

python小结18-numpy(二)ndarray计算、广播、方差、样本标准偏差、条件表达式

五、结构数组
它跟pandas的DataFrame有点类似。
x = np.array([['张三',25,165],['李四',20,175]])
print(x)
x.shape
x.dtype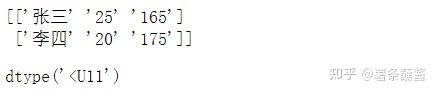
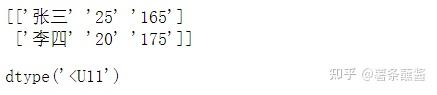
但是现在肯定算不上结构数组,这样设置,毕竟不能通过x['name']得到'张三'。
help上有一个介绍。
x = np.array([(1,2),(3,4)])
print(x)
print(x.shape)[(1,2),(3,4)],中间虽然有小括号括起来,但是结果仍然用[]输出。不作为结构数组。

但是一旦指定了列的名称。它的shape就不是(2,2)而是(2,)
x = np.array([(1,2),(3,4)],dtype=[('a','<i4'),('b','<i4')])
print(x)
print(x.shape)
print(x[0][0])
x['a']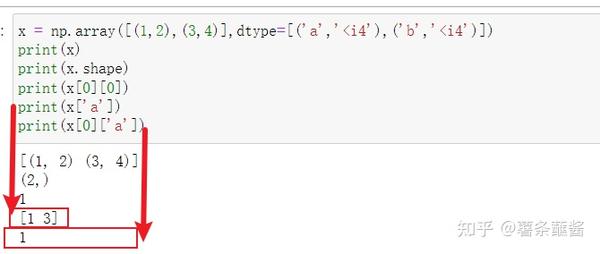
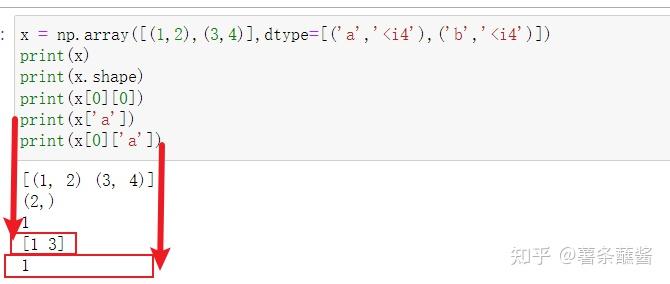
那么上面的np.array([['张三',25,165],['李四',20,175]])可以进行修改。
('张三',25,165)必须使用小括号。
x = np.array([('张三',25,165),('李四',20,175)], dtype=[('name','|U32'),('age','<i4'),('height','<f4')])
print(x)
print(x.shape)
print(x[0][0])
print(x['name'])
print(x[0]['name'])

当然,虽然有这种功能,但是没有pandas方便。只做介绍。
上面的('age','<i4')只有在处理字节流的时候才有用。<低位字节在前,小端模式,>高位字节在前,大端模式。
六、数组的元素级别计算及广播


a = np.array([[1, 2, 3], [4, 5, 6], [7, 8, 9]])
b = np.array([[11, 12, 13], [14, 15, 16], [17, 18, 19]])
print(a)
print(b)
a+b
c = a + b
print(c)
######或者
np.add(a,b,c)
print(c)
当对两个数组进行计算时, 会对对应的元素进行计算。
但是如果两个组数的形状不同时,会进行如下的广播处理:
①让所有输入数组都向着维数最多的数组看齐。shape中属性不足的部分都通过在前面加1补齐。
②输出数组的shape属性是输入数组的shape属性在各个轴上的最大值
③如果输出数组的某个轴的长度为1或与输出数组对应轴长度相同,这个数组就能够用来计算,否则出错。
④当输入数组的某个轴长度为1时,沿着此轴运算时都用此轴上的第一组的值。
虽然说起来很复杂,但是看例子就容易理解了。
a是1-9的3*3的矩阵:
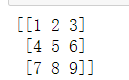
例子1:
那么a+1,就是a+3*3的全1的矩阵。
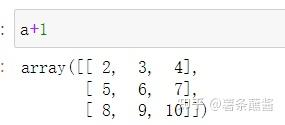
例子2:
那么a+[1,2,3],就是a+3*3的全是[1,2,3]的矩阵。
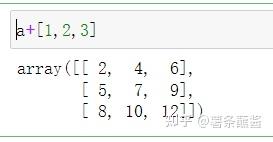
a的shape是(3,3),[1,2,3]的shape是(3,).根据第一条,变成shape是(1,3)。[[1,2,3]]
根据第三条,可以计算。
根据第四条,扩展到shape(3,3),也就是[[1,2,3],[1,2,3],[1,2,3]]
例子3:
a=np.array([[1, 2, 3], [4, 5, 6], [7, 8, 9]])
b=np.array([[1,2,3],[1,2,3]])
a+b
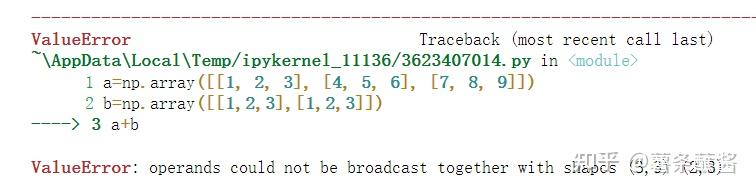
a的shape是(3,3),b的shape是(2,3)。根据第三条,不能计算。
例子4:
shape(1,3)的数组+shape(3,1))的数组

两个数组的维度都是2,所以结果也是2。根据结果的维度的长度是最大值。所以结果的shape是(3,3).
计算的时候,a、b根据第四条扩展规则。都用相同的值。
变成了。


案例:


七、repeat操作
在创建数组的时候,有时候附近的数字是有一定的规律的。可以使用repeat操作。
比如:将下面的a变到b,毕竟很多时候,一个一个写太麻烦了。
a = np.array([[1,2,3],[4,5,6]])
print(a)
b = np.array([[1,1,2,2,3,3],[1,1,2,2,3,3],[4,4,5,5,6,6],[4,4,5,5,6,6]])