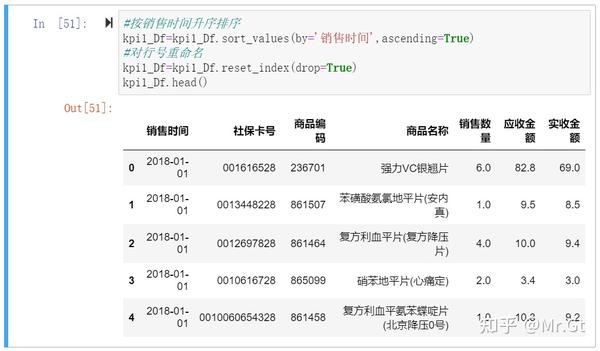
接下来只要计算出消费月份数即可计算出指标1的月均消费次数了:
首先进行排序:

接着获取时间范围:
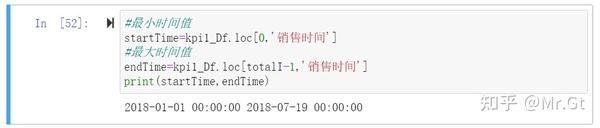

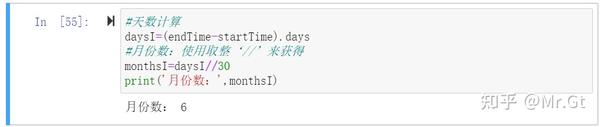
最后计算月份数:

再次基础上我们就可以获得指标1的计算结果了:


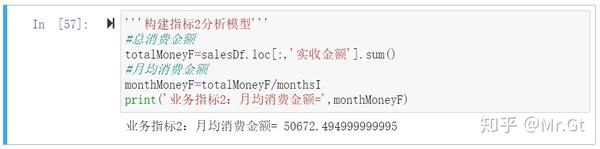
指标2:月均消费金额=总消费金额/月份数
如图:

指标3:客单价=总消费金额/总消费次数
如图:


指标4:消费趋势
该指标涉及到pandas库更高级的功能使用和数据可视化的使用,将放在后续文章中进行讲解。
- 数据可视化
这部分内容将在后续文章中更新讲解,尽情期待~
【本文相关代码】
'''使用python的pandas包,构建数据框,导入Excel数据,整体把握数据集情况'''
#导入第三方库Pandas,并导入Excel数据,构建数据框
import pandas as pd
fileNameStr='E:\医院销售数据.xlsx'
salesDf=pd.read_excel(fileNameStr,sheet_name='Sheet1',dtype=str)
#检查前几行数据已确认数据正确导入
salesDf.head(3)
#检查导入数据集的整体行列数,确保导入正确,没有丢失数据
salesDf.shape
#查看列的数据类型
salesDf.dtypes
#选择子集
subsalesDf=salesDf.loc[0:4,'购药时间':'销售数量']
subsalesDf
#列名重命名,使用字典构建新旧列名参数,再用数据框的rename对列名进行重命名
colNameDict={'购药时间':'销售时间'}
salesDf.rename(columns=colNameDict,inplace=True)
salesDf.head()
#使用直接删除的方法处理缺失值
print('删除缺失值前数据集大小为:',salesDf.shape)
#删除列(销售时间,社保卡号)中为空的行
salesDf=salesDf.dropna(subset=['销售时间','社保卡号'],how='any')
print('删除缺失值后数据集大小为:',salesDf.shape)
#对数值类型数据进行数据类型转换
print('数据类型抓换前的数据类型:\n',salesDf.dtypes)
salesDf['销售数量']=salesDf['销售数量'].astype('float')
salesDf['应收金额']=salesDf['应收金额'].astype('float')
salesDf['实收金额']=salesDf['实收金额'].astype('float')
print('数据类型抓换后的数据类型:\n',salesDf.dtypes)
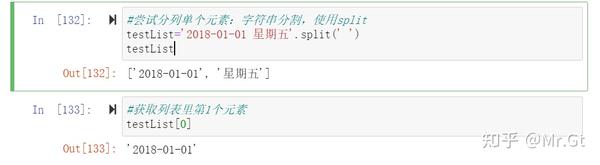
#尝试分列单个元素:字符串分割,使用split
testList='2018-01-01 星期五'.split(' ')
testList
#获取列表里第1个元素
testList[0]
定义一个函数:分割以空格为分割依据的销售日期,获取销售日期正确格式
输入:timeColSer销售时间这一列,是Series数据类型
输出:分割后的时间,反回也是Series数据类型
def splitSalestime(timeColSer):
timeList=[]
for value in timeColSer:
#例如2018-01-01 星期五,被分割后为:2018-01-01
dateStr=value.split(' ')[0]
timeList.append(dateStr)
#将列表转化为一维数据Series类型
timeSer=pd.Series(timeList)
return timeSer
'''调用上面的函数,进行分割操作'''
#获取“销售时间”这一列
timeSer=salesDf.loc[:,'销售时间']
#对字符串进行分割,获取销售日期
dateSer=splitSalestime(timeSer)
#显示3行以确认分割成功
dateSer[0:3]
#修改销售时间这一列的值
salesDf.loc[:,'销售时间']=dateSer.values
#显示修改后的数据框
salesDf.head()
#将字符串格式的日期修改成日期格式
salesDf.loc[:,'销售时间']=pd.to_datetime(salesDf.loc[:,'销售时间'],
format='%Y-%m-%d',
errors='coerce')
salesDf.dtypes
#再次删除列(销售时间,社保卡号)中为空的行
salesDf=salesDf.dropna(subset=['销售时间','社保卡号'],how='any')
#按照销售日期进行排序
salesDf=salesDf.sort_values(by='销售时间',
ascending=True)
salesDf.head()
# 对行号进行重命名
salesDf=salesDf.reset_index(drop=True)
salesDf.head()
'''使用条件判断筛选出异常值并予以删除'''
#查询条件设置
querySer=salesDf.loc[:,'销售数量']>0
#应用查询条件
print('删除异常值前的数据集行列数:',salesDf.shape)
salesDf=salesDf.loc[querySer,:]
print('删除异常值后的数据集行列数:',salesDf.shape)
'''构建指标1分析模型'''
#对每天的社保卡号继续去重计数获得总消费次数
kpi1_Df=salesDf.drop_duplicates(
subset=['销售时间','社保卡号'])
#计数行号
totalI=kpi1_Df.shape[0]
print('总消费次数=',totalI)
#按销售时间升序排序
kpi1_Df=kpi1_Df.sort_values(by='销售时间',ascending=True)
#对行号重命名
kpi1_Df=kpi1_Df.reset_index(drop=True)
kpi1_Df.head()
#最小时间值
startTime=kpi1_Df.loc[0,'销售时间']
#最大时间值
endTime=kpi1_Df.loc[totalI-1,'销售时间']
print(startTime,endTime)
#天数计算
daysI=(endTime-startTime).days
#月份数:使用取整‘//’来获得
monthsI=daysI//30
print('月份数:',monthsI)
#计算业务指标1=总消费次数/月份数
kpi1_I=totalI/monthsI
print('业务指标1:月均消费次数=',kpi1_I)
'''构建指标2分析模型'''
#总消费金额
totalMoneyF=salesDf.loc[:,'实收金额'].sum()