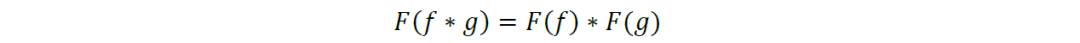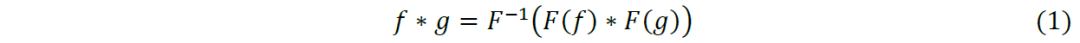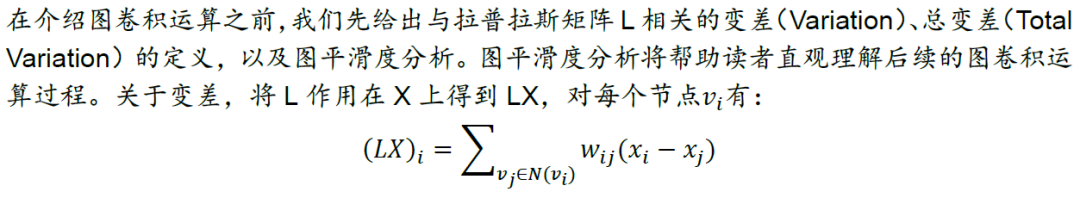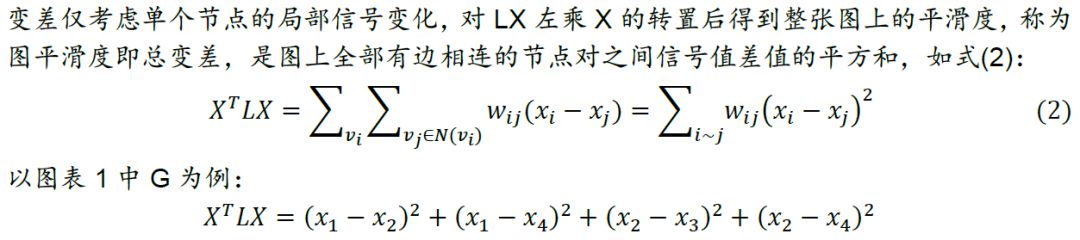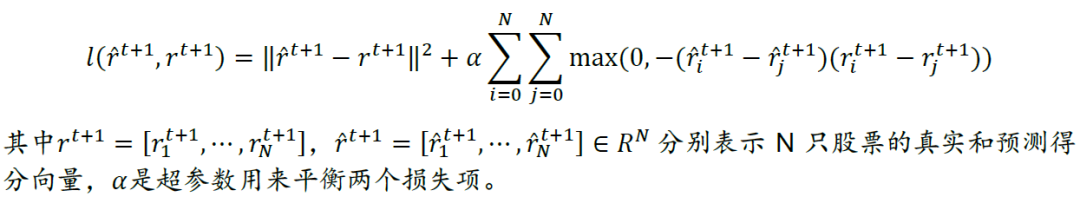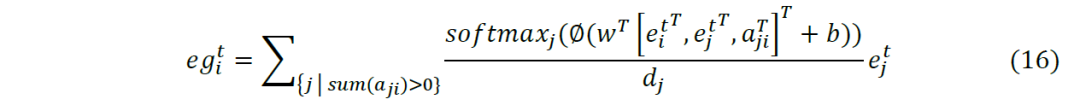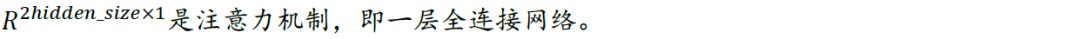炒股就看
金麒麟分析师研报
,权威,专业,及时,全面,助您挖掘潜力主题机会!
来源:华泰金融工程
S0570516010001
SFC No. BPY421 研究员
李子钰 S0570519110003 研究员
何康 S0570520080004 研究员
王晨宇 S0570119110038 联系人
报告发布时间:2021年2月21日
摘要
人工智能42:图神经网络考虑股票间关系的增量信息,提升选股策略表现
本文是华泰人工智能系列第42篇深度研究,介绍图神经网络(GNN)概念,通过微软Qlib平台测试GNN选股效果。传统因子选股模型中,通常将股票视作相互独立的样本,但股票间显然存在复杂关联,如产业链上下游关系、相关行业主题等。GNN的优势在于能将股票间关系作为增量信息纳入预测模型。微软AI量化投资开源平台Qlib已实现动态图注意力网络(GATs_ts),我们测试该方法在沪深300成分股量价因子日频选股上的表现,相比基准模型LSTM,GATs_ts回测期内(2010年至2021年2月初)相对沪深300年化超额收益率从25.7%提升至28.9%,信息比率从2.64提升至2.94。
图神经网络对样本间关系进行建图,将邻居节点的特征聚合到中心节点
图神经网络(GNN)将深度学习技术的使用场景从传统的图像、语音拓展至图结构数据,在欺诈检测、购物推荐等领域有广泛应用。GNN由图信号理论和谱域图卷积发展而来,其思想是对样本间关系进行显式或隐式建图,每个节点对应一条样本,再将邻居节点的特征聚合到中心节点,以更新节点特征。图卷积网络(GCN)、GraphSAGE、图注意力网络(GAT)是三种具有代表性的GNN。GCN属于转导学习,当新样本加入时需重新训练模型方能进行预测;GraphSAGE和GAT分别通过聚合器和注意力机制的方式实现归纳学习,可直接用于新样本预测,适用于样本动态变化的股票市场。
图时空网络将循环神经网络与图神经网络相结合,适用于量化选股
图时空网络的核心思想是将循环神经网络(或卷积神经网络)与图神经网络结合,目标是学习原始数据时间域和空间域上更丰富的信息,适用于量化选股领域。关系股票排序框架(RSR)和GATs_ts都属于图时空网络范畴。RSR在顺序嵌入层采用LSTM学习股票的时间序列特征,随后对股票间的多种类型关系构建显式图,在关系嵌入层使用动态时间图卷积学习股票间的相互作用,最终预测股票收益率排序。GATs_ts与RSR类似,在动态时间图卷积模块采用GAT的全局注意力机制,无需对股票市场显式建图,而是隐式学习所有节点对中心节点的影响,再将这些信息聚合到中心节点。
Qlib平台实现基于Alpha158因子和GATs_ts的沪深300成分内选股策略
微软AI量化平台Qlib已实现一层GATs_ts,在源码基础上加以改造可实现多层GATs_ts。基于Qlib内置的Alpha158vwap因子库,采用GATs_ts对沪深300成分股进行日收益率预测,使用Qlib提供的TopkDropout策略构建日频调仓投资组合。回测期内(2010-01-04至2021-02-02),一层GATs_ts年化收益率35.70%,夏普比率1.42,相对于基准
沪深300指数
的年化超额收益率28.89%,信息比率2.94,超额收益最大回撤-16.92%,表现优于基准模型LSTM和多层GATs_ts。
风险提示:Qlib仍在开发中,部分功能未加完善和验证,使用存在风险。人工智能挖掘市场规律是对历史的总结,市场规律在未来可能失效。人工智能技术存在过拟合风险。
研究导读
本文介绍图神经网络基础概念,通过微软Qlib平台测试图神经网络应用于日频选股的效果。传统线性或非线性选股模型中,通常将股票视作相互独立的样本,然而股票间显然存在复杂的关联,如产业链的上下游关系、相关行业主题等。如何将股票间的关系作为增量信息纳入预测模型,是本文希望解决的核心问题。
传统的卷积神经网络(CNN)、循环神经网络系列(RNN和LSTM)不具备考虑样本间关系的能力。CNN通过卷积运算提取样本局部特征,适用于图像数据。RNN和LSTM的循环结构使得网络能够学习时序上的规律,适用于语音等时序数据。如果希望网络学习样本间关联的规律,那么就需要对网络运算方式或结构进行相应改造。
近年来,研究者陆续提出图卷积网络(Graph Convolutional Network,简称GCN)、GraphSAGE(Graph SAmple and aggreGatE)、图注意力网络(Graph Attenion Network ,简称GAT),正是将图论的概念引入传统神经网络,创造出一套全新的适用于图结构数据的网络架构,统称图神经网络(Graph Neural Network,简称GNN)。GNN在学界和业界有着深远影响及广泛应用,对量化选股领域同样具有很高的借鉴价值。
在华泰金工《人工智能40:微软AI量化投资平台Qlib体验》(2020-12-22)中,我们讲解Qlib的基础和进阶功能,该平台的优势在于覆盖量化投资全过程,从工程实现角度对因子存储、因子计算等环节提出创新解决方案,目前已开源的功能侧重于量价因子结合AI模型选股。Qlib除纳入集成学习及传统循环神经网络等AI模型外,还实现了动态图注意力网络(GATs_ts)。GATs_ts将循环神经网络和GAT结合,兼顾股票时序信息和股票间关系信息。借助Qlib开源平台,我们得以方便地了解图神经网络的实现细节,并测试该方法在量价因子选股上的表现。
本文主要内容如下:
1. 第一部分讲解GNN的基础概念,依次介绍谱域图卷积运算、谱域图卷积网络、空间域图卷积网络的概念。完整的GNN由上述三者一步步发展而来,介绍其发展历史有助于读者更好理解GNN的内涵。
2. 第二部分介绍GNN针对选股问题而诞生出的变式——图时空网络选股框架,其中关系股票排序框架(Relational Stock Ranking,简称RSR)和GATs_ts都属于图时空网络选股框架范畴。我们首先从RSR切入,引出图时空网络选股的设计思路。
3. 第三部分关注GATs_ts在微软Qlib平台的具体实现方式。我们将详细介绍GATs_ts的选股思路和Qlib代码,随后在GATs_ts基础上,实现多跳邻居聚合即多层GATs_ts。
4. 第四部分采用Qlib内置的Alpha158vwap因子库及TopkDropout策略,在2010年1月初至2021年2月初区间内进行日频选股实证,比较基准模型LSTM和GATs_ts(层数K=1、2和3)表现。
我们认为,动态图注意力网络作为一种新的方法论,将样本的时序信息与样本间关联信息结合在一起,通过空间域上的邻居聚合得到股票节点的嵌入表示(Embedding),这是相比传统机器学习及深度学习架构的创新之处。未来有更多方向值得探索,如建图方法、网络结构、策略构建等。
图神经网络
图神经网络将深度学习技术的使用场景从传统的图像、语音等数据拓展至图结构数据,在欺诈检测、购物推荐和交通流量预测等领域都有广泛应用。本章将从谱域和空间域两个方向介绍图神经网络:首先以图信号处理为基础,介绍谱域下的图卷积运算过程,通过参数化谱域卷积滤波器和切比雪夫多项式近似得到谱域图卷积网络,进而得到一阶切比雪夫图卷积网络即图卷积网络(GCN),由此引出GCN从谱域到空间域的过渡;随后介绍GCN在空间域下的两个改进变式:GraphSAGE和图注意力网络(GAT)。
谱域图卷积运算
图的基本定义和性质
谱域图卷积网络(Spectral-based GCN)为后续空间域图卷积网络(Spatial-based GCN)提供了强有力的理论基础,方便我们理解图神经网络如何发展而来。我们首先给出图及谱图理论的一些基本定义。
图傅里叶变换
图结构数据节点具有无序性和不规则性两个特征,前者是指邻居节点不具备空间上的天然顺序,后者指节点的邻居节点数量不固定。深度学习中最具代表性的卷积神经网络(CNN)使用卷积核平移扫描图像的方式,对像素点局部空间信息进行加权求和,像素点周围是固定的8个邻居像素点,这些点具有空间顺序。由此可见,CNN的应用场景和图结构数据不匹配,无法直接将图像领域的成熟解决方案应用于图结构数据。
我们考虑运用卷积定理,将节点的空间域信息先转换到谱域上,经过在谱域上的变换后,再返回到原始的空间域上。其意义在于将空间域上的卷积运算转换为谱域上的相乘运算。卷积定理指函数卷积的傅里叶变换等于函数傅里叶变换的乘积:
两个函数f和g的卷积运算在谱域上表示如下,其中F表示傅里叶变换。
谱域图卷积是在图信号处理(Graph Signal Processing,简称GSP)的基础上,由式(1)卷积定理得到。根据式(1)我们需要找到图上类似的傅里叶基以及傅里叶变换该如何定义,并有什么样的含义。
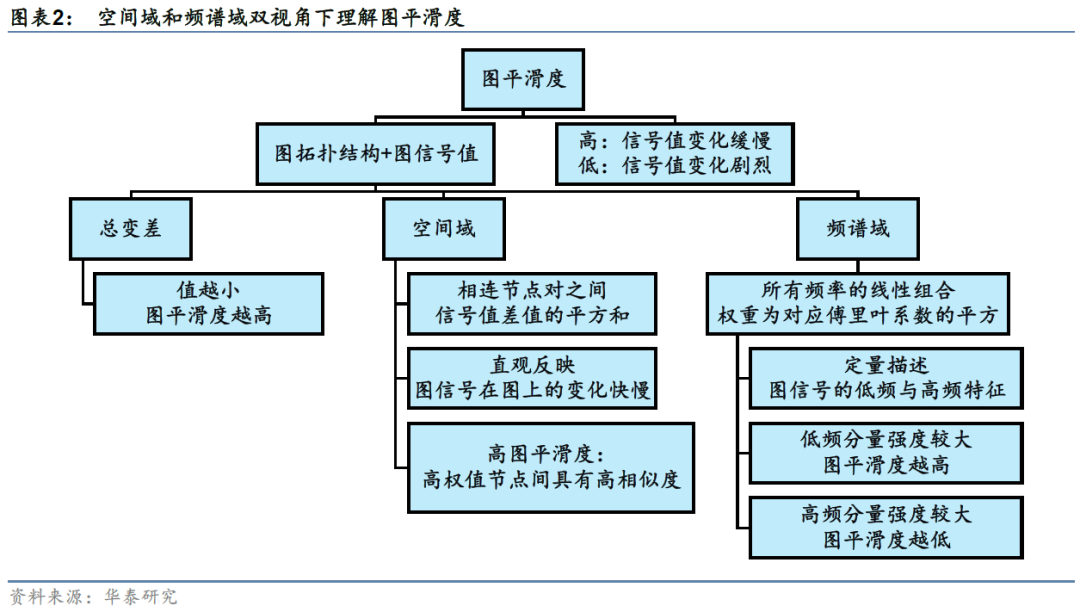
总变差及图平滑度分析
在图的半监督学习中,总变差(不需要标签信息)可以作为图正则项加入损失函数,对每一组相连的节点对进行约束。最小化损失函数的过程可以保证总变差尽可能小,从而实现平滑假设。所谓平滑假设,是指对图网络我们假设相邻节点之间往往有相似的预测,这一类网络称为同配图(Assortative Graph),例如引文网络(Citation Network)的Cora, Citeseer和Pubmed数据集。
与同配图对应的是异配图(Disassortative Graph),在这类图中具有不同标签的节点反而有边相连,因此平滑假设不适用于异配图。对于异配图我们的目标反而应该是最大化总变差,相应的操作是将总变差的相反数加入损失函数中。
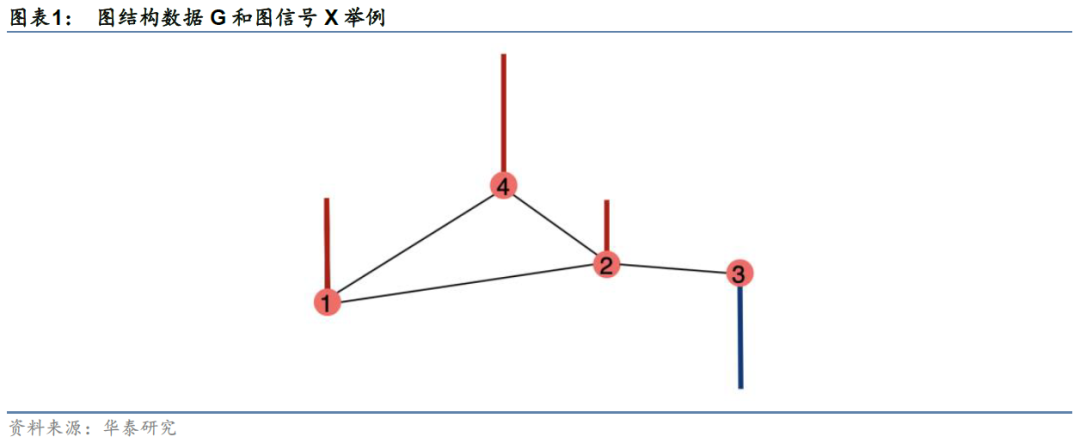
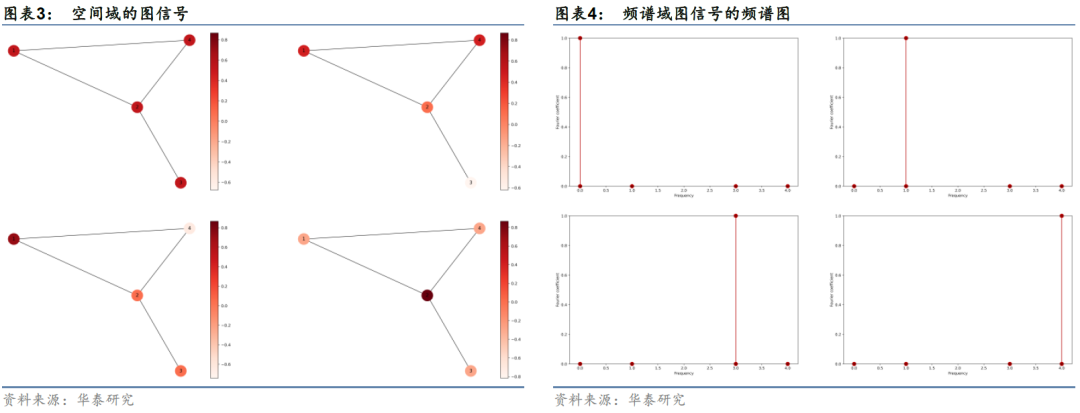
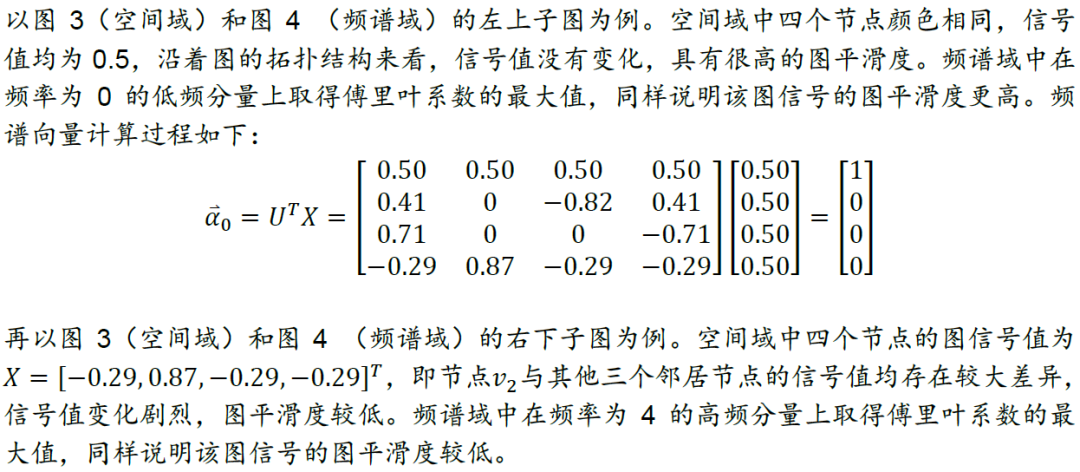
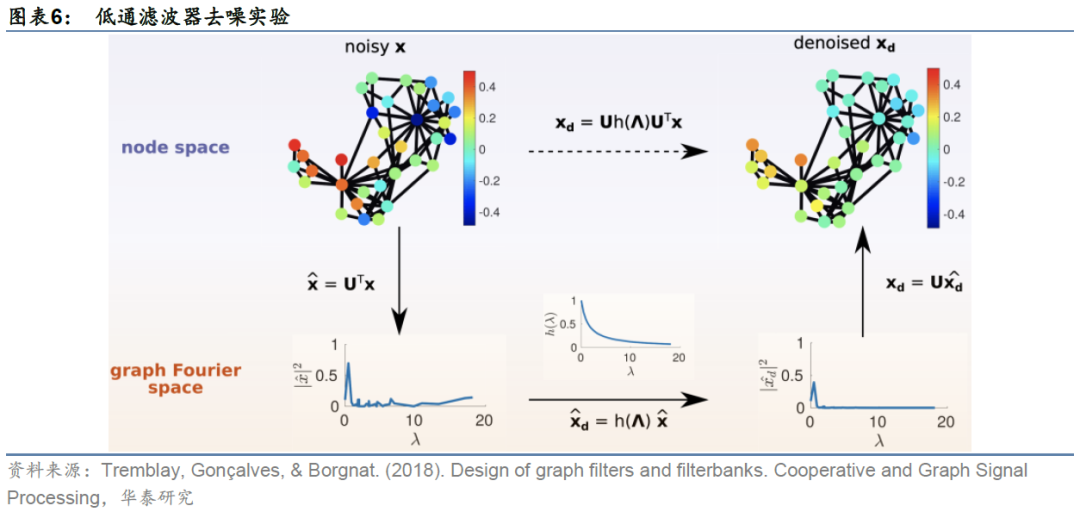
下面我们以更具体的例子展示图平滑度分析的过程。以图表1中G为例,我们分别设定四组不同的信号值,计算四种情况各自对应的图平滑度。每一种情况下,各节点的信号值以色阶形式展示在空间域上,如图3所示;按特征值从小到大的顺序,将图信号在该频率分量上的傅里叶系数即强度以柱图形式展示在频谱域上,如图4所示。
图卷积运算
有了拉普拉斯矩阵和图傅里叶变换的定义后,我们对图信号先转换到谱域,对其在谱域上进行滤波操作,提取滤波器想要提取的特征,再对两者在谱域上的乘积做逆图傅里叶变换,得到空间域上新的图信号。由于滤波操作相当于卷积,因此上述运算也称为图卷积运算。
谱域图卷积网络
参数化
多项式图卷积
截断切比雪夫多项式图卷积:ChebNet
空间域图卷积网络
GCN:谱域向空间域的经典过渡
谱域
空间域
GraphSAGE:聚合器实现归纳学习,可应用于动态图
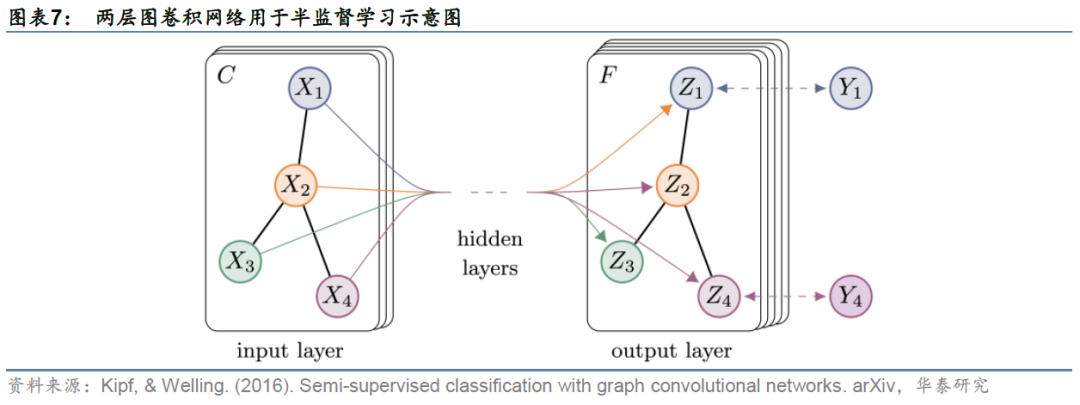
GCN在空间域实际上是一个迭代式多跳聚合邻居节点特征、将其特征降至低维的过程,但GCN存在的主要问题如下:
1. GCN属于转导学习(Transductive Learning),式(8)需要增强版归一化邻接矩阵\hat{W}作为输入,并且它是基于整张图的固定结构。这种学习要求模型在训练和测试过程中,图上所有节点可见。如果加入新节点或将训练好的模型用于全新的图,则无法通过转导学习完成,需要重新训练模型。现实中大部分图往往是动态变化的,比如股票网络随着时间的推移会有新公司上市。相反,归纳学习(Inductive Learning)可以通过学习一种规则或函数来泛化预测从未见过的节点。
2. GCN的训练是全图方式(Full-Batch),占用内存较多,尽管其作者提出将稀疏矩阵和稠密矩阵相乘的方式来加速运算,但其结构不允许采用小批量随机梯度下降方法(Mini-Batch SGD)训练,因此仍然无法推广到大规模图训练上。
针对上述问题,研究者提出大规模图上的归纳学习框架(Graph SAmple and aggreGatE,简称GraphSAGE),利用节点特征为不可见数据生成节点嵌入(Hamilton et al.,2017)。GraphSAGE并非像式(10)和GCN式(11)为每个节点训练一个单独嵌入,而是学习训练一组聚合器,通过从一个节点的局部邻居中采样,与聚合器生成节点嵌入。
图8上侧的三个子图展示了GraphSAGE的采样聚合过程。我们希望对左上子图的中心节点生成节点嵌入。采样如左上子图所示,以由内向外的方式进行:首先对中心节点的5个1跳邻居采样,得到3个标红的1跳邻居节点;随后对每个1跳邻居节点的1跳邻居采样,得到最外圈标红的2跳邻居节点。聚合如中上子图所示,以由外向内的方式进行:首先将2跳邻居节点的特征聚合到1跳邻居节点,如绿色箭头;随后将1跳邻居节点的特征聚合到中心节点。最终右上子图的中心节点已经包含其2跳邻居的特征,称为2跳嵌入表示。
图8下侧的三个子图展示了聚合过程的另一种理解方式——计算树。左下子图为节点A作为中心节点的计算树,即{A}的1跳邻居节点为{B,C,D},1跳邻居的1跳邻居(即A的2跳邻居节点)分别为{A,C}、{A,B,E,F}和{A}。右下子图中,2跳邻居节点(Layer-0)的特征首先聚合到1跳邻居节点(Layer-1),再聚合到中心节点(Layer-2),最终得到中心节点的2跳节点嵌入。通过上述前向传播算法,可以得到全部节点的任意K跳节点嵌入,K为节点的搜索深度。
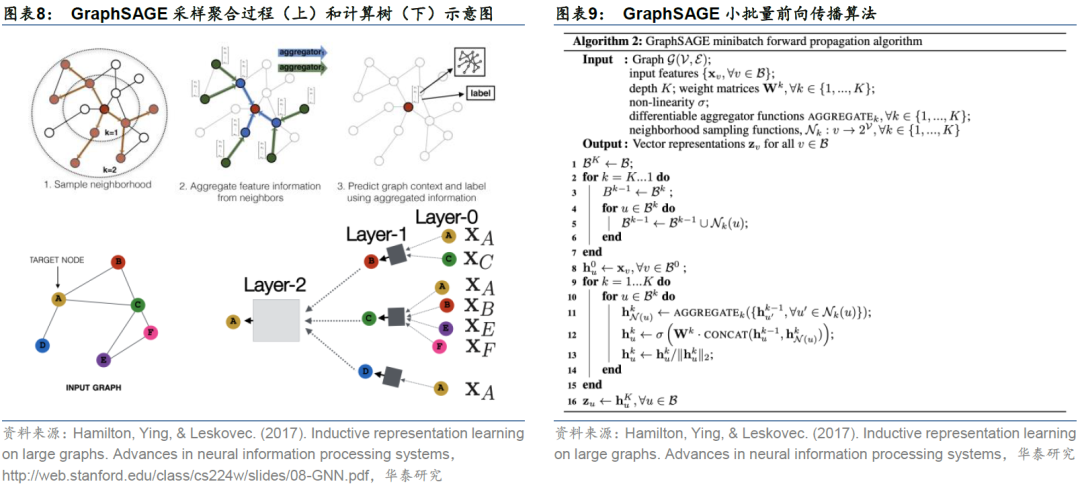 图9展示GraphSAGE小批量前向传播算法的伪代码,整体分为两部分。
图9展示GraphSAGE小批量前向传播算法的伪代码,整体分为两部分。
1. 由内到外采样
2. 由外到内聚合
通过采样阶段和聚合阶段训练后,只要基于某一节点及其K阶邻居节点的特征和关系,就可以通过该聚合器得到节点的嵌入表示。GraphSAGE是空间域视角下GCN走向工业落地的代表性变体。
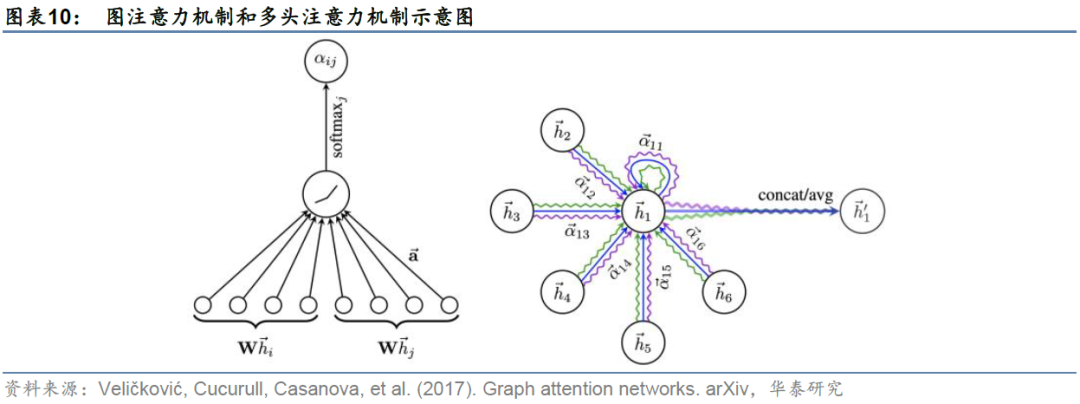
GAT:差异化邻居节点对中心节点的影响
从空间域角度看,GCN与消息传递的思路相似,将中心节点v的邻居节点N(v)特征以某种方式聚合到该中心节点上,既考虑了图的拓扑结构,也考虑了邻居节点的特征信息。由此GCN完成了图神经网络由谱域向空间域的经典过渡。
1. 计算注意力系数
2. 标准化注意力系数
3. 加权求和
邻居节点关系在作者用到的Masked Self-Attention方式中是必需的,因为上文提到该方式计算的是1跳邻居节点与中心节点间的注意力系数。而另一种Global Self-Attention全局方式不需要图结构信息,它计算了中心节点与图中所有节点之间的注意力系数,并将所有节点特征聚合给自己,因此该方式不需要预先构建显式图,但这也在一定程度上损失了图结构信息且计算成本高昂。全局方式将在后文Qlib平台的GATs_ts动态图注意力网络选股中用到。
最后,我们展示GCN、GraphSAGE和GAT的主要公式、核心思想及分析比较,见下表。
图时空网络选股框架
本章介绍图时空网络在量化选股中的应用。图时空网络的核心思想是将循环神经网络(或卷积神经网络)与图神经网络相结合,目标是学习到原始数据中时间域和空间域上更丰富的信息,适用于量化选股领域。
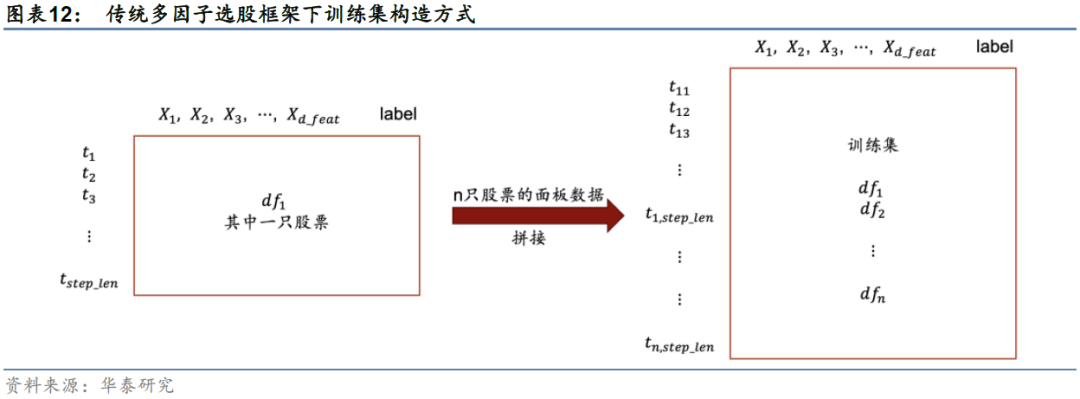
传统多因子选股框架中,股票数据属于面板数据,对单只股票而言,包含时间序列信息和一系列因子特征信息。传统的数据处理方法是将各时间截面上的各股票样本简单拼接起来组成训练集(如图12),送入全连接网络或循环神经网络,尽管数据量可以很大,但并没有挖掘出足够多的信息。这种数据处理方法忽略了面板数据所能提供的额外信息,比如时间域上的价格的自相关性和传递性,以及空间域上股票之间的相关性。
具体分析面板数据中所蕴涵的额外信息,从时间和空间两个维度讨论。从时间域维度看,同一只股票价格及因子特征存在自相关性;不同股票之间也存在交叉相关性,如龙头股票领涨,导致其它股票在未来跟涨。从空间域维度看,相同行业板块的股票之间存在相关度;不同行业股票之间也存在关联,如产业链上下游关系。
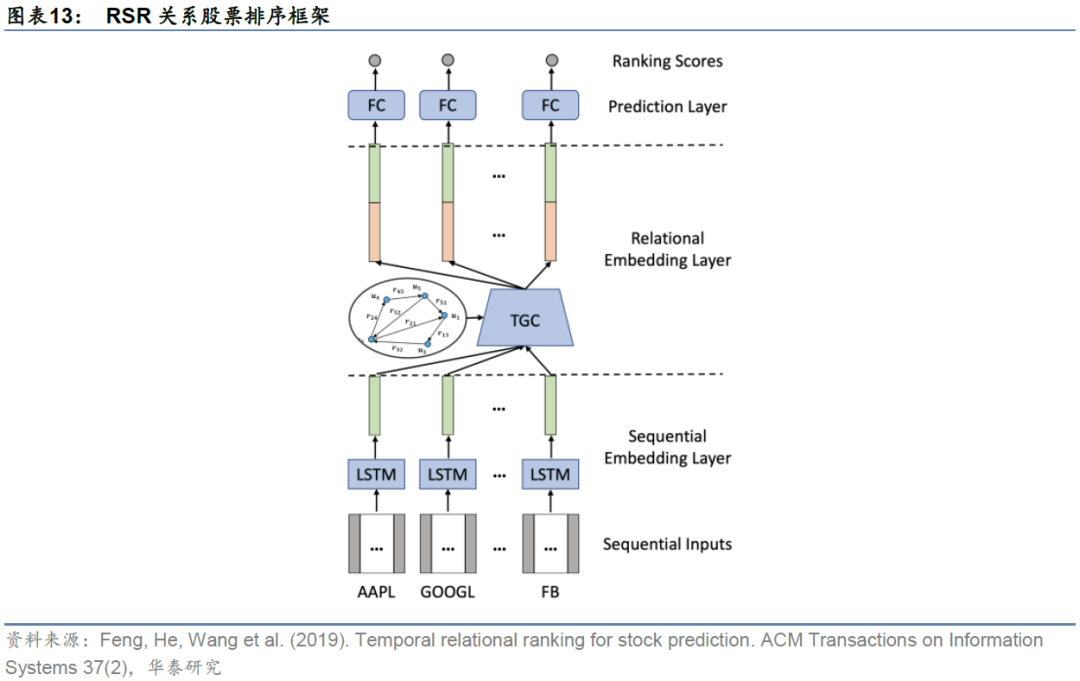
RSR关系股票排序框架
关系股票排序框架(Relational Stock Ranking,简称RSR)利用LSTM处理时间序列的优势和图神经网络GNN在空间域的优势,解决股票收益率的排序预测问题(Feng et al.,2019)。作为一种图时空网络模型,它为人工智能在选股上的应用提供了新的思路。
顺序嵌入层
股票数据蕴含丰富的时间信息,股票的历史状况可能是影响其未来走势的最具影响力的因素之一。顺序嵌入层将每只股票的历史特征时间序列数据输入到LSTM,以捕获序列相关性,最终学习到股票的顺序嵌入。
关系嵌入层
关系嵌入层的核心是建立描述股票间关联关系的模型。股票间的关联可以体现在:若两家公司在同一个板块或行业,它们的股价可能表现出类似的趋势,因为它们往往受到类似的外部事件影响;若两家公司是供应链上的合作伙伴,那么上/下游公司的事件可能会影响下/上游公司的股价。
1. 一致嵌入传播(Uniform Embedding Propagation):仅考虑dj的显式关系
2.加权嵌入传播(Weighted Embedding Propagation):通过关系-强度函数
3. 时间敏感嵌入传播(Time-aware Embedding Propagation):aji上加入动态信息
预测层
RSR框架最后将顺序嵌入层和关系嵌入层的结果进行拼接,输入到一个全连接层,以预测各股票收益率的排名得分,根据预测得分构建投资组合。为了优化模型,作者提出了一个点对回归损失和成对排序损失加和的目标函数:
上述目标函数中第一个回归项惩罚了真实值和预测得分之间的差异,第二项是成对的最大边际损失,它鼓励股票对的预测分数与真实值保持相同的相对顺序。这样一来有如下好处:
1. 保证绝对收益率的预测结果:准确预测收益率有利于确定投资时机,因为只有在收益率大幅上升时,排名靠前的股票才会成为有价值的投资目标;
2. 保证股票收益率的相对顺序,以便投资者做出更好的投资决策:正确的股票相对顺序有助于选择投资目标,例如选择排名更高的股票。
RSR和GAT的比较
RSR框架首先根据股票间多种类型关系得到股票关系图,随后运用时序信息和股票关系来预测股票的未来收益率排序情况。RSR框架的重要贡献如下:
1. 为股票间建立多种类型关系,构建了真实存在的关系图:对纳斯达克交易所/纽交所的股票分别构建了112/130种行业关系和42/32种基于维基百科中公司描述的关系,例如供应商-消费者关系和所有权关系;
2. 将股票预测设置为排序任务,提出RSR深度学习框架进行股票收益率的排名预测;
3. 以一种时间敏感的方式捕获股票关系,提出一种新的神经网络建模组件TGC,将股票的时间演化和股票间关系注入到模型中。
我们将式(15)得到的强度通过softmax函数标准化使邻居间可比,代入式(14)得到如下关系嵌入:
微软Qlib平台GATs_ts模型的应用介绍
本章我们关注图神经网络选股在微软Qlib平台的实现方式。Qlib是微软开发的开源AI量化投资平台,Qlib源码在base.Model基类的基础上提供了多个AI算法(Model Zoo)样例,包括Boosting集成学习、循环神经网络和图神经网络等。Qlib中称这些AI算法为预测模型(Forecast Model),先用样本内数据集训练模型,再对样本外数据集的每只股票进行预测。由于组件的设计是松耦合的,这些模型可以作为一个独立的模块运行使用,用户也可以将自定义模型集成到Qlib中。
模型实现
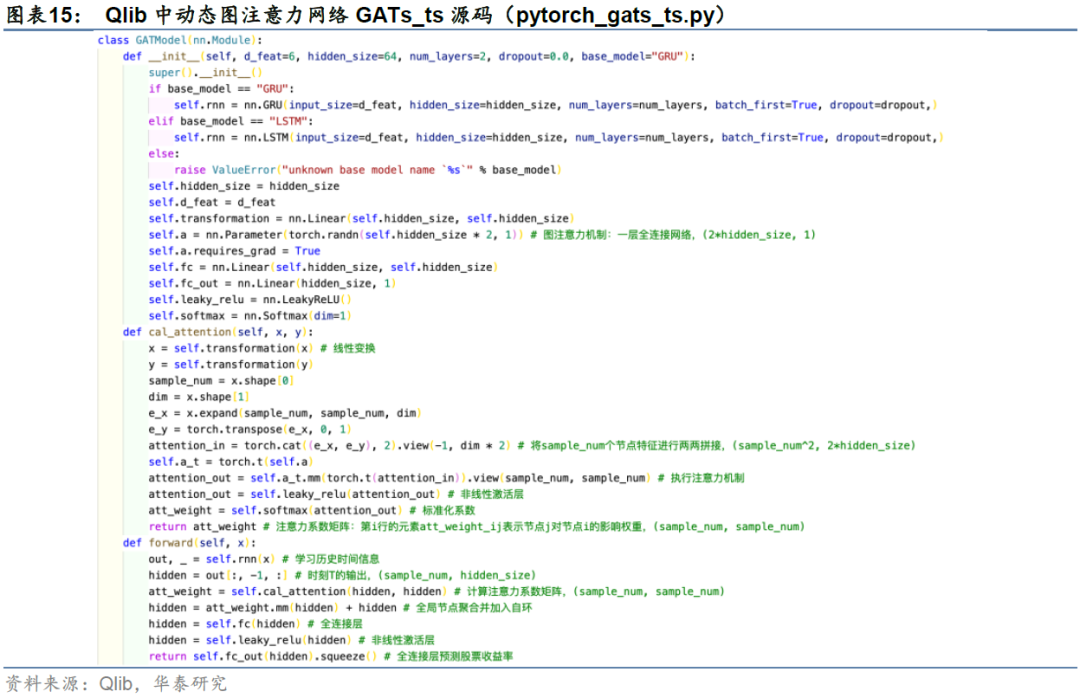
Qlib中目前提供的模型算法如下表所示,其中GATs_ts属于图神经网络范畴,本质是时间序列模型与图注意力机制的结合。下面我们介绍Qlib中GATs_ts用于量价因子选股的实现细节,并和长短期记忆网络LSTM进行比较。
在图神经网络一章的最后以及图时空网络选股框架一章中,我们分别介绍了图注意力网络GAT和RSR选股框架。两者的相似之处在于注意力机制的运用,区别主要在于节点特征是动态还是静态,即是否考虑图的动态性。Qlib中的GATs_ts模型借鉴了RSR的框架结构,并采用了GAT的自注意力机制全局方式。由于GATs_ts将循环神经网络RNN的最后时刻隐藏层状态特征送入GAT,因此我们称之为动态图注意力网络。
在顺序嵌入这一步,GATs_ts与RSR的顺序嵌入层一样,首先学习时间信息得到顺序嵌入hidden:
在关系嵌入这一步,GATs_ts采用GAT中注意力机制的Global Self-Attention全局方式,这种方式不需要像RSR那样构建显式的股票关系图,而是对每一个中心节点计算其它所有节点的特征聚合。
GATs_ts与LSTM输入数据辨析
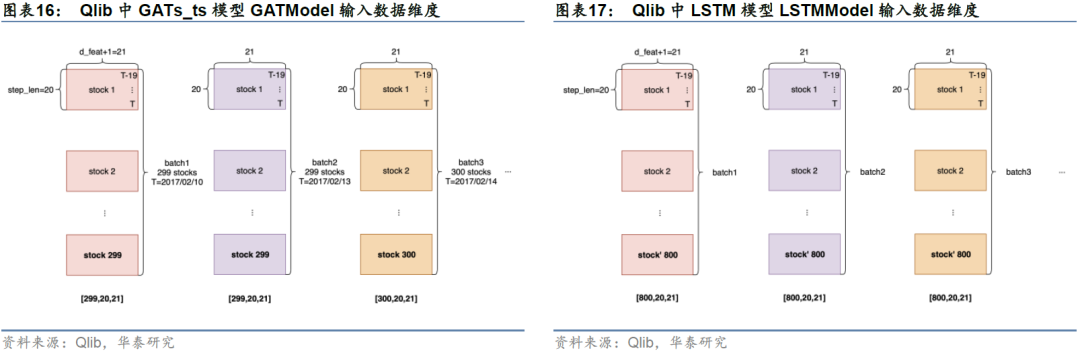
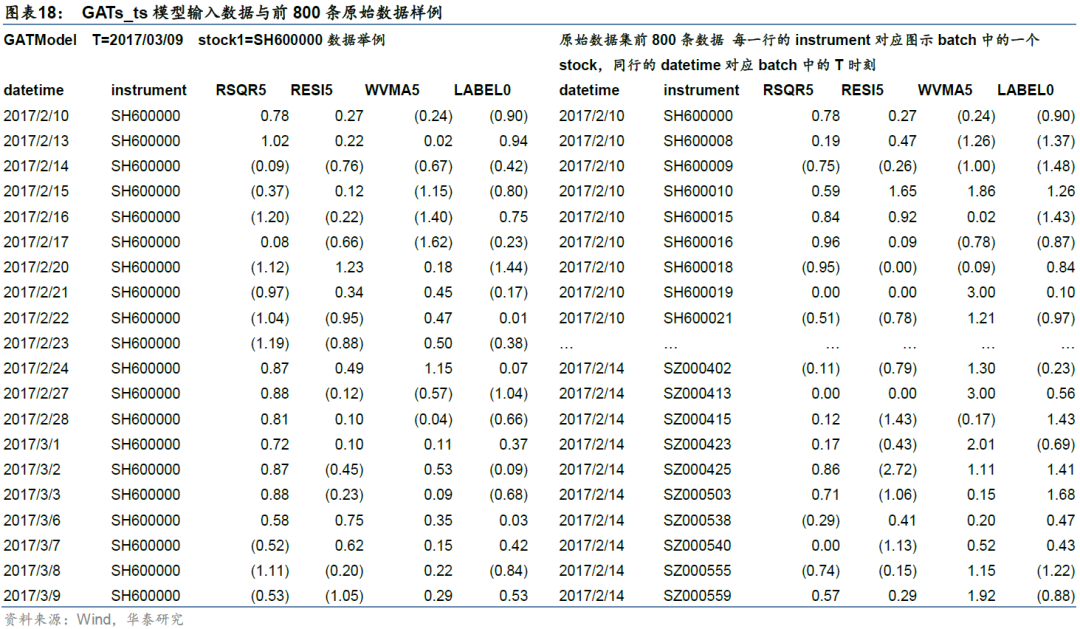
为了帮助读者更好理解GATs_t所使用的输入数据结构,我们对GATs_ts与LSTM输入数据进行辨析。LSTM输入数据结构参考Qlib源码pytorch_lstm_ts.py中的LSTMModel,GATs_ts输入数据结构参考Qlib源码pytorch_gats_ts.py中的GATModel。
在LSTM和GATs_ts模型中,每个batch张量在各维度的大小为[n_samples, step_len, d_feat+1]。其中n_samples为每个batch的样本数即batch_size,step_len为历史时间序列长度(此处设为20),d_feat为特征维度即因子个数(此处设为20),加1为其对应的标签列。GATs_ts与LSTM输入数据的核心区别就在于batch_size的处理。LSTM输入数据的batch_size是固定的,而GATs_ts输入数据的batch_size是可变的。
真实市场中,每个交易日的股票数量不同,例如2017年2月10日、13日和14日沪深300成分股票池的有效股票数量分别为299、299和300,14日相比前一交易日增加一只股票。此时,每个交易日的全局股票图网络是一个动态图。GATs_ts模型batch_size可变的特性使得模型可以将每个交易日的全部有效股票放进一个batch,不同batch对应不同交易日,而LSTM无法做到这一点。
图16和图17展示了两种模型的具体输入数据形式。图16的GATs_ts模型中,以T=2017/2/10对应的batch1为例(左上角),stock1的step_len维度为[T-19, T-18,…, T],即对应stock1股票从T-19到T日的因子特征。若该股票T-19到T-1日因子有缺失,则用最新数据补全之前的缺失值。图表18左侧展示了当T=2017/03/09时,stock1(SH600000)的原始数据。
图17 的LSTM模型中,原始训练集大小为[N, d_feat+1],N为训练集总行数,时间、股票代码分别为第一、第二索引(如图表18)。对每800行中的样本,取从T-19到T日20天的因子特征及标签放进一个batch,得到[800, 20, 21]的batch张量。此时同一个batch中股票可能出现重复。例如这个batch中,可能同时包含stock1在2017/02/10~2017/03/09日的因子数据,以及stock1在2017/02/13~2017/03/10的因子数据,并把两者视作独立的样本,这显然有欠合理。
另外需要指出的细节是Qlib对于不同因子库的GAT模型路径配置不同。Qlib内置了Alpha158和Alpha360两类因子库,两者的GAT模型路径配置不同,分别为qlib.contrib.model.pytorch_gats_ts和qlib.contrib.model.pytorch_gats。原因在于两类因子库在计算特征时的数据组成结构不同:Alpha158的每一列为一个因子特征,而Alpha360的每一列是一个与时间%d相关的因子特征,比如前60列是关于CLOSE的时间序列特征,列名依次为[CLOSE59,CLOSE58,……,CLOSE0]。在正式送入模型前,需要采用不同数据预处理方式,将特征数据的batch转换成相同的[n_samples, step_len, d_feat]的大小形式。两个代码使用的GAT本质上是一致的,只是数据预处理方式有所区别。
多跳邻居实现
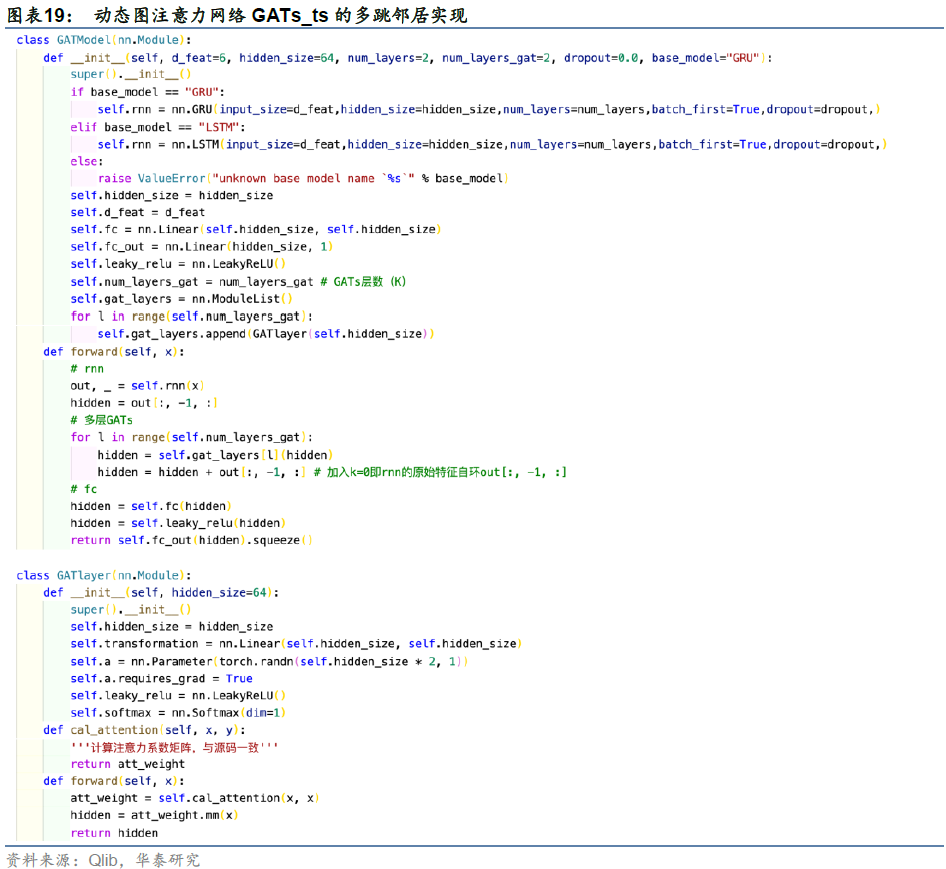
Qlib中GATs_ts源码仅实现了一层图注意力网络,即只考虑1跳邻居的关系嵌入。我们在Qlib源码基础上实现了K层GATs_ts模型,并用于后文中的回测,用来检验更远的节点特征能否提供额外的信息。例如K=2相当于对节点进行两跳的邻居聚合,即将邻居以及邻居的邻居聚合给自身。多跳邻居的代码实现如图19所示,在yaml配置文件中加入num_layers_gat(等价于层数K)的参数定义即可完成多跳邻居的训练。
图19代码中,首先定义图注意力层GATlayer类,在GATModel中通过循环堆叠num_layers_gat层即可得到多跳邻居的特征聚合。整个前向传播过程分为三步:rnn循环神经网络、多层GAT和fc全连接。
在前向传播中,每一层for循环完成self.gat_layers[l](hidden)特征聚合后,我们借鉴一种残差跳跃的方式(Chen et al., 2020):从初始层(k=0)进行残差连接。具体做法是在self.gat_layers[l](hidden)的基础上,加入k=0原始特征的自环out[:, -1, :],这是为了防止图神经网络的过平滑(Over Smoothing)问题,即随着层数增加,节点会学到图中全局信息,导致所有节点的特征趋于类似从而无法区分。
GATs_ts回测分析
测试流程
我们在Qlib平台上对动态图注意力网络模型GATs_ts进行选股回测,流程如下:
1. 数据获取
a) 获取Wind中的A股数据,按照华泰金工研报《人工智能40:微软 AI 量化投资平台 Qlib 体验》(2020-12-22)中dump_all 转换用户数据格式的方式,转换为Qlib的bin数据存储格式。
b) 股票池:沪深300成分股。
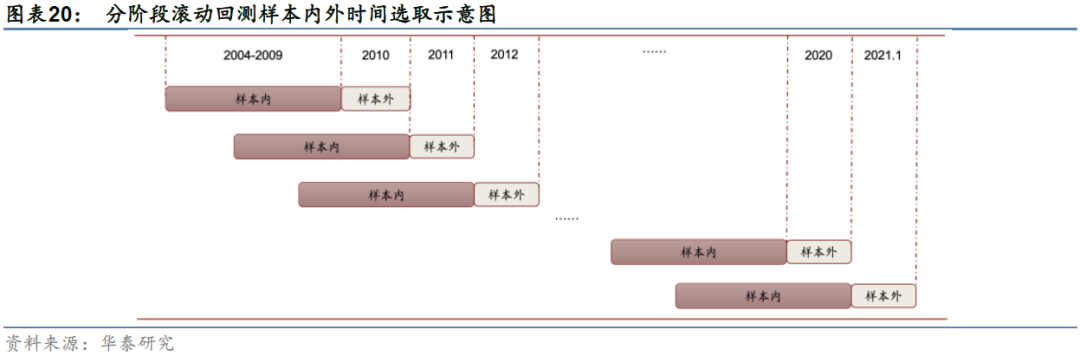
c) 回测区间:2010-01-04至2021-02-02,分12个阶段滚动回测,如下图所示。
2. 特征和标签提取:特征采用Qlib内置的因子库Alpha158vwap中的158个因子特征,将标签定义为t+2日vwap复权均价相对于t+1日vwap复权均价的涨跌幅,相当于t日收盘后发信号,t+1日以日内均价开仓,t+2日以日内均价平仓。
3. 特征预处理:
a) 训练集和验证集:首先剔除标签为缺失值的样本(Qlib的DropnaLabel类),再对标签进行截面标准化(Qlib的CSRankNorm类),即对每个截面的标签先转换为rank序数,最后Z分数标准化至标准正态分布。
b) 测试集:首先对特征进行标准化(Qlib的RobustZScoreNorm类),即对因子做稳健Z分数标准化,对原始数据减去中位数除以1.48倍MAD统计量,再将因子特征取值限制在-3到3之间(clip_outlier设置为True),最后将因子缺失值填充为0(Qlib的Fillna类)。
4. 数据集设置:训练集采用样本内数据的前五年,验证集采用样本内数据的最后一年,测试集采用接下来的样本外一年。
5. 样本内训练:使用自定义pytorch_gats_ts_layers.py的GATs类训练,GAT类调用了图19的GATModel类,即多层动态图注意力网络模型GATs_ts的实现。将回测区间按年份划分为12个子区间,因此需要配置相应的训练集区间进行滚动训练。
6. 验证集调参:训练过程中,当验证集上的评价分数在连续10轮迭代后都没有提升时,停止模型训练,选取验证集评价分数最高的一组参数作为模型的最优参数,用来对测试集进行预测。这里的评价分数使用Qlib中默认的方式,即均方误差的相反数。
7. 样本外测试和回测:
a) 得到最优参数后,进行模型预测得到测试集中每一天股票的预测收益率。
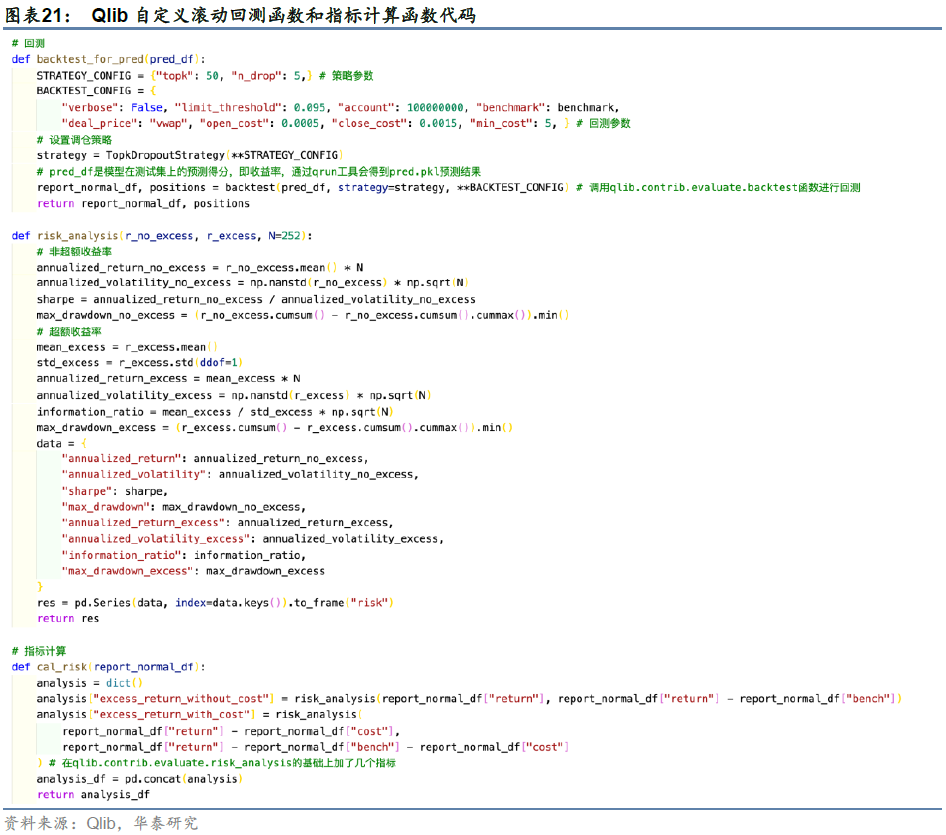
b) 由于Qlib开源部分还未配置滚动回测,我们编辑了12个yaml文件依次进行回测,分别得到2010年至2021年中每一年测试集上的预测收益率。我们将每年的pred.pkl(预测收益率结果)合并,再送入backtest_for_pred函数,进行2010~2021年的整体回测和报告输出。该回测函数和指标计算函数如图21所示。
c) 使用TopkDropout策略,每日持有topk=50只股票,同时每日卖出持仓股票中最新预测收益最低的n_drop=5只股票,买入未持仓股票中最新预测收益最高的n_drop=5只股票。买入每只股票的金额为95%的剩余现金除以需要购买的股票数量,95%是策略的一个可调参数,用来控制仓位。关于费率的设置,开仓交易费率为0.05%,平仓交易费率为0.15%,最小交易费用为5元(人民币)。
模型参数配置
我们将d_feat设置为158,使用Alpha158vwap因子库的所有特征进行训练;with_pretrain设置为False,即不预先给158个特征的数据训练一个LSTM网络;module_path设置为qlib.contrib.model.pytorch_gats_ts_layers,即我们的模型实现的位置;num_layers_gat为GATs_ts层数,后文中设置为1,2和3进行回测;其余参数的设置与Qlib中yaml配置上的保持一致,具体如下表所示。基准模型LSTM的参数请见附录。
单因子测试
IC值分析法
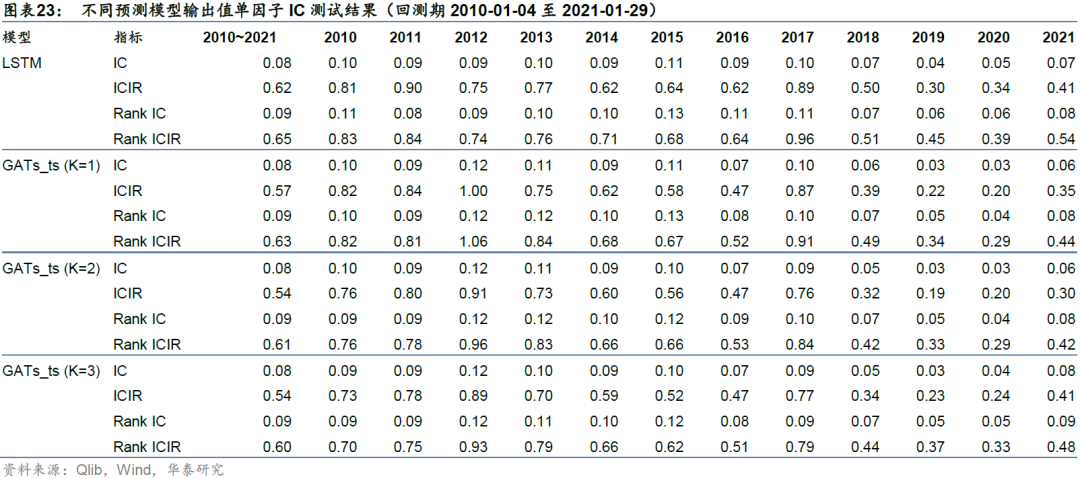
如果将模型的输出即预测收益率视为单因子,则可以对单因子向量与真实收益率向量进行IC值分析,得到不同预测模型在各年度IC均值、Rank IC均值、ICIR和Rank ICIR,衡量因子的有效性。预测模型包括1、2、3层GATs_ts以及基准模型LSTM。
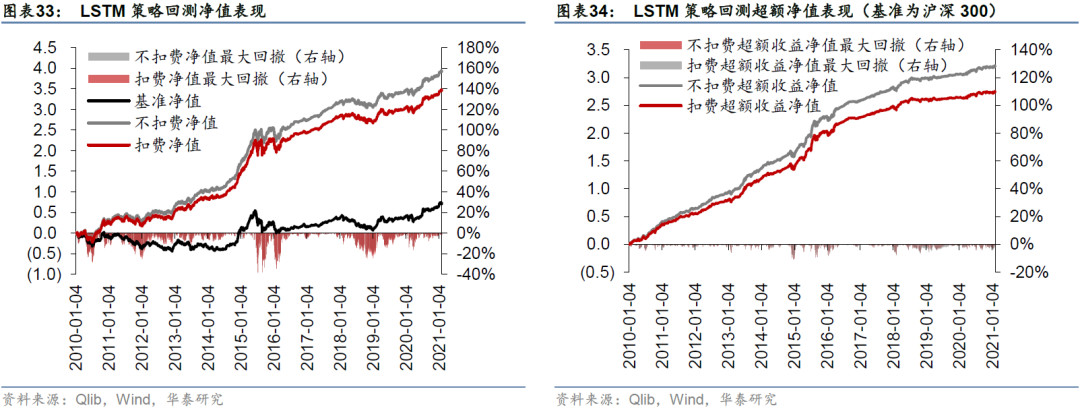
分年度和完整回测区间的汇总结果如表23,Rank IC日频序列值如图24和25所示。基准模型LSTM在回测期间的Rank IC均值和Rank ICIR分别为0.09和0.65,Rank IC值大于0的交易日占比为75.65%。对于GATs_ts模型,当图注意力层数为一层(即K=1)时,2010~2021年的Rank IC均值和Rank ICIR分别为0.09和0.63,Rank IC值大于0的交易日占比为74.76%。总的来看,LSTM模型的IC测试结果略优于GATs_ts模型,一层GATs_ts模型优于其它层数(K=2或3)的GATs_ts模型。
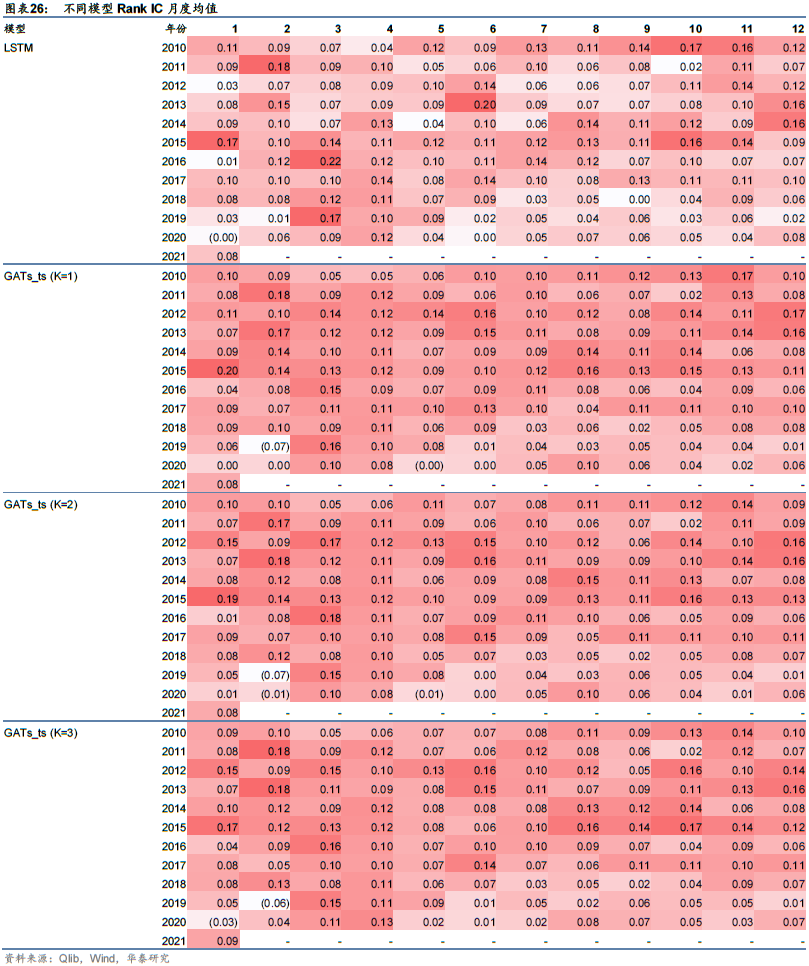
统计因子在各月上的表现,得到Rank IC月度均值,如表26所示。可以看到各模型月度Rank IC在2017年及以前相对稳定,在2018年及以后逐渐降低。这可能说明随着交易拥挤或者市场环境的变化,量价因子预测能力在逐渐失效。
单因子分层回测法
依照因子值对股票进行打分,构建投资组合回测,是最直观的衡量指标优劣的手段。测试模型的构建方法如下:
1. 股票池:沪深300成分股。
2. 回溯区间:2010-01-04至2021-01-29。
3. 换仓期:每个交易日。
4. 数据处理:将模型对股票收益率的预测值视作单因子,因子值为空的股票不参与分层。
5. 分层方法:将因子值由大到小排序,前20%为组合1,后20%为组合5,另有组合long-short为买入组合1、卖空组合5,组合long-average为买入组合1、卖空平均组合,这里的平均是指取每个交易日中所有股票的平均收益率。我们调用qlib.contrib. report.analysis_model.analysis_model_performance中的_group_return方法来计算各组合的累计收益。比如计算组合1时,首先将因子值降序排列,然后对每个交易日中前20%的股票收益率取均值作为该日的收益率,相当于等值购买前20%的股票。
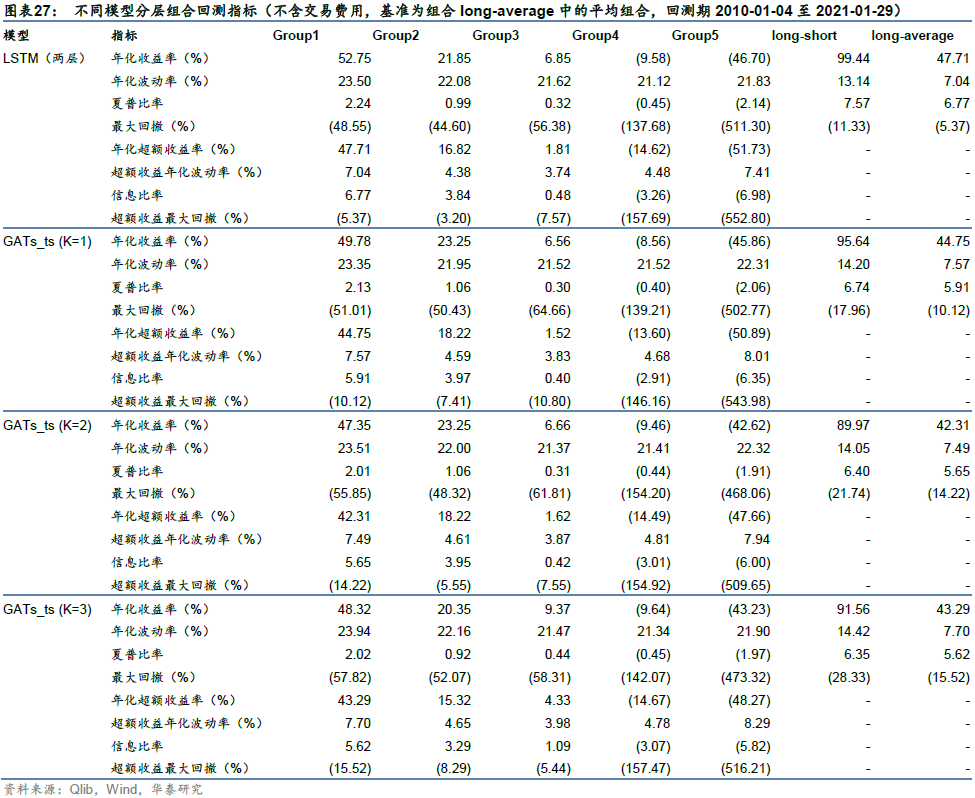
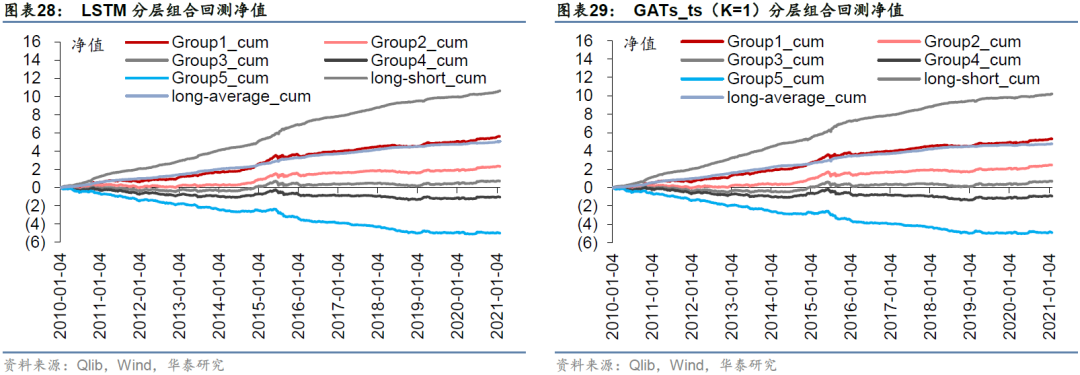
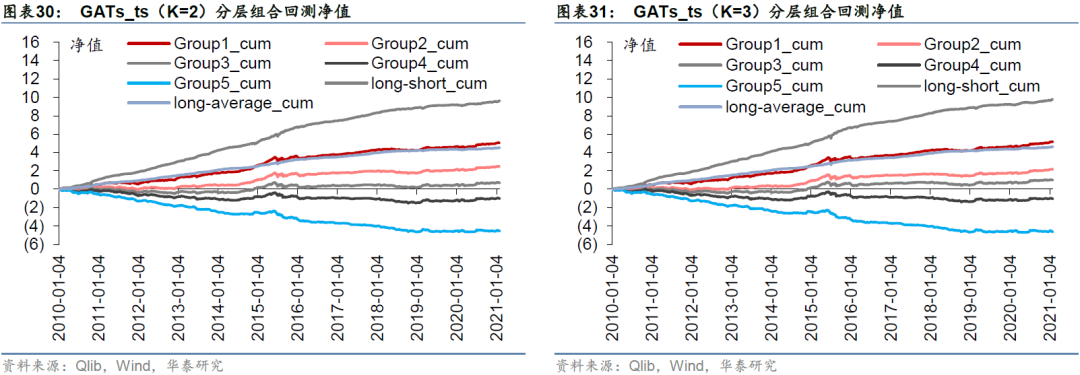
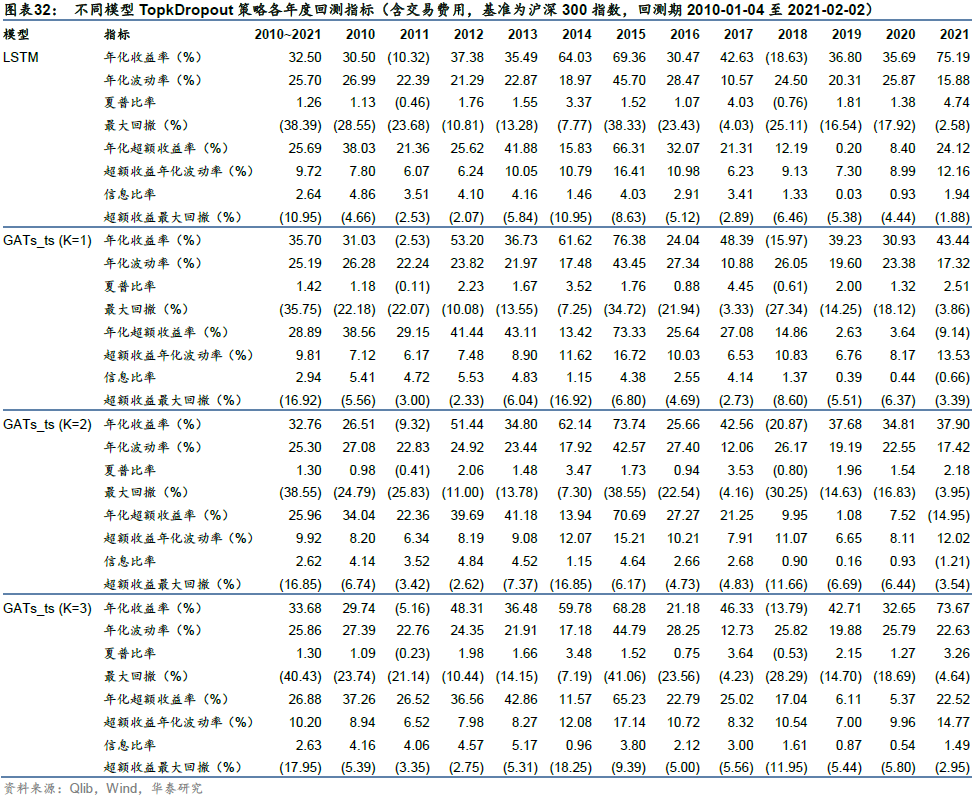
比较各预测模型单因子分层回测表现,LSTM和GATs_ts(K=1)多头组合Group1的年化超额收益率分别为47.71%和44.75%,多空组合long-short年化收益率分别为99.44%和95.64%,LSTM在收益能力上略胜一筹。一层GATs_ts优于其它层数(K=2或3)的GATs_ts模型。
构建组合策略及回测分析
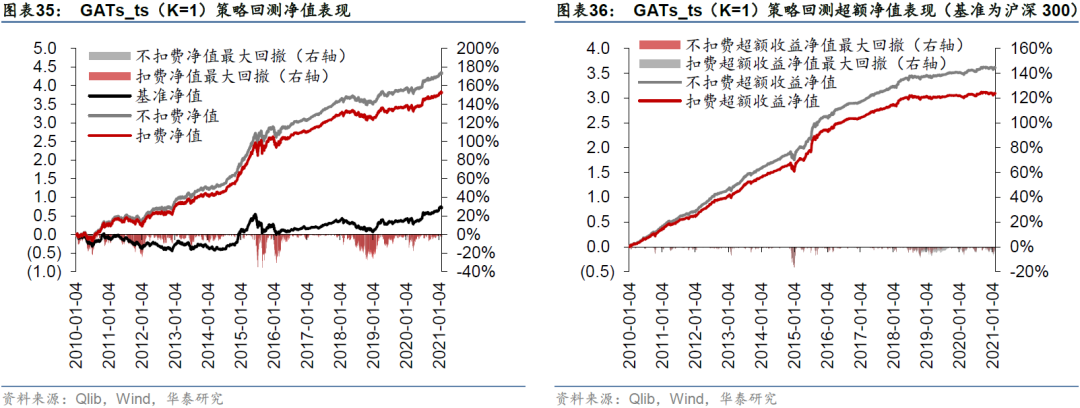
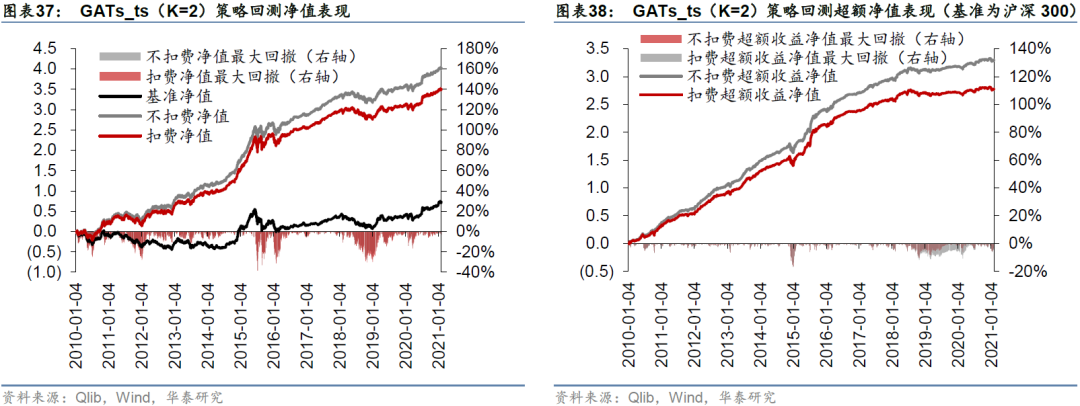
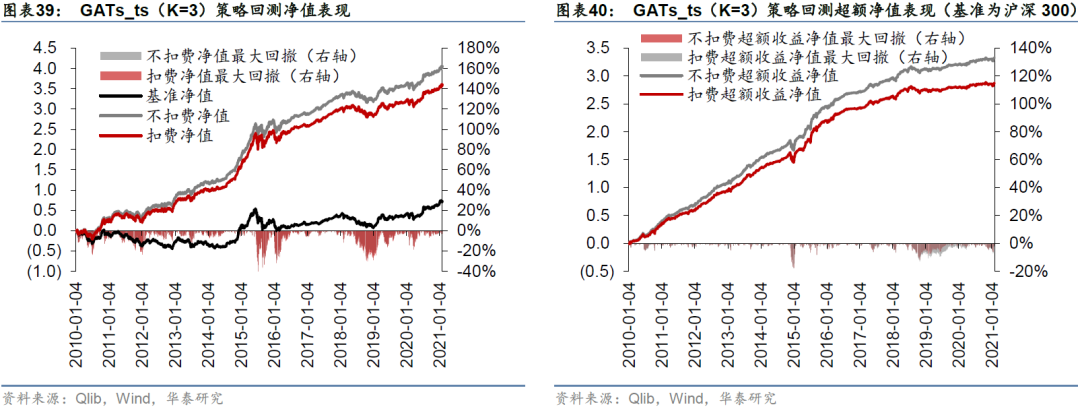
采用Qlib内置的TopkDropout策略,进行沪深300成分股内选股回测,组合构建方式已在前文详述,基准为沪深300指数。策略回测结果如表32所示。LSTM和一层GATs_ts模型在回测期间的年化超额收益率分别为25.69%和28.89%,夏普比率分别为1.26和1.42,信息比率分别为2.64和2.94,超额收益最大回撤分别为-10.95%和-16.92%。一层GATs_ts优于两层LSTM,也优于二层和三层GATs_ts模型。
一层GATs_ts在单因子测试上稍弱于LSTM,但在TopkDropout策略回测表现上优于LSTM,我们认为这可能是因为GATs_ts对整个股票池的预测能力稍逊,但对头部股票的预测能力较好。TopkDropout策略仅关注每个交易日预测得分最高的5只股票,即使对整个沪深300股票池预测能力一般,只要每日头部股票预测正确,仍能取得较高回测收益。
从分年度表现来看,各类型策略的超额收益表现出明显的衰减,我们认为这和模型使用的因子有关。Alpha158vwap因子库包含158个量价因子,这些因子是原始量价数据由基础运算符相连接得到的因子表达式。若传统量价出现拥挤,或者因为市场环境变化量价因子整体失效,那么GATs_ts模型也不可避免出现滑坡。GATs_ts只能解决因子合成的问题,无法解决因子失效问题。持续挖掘新Alpha因子仍是提升 Alpha策略表现的最好途径之一。
图33至图40分别展示四个模型在回测期间的净值和超额净值图。LSTM超额收益最大回撤发生在2014-11-24至2014-12-22,回撤幅度为-10.95%;GATs_ts(K=1)超额收益最大回撤发生在2014-11-24至2015-1-5,回撤幅度为-16.92%。GATs_ts控制风险能力略逊于LSTM。
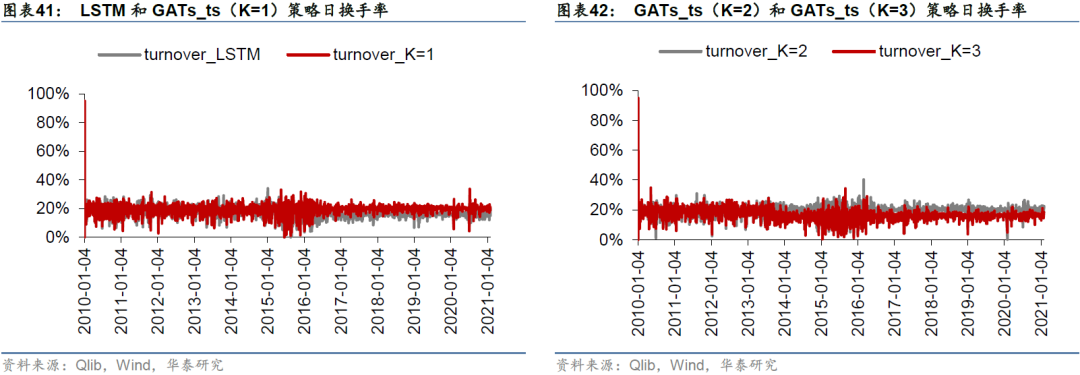
下面两张图展示四个模型日度策略换手率变化。2010至2014年日换手率在20%附近波动, 2015至2016年换手率波动较大,此后GATs_ts(K=1)和GATs_ts(K=2)模型的日换手率维持在20%附近,而LSTM和GATs_ts(K=3)模型的日换手率维持在15%附近。
总结与展望
为了方便读者更好地理解图神经网络的原理,我们花费了较长篇幅介绍图神经网络的思想和发展。总的来说,它由图信号理论和谱域图卷积发展而来,目前更多聚焦在空间域上的卷积方式,即将邻居节点的特征聚合给中心节点的方式来更新节点特征。
GCN、GraphSAGE和GAT是三种具有代表性的图神经网络。GCN仅适用于转导学习和无向图,即在未来有新节点加入时需要重新训练模型才能进行预测;GraphSAGE和GAT分别通过聚合器和注意力机制的方式将其扩展到归纳式学习,可用于新节点的预测,这对动态的股票市场来说是富有意义的。
随后我们以RSR框架为例,介绍图时空网络在量化多因子选股上的应用。RSR结合动态图的时间信息和横截面上股票间的关联信息,对收益率排序进行预测。相比于传统多因子选股仅考虑截面因子并且将股票视作独立样本的处理方式,图时空网络选股具有先进之处,它既考虑了因子的时间序列信息,也考虑了股票间的互相影响。
最后我们给出Qlib平台GATs_ts模型的实现方式,GATs_ts将GAT的注意力机制融入图时空网络选股框架。基于Qlib内置的Alpha158因子库,我们采用GATs_ts模型对沪深300成分股进行日收益率预测,随后构建日频调仓投资组合。回测期内(2010-01-04至2021-02-02),一层GATs_ts策略相对于基准沪深300指数的年化超额收益率为28.89%,信息比率为2.94,超额收益最大回撤为-16.92%,表现优于基准模型LSTM和多层GATs_ts。
本研究存在以下未尽之处:
1. 建图方法:GATs_ts采用GAT的全局注意力机制,即对股票之间关系进行隐式建模。如果对股票市场建立显式的股票间关系,再应用于选股策略,效果如何?这些关系类型可能具有语义特征,是否可以考虑知识图谱与图时空网络的结合?
2. 网络结构:GATs_ts首先将时序数据送入循环神经网络,随后对股票之间进行图卷积。与之相反,如果先对每个交易日的股票图进行图卷积,再将其送入循环神经网络中,从方法论上同样可行?
3. 策略构建:本研究直接调用Qlib中的Alpha158因子库及TopkDropOut选股策略,在沪深300成分股票池内采用日频调仓方式构建组合。模型在其它股票池、其它换仓频率、其它组合构建方式下表现如何?模型2018年后超额收益逐渐衰减,是否和因子失效有关,引入新因子能否起到改进效果?
图神经网络应用于量化策略是一个相对新颖的领域,上述问题都值得进一步探索。
参考文献
[1] Yang X, Liu W, Zhou D, et al. Qlib: An AI-oriented Quantitative Investment Platform[J]. arXiv preprint arXiv:2009.11189, 2020.
[2] Shuman D I, Narang S K, Frossard P, et al. The emerging field of signal processing on graphs: Extending high-dimensional data analysis to networks and other irregular domains[J]. IEEE signal processing magazine, 2013, 30(3): 83-98.
[3] 刘忠雨,李彦霖,周洋. 深入浅出图神经网络:GNN原理解析[M]. 北京:机械工业出版社,2020
[4] Tremblay N, Gonçalves P, Borgnat P. Design of graph filters and filterbanks[M]. Cooperative and Graph Signal Processing. Academic Press, 2018: 299-324.
[5] Bruna J, Zaremba W, Szlam A, et al. Spectral networks and locally connected networks on graphs[J]. arXiv preprint arXiv:1312.6203, 2013.
[6] Hammond D K, Vandergheynst P, Gribonval R. Wavelets on graphs via spectral graph theory[J]. Applied and Computational Harmonic Analysis, 2011, 30(2): 129-150.
[7] Defferrard M, Bresson X, Vandergheynst P. Convolutional neural networks on graphs with fast localized spectral filtering[J]. Advances in neural information processing systems, 2016, 29: 3844-3852.
[8] Chung F R K, Graham F C. Spectral graph theory[M]. American Mathematical Soc., 1997.
[9] Kipf T N, Welling M. Semi-supervised classification with graph convolutional networks[J]. arXiv preprint arXiv:1609.02907, 2016.
[10] Wu F, Zhang T, Souza Jr A H, et al. Simplifying graph convolutional networks[J]. arXiv preprint arXiv:1902.07153, 2019.
[11] Hamilton W, Ying Z, Leskovec J. Inductive representation learning on large graphs[C]. Advances in neural information processing systems. 2017: 1024-1034.
[12] Veličković P, Cucurull G, Casanova A, et al. Graph attention networks[J]. arXiv preprint arXiv:1710.10903, 2017.
[13] Feng F, He X, Wang X, et al. Temporal relational ranking for stock prediction[J]. ACM Transactions on Information Systems (TOIS), 2019, 37(2): 1-30.
[14] Chen M, Wei Z, Huang Z, et al. Simple and deep graph convolutional networks[C]. International Conference on Machine Learning. PMLR, 2020: 1725-1735.
风险提示
Qlib仍在开发中,部分功能未加完善和验证,使用存在风险。人工智能挖掘市场规律是对历史的总结,市场规律在未来可能失效。人工智能技术存在过拟合风险。
附录
基准模型LSTM参数设置如下表所示。
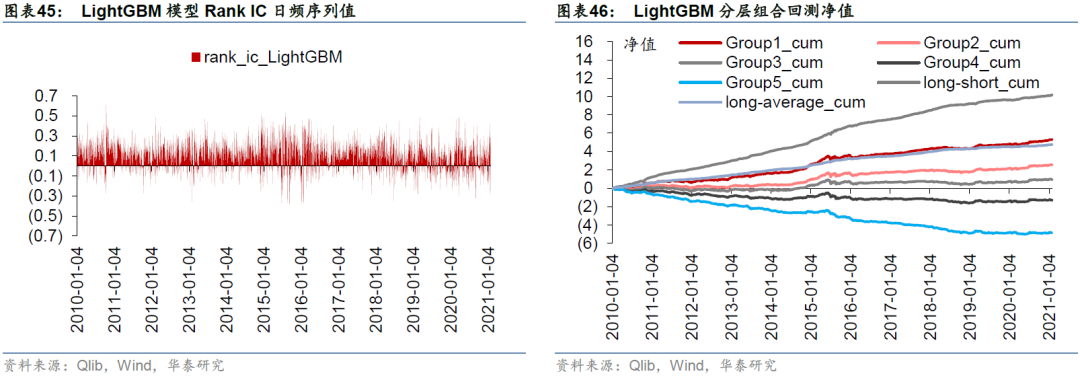
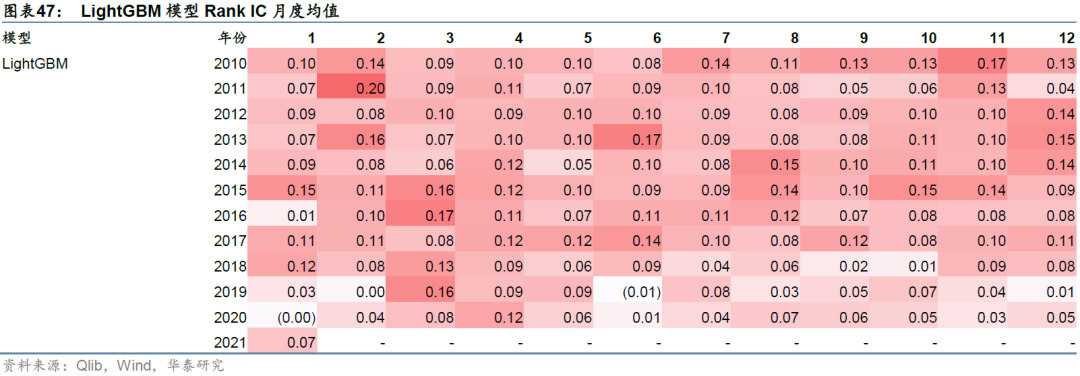
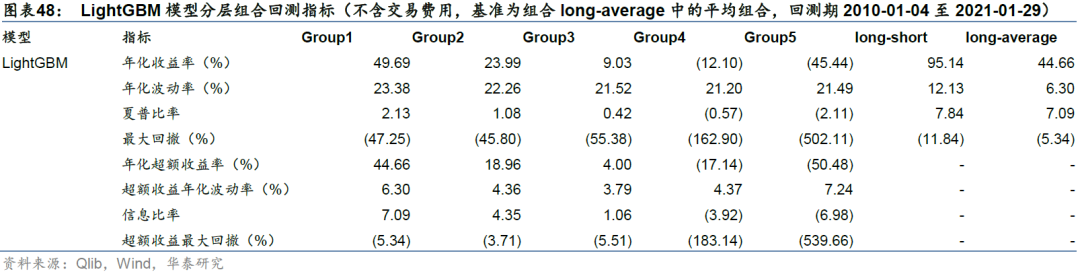
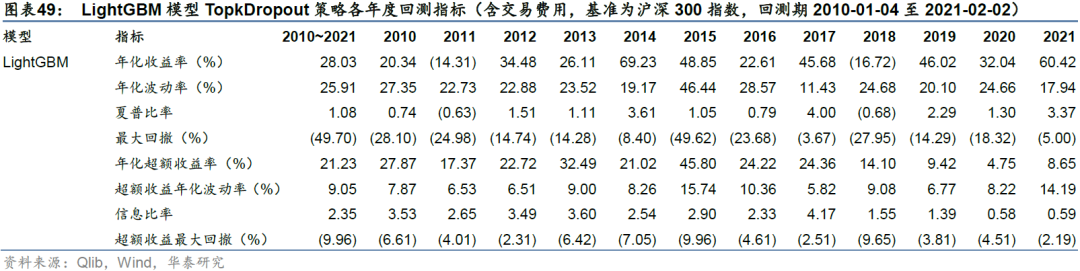
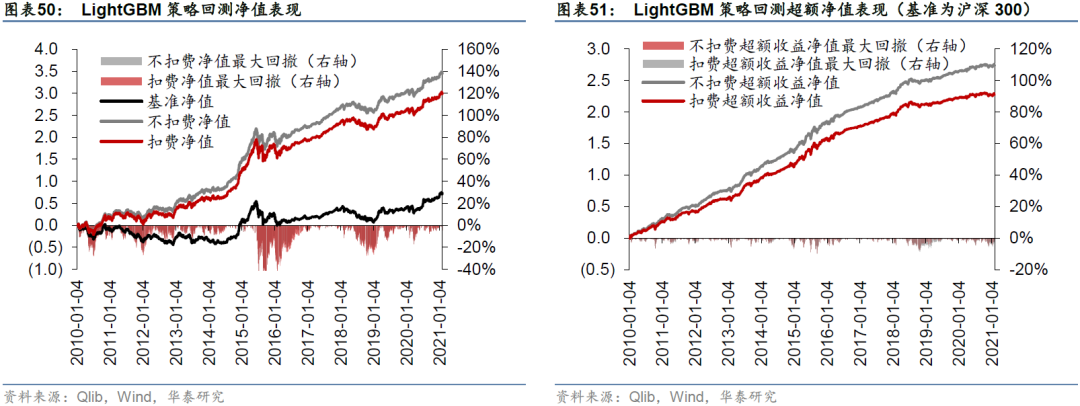
除GATs_ts和LSTM模型外,我们还测试了经典的决策树集成模型LightGBM,回测结果如下。
免责声明
公众平台免责申明
本公众平台不是
华泰证券
研究所官方订阅平台。相关观点或信息请以华泰证券官方公众平台为准。根据《证券期货投资者适当性管理办法》的相关要求,本公众号内容仅面向华泰证券客户中的专业投资者,请勿对本公众号内容进行任何形式的转发。若您并非华泰证券客户中的专业投资者,请取消关注本公众号,不再订阅、接收或使用本公众号中的内容。因本公众号难以设置访问权限,若给您造成不便,烦请谅解!本公众号旨在沟通研究信息,交流研究经验,华泰证券不因任何订阅本公众号的行为而将订阅者视为华泰证券的客户。
本公众号研究报告有关内容摘编自已经发布的研究报告的,若因对报告的摘编而产生歧义,应以报告发布当日的完整内容为准。如需了解详细内容,请具体参见华泰证券所发布的完整版报告。
本公众号内容基于作者认为可靠的、已公开的信息编制,但作者对该等信息的准确性及完整性不作任何保证,也不对证券价格的涨跌或市场走势作确定性判断。本公众号所载的意见、评估及预测仅反映发布当日的观点和判断。在不同时期,华泰证券可能会发出与本公众号所载意见、评估及预测不一致的研究报告。
在任何情况下,本公众号中的信息或所表述的意见均不构成对客户私人投资建议。订阅人不应单独依靠本订阅号中的信息而取代自身独立的判断,应自主做出投资决策并自行承担投资风险。普通投资者若使用本资料,有可能会因缺乏解读服务而对内容产生理解上的歧义,进而造成投资损失。对依据或者使用本公众号内容所造成的一切后果,华泰证券及作者均不承担任何法律责任。
本公众号版权仅为华泰证券股份有限公司所有,未经公司书面许可,任何机构或个人不得以翻版、复制、发表、引用或再次分发他人等任何形式侵犯本公众号发布的所有内容的版权。如因侵权行为给华泰证券造成任何直接或间接的损失,华泰证券保留追究一切法律责任的权利。本公司具有中国证监会核准的“证券投资咨询”业务资格,经营许可证编号为:91320000704041011J。
扫二维码,3分钟极速开户>>
01
/
“董小姐”这个关于家电的建议,国家部委回应了
02
/
中国婚姻报告2021:中国人结婚少了、结婚晚了、离婚多了
03
/
20余省市重点项目清单发布 总规模逾25万亿元
04
/
国务院:到2025年显著提升绿色产业比重 加快实施多行业绿色化改造
05
/
多国停飞777客机 波音再折翼
06
/
多地发力建设现代化都市圈 酝酿区域竞争新优势
07
/
缺芯断粮 华为手机如何坚守
08
/
"跑分平台"、虚拟货币成跨境洗钱新通道 平均每月"洗白"近100亿元
09
/
阿丽拉酒店关停 涉嫌建在饮用水保护区
10
/
贵州茅台领跌 白酒股怎么了
01
/
茅台暴跌:是见底信号 还是漫漫熊途?
02
/
深夜血洗 数字货币全线闪崩 发生了什么?美财长耶伦罕见发声
03
/
两大利空引发“黑色星期一”
04
/
涉嫌严重违纪违法同仁堂董事长被查 两年前因“过期蜂蜜”被处分
05
/
牛年头三日:A股风格大变 小票“牛”VS指数“熊”
06
/
创业板指数大跌4.4% 这些指标股成杀跌“元凶”
07
/
抱团行情瓦解还是中场休息?基金调仓顺周期、低估值及港股
08
/
“油茅”走下神坛?金龙鱼四季度净利下滑五成 或因套期保值损失
09
/
2月22日复盘:这个板块接力白酒成定局 主力重点出击3股
10
/
海通证券:三大原因影响节后抱团板块连续重挫
01
/
2月23日在售高收益银行理财产品
02
/
身为清华学霸曾攀附民生银行太太俱乐部 原吉林省金融办主任被查
03
/
每月洗白百亿:跑分平台、虚拟货币成跨境洗钱新通道
04
/
比特币巨幅波动 特斯拉贝莱德入局让炒家有恃无恐
05
/
建设银行因反洗钱一天被罚逾百万元 今年以来合计被罚709.5万元
06
/
仿冒银行"权行普惠"套路起底:交钱买级别 层层分红
07
/
商业银行互联网贷款监管升级 划定互联网贷款三条红线
08
/
广东海南上调小型银行房贷占比上限 利率水涨船高
09
/
互联网巨头加息、红包花式推理财 历史100%兑付引质疑
10
/
多家银行被冒充 甚至惊动公安厅发微博