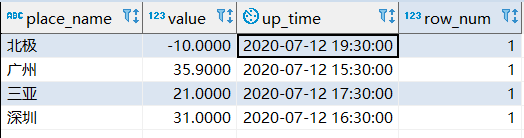
利用了一个case when then else end 用法来统计数量
select
dd.place_name,
sum(case when dd.value <= 0 then 1 else 0 end) as 低温天气,
sum(case when dd.value > 0 and dd.value < 25 then 1 else 0 end) as 正常天气,
sum(case when dd.value >= 25 then 1 else 0 end) as 高温天气
t_temperature dd
group by
dd.place_name
效果如下,因为没有过滤每个地方的最新数据,查出的是所有数据:
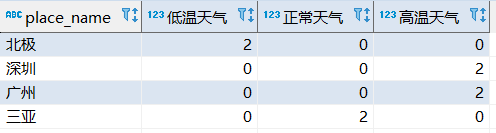
用需求1的结果来查询统计:
select
dd.place_name,
sum(case when dd.value <= 0 then 1 else 0 end) as 低温天气,
sum(case when dd.value > 0 and dd.value < 25 then 1 else 0 end) as 正常天气,
sum(case when dd.value >= 25 then 1 else 0 end) as 高温天气
select
select
tt.place_name,
tt.value,
tt.up_time,
row_number() over ( partition by tt.place_name
order by
tt.up_time desc) as row_num
t_temperature tt) aaa
where
aaa.row_num = 1) dd
group by
dd.place_name
效果如下:
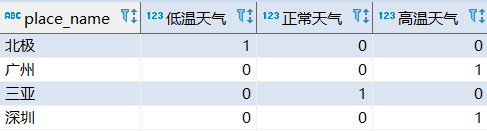
假如再嵌套一个sum统计,就能查出低温天气,正常天气,高温天气分别合计数量是多少了。
over,enjoy!
目录1. 背景2. 需求:3. 构建数据3.1 创建表结构:3.2 造数据4. 需求实现4.1 需求1的SQL语句4.2 需求2的SQL语句1. 背景比如气象台的气温监控,每半小时上报一条数据,有很多个地方的气温监控,这样数据表里就会有很多地方的不同时间的气温数据2. 需求:每次查询只查最新的气温数据按照不同的温度区间来分组查出,比如:高温有多少地方,正常有多少地方,低温有多少地方3. 构建数据3.1 创建表结构:-- DROP TABLE public.t_temperatureC
每条数据的编号:row_number()
分组排序:over(partition by 分组的字段 order by 排序的字段)
num=1:对分组后的数据获取第一条,也就是最新一条
SELECT * FROM (SELECT ROW_NUMBER() over(PARTITION BY code ORDER BY create_time DESC ) AS num, * FROM t_goods) aa WHERE 1 = 1
AND aa.num = 1 ORDER BY aa.create_time
FROM public.tb_attendance_model
WHERE create_time >= '2019-06-17 00:00:00.000000'
AND create_time < '2020-06-17 00:00:00.000000'
相同visitnumber有多条数据时,选择时间最新的一条数据。
select patientid,visitnumber,obssitename,findings,obsdiagtext,lastupdatedttm
, max(lastupdatedttm) over(partition by visitnumbe...
本文将对一个任意范围按ID分组查出每个ID对应的最新记录的CASE做一个极致的优化体验。 优化后性能维持在可控范围内,任意数据量,毫秒级返回,性能平稳可控。 比优化前性能提升1万倍。
有一张数据表,结构:
CREATE TABLE target_position (
target_id varchar(80),
time big...
今天在工作中,遇到一个业务:根据某个字段去重查询最新的记录列表,于是建了一张测试表(以下使用postgreSQL建表语句),并记录下三种不同类型数据库下的查询方式(oracle/postgreSQL/mysql)
DROP TABLE IF EXISTS "public"."t_group_member";
CREATE TABLE "public"."t_group_member" (
"id" int4 NOT NULL,
"group_id" varchar(255) COLLATE "pg_
- `timestamp`:存储日期和时间,带有时区信息。精度可以是毫秒,微秒或纳秒。
- `timestamptz`:与 `timestamp` 类似,但存储的是本地时间,并自动转换为 UTC 时间。
- `date`:存储日期,不包含时间和时区信息。
- `time`:存储时间,不包含日期和时区信息。精度可以是毫秒,微秒或纳秒。
- `interval`:存储时间间隔,可以表示两个时间点之间的差值。
你可以根据你的需要选择适当的时间数据类型。