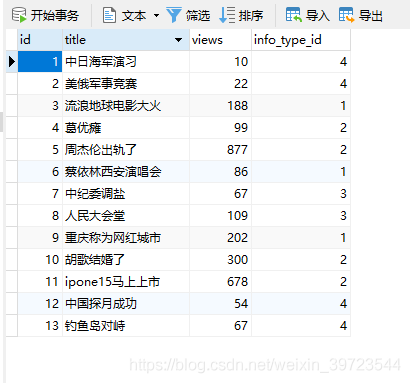
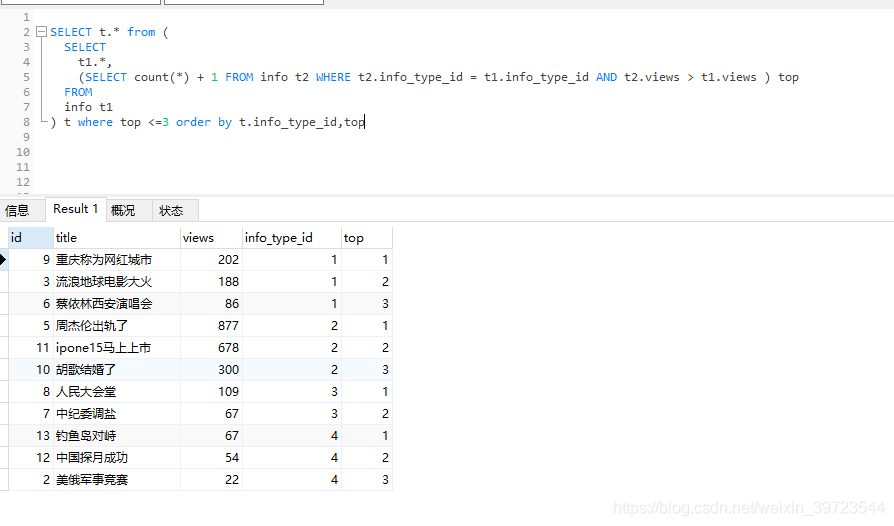
初始化SQL语句
DROP TABLE IF EXISTS `info`;
CREATE TABLE `info` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`title` varchar(255) CHARACTER SET utf8 COLLATE utf8_general_ci DEFAULT NULL,
`views` int(255) DEFAULT NULL,
`info_type_id` int(11) DEFAULT NULL,
PRIMARY KEY (`id`) USING BTREE
) ENGINE = InnoDB CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Dynamic;
-- ----------------------------
-- Records of info
-- ----------------------------
INSERT INTO `info` VALUES (1, '中日海军演习', 10, 4);
INSERT INTO `info` VALUES (2, '美俄军事竞赛', 22, 4);
INSERT INTO `info` VALUES (3, '流浪地球电影大火', 188, 1);
INSERT INTO `info` VALUES (4, '葛优瘫', 99, 2);
INSERT INTO `info` VALUES (5, '周杰伦出轨了', 877, 2);
INSERT INTO `info` VALUES (6, '蔡依林西安演唱会', 86, 1);
INSERT INTO `info` VALUES (7, '中纪委调盐', 67, 3);
INSERT INTO `info` VALUES (8, '人民大会堂', 109, 3);
INSERT INTO `info` VALUES (9, '重庆称为网红城市', 202, 1);
INSERT INTO `info` VALUES (10, '胡歌结婚了', 300, 2);
INSERT INTO `info` VALUES (11, 'ipone15马上上市', 678, 2);
INSERT INTO `info` VALUES (12, '中国探月成功', 54, 4);
INSERT INTO `info` VALUES (13, '钓鱼岛对峙', 67, 4);
DROP TABLE IF EXISTS `info_type`;
CREATE TABLE `info_type` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`name` varchar(255) CHARACTER SET utf8 COLLATE utf8_general_ci DEFAULT NULL,
PRIMARY KEY (`id`) USING BTREE
) ENGINE = InnoDB CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Dynamic;
-- ----------------------------
-- Records of info_type
-- ----------------------------
INSERT INTO `info_type` VALUES (1, '娱乐');
INSERT INTO `info_type` VALUES (2, '八卦');
INSERT INTO `info_type` VALUES (3, '政治');
INSERT INTO `info_type` VALUES (4, '军事');
资讯分类示例数据如下:
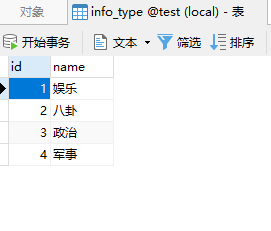
资讯信息记录表示例数据如下: