

对一次漫长的性能调优的反思总结(spring事务、druid)

对应用的某个主要接口进行压测,从发现瓶颈到不断优化,经历较为漫长的时间,用这篇文章记录下过程中的心得与感悟。
刚开始看到阿里云的edas有比较完整的devops跟监控功能,于是把应用部署到上面进行测试,同时也埋下了第一个“坑”。
压测的接口不复杂,包含几个数据库操作,中间夹着一次http调用,不过这次的调优只在这几次数据库操作上。
第一个版本:
100RPS下大部分响应时间在1.8s左右,观察内部调用链耗时,耗时较多的两个调用是:
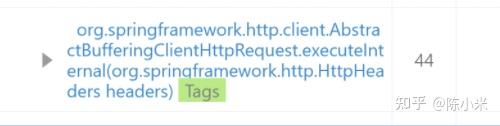
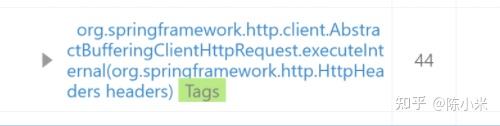


前者是http调用包含网络耗时先忽略,后者是向druid获取数据库连接的时间,表示有较长的时间无法获取连接,有不少能够优化的空间,当时想到的两个原因有:
- 连接池被耗尽,需加大连接池的数量;
- 连接被占用时间过长,回收慢;
这里我没有选择直接调大连接池(直觉是够大的),而是去看了一下有哪些地方连接占用时间过长,于是开启了漫长的DEBUG之路,沿着代码的路径,看每处数据库调用之后,连接有没有被归还(在DruidPooledConnection.close断点),结果发现一处用@Transaction标记的事务方法所开启的数据库连接,在方法返回后,并没有马上关闭连接,而是在Controller接口层方法结束时才关闭连接,这种生命周期令我想起Spring的 OpenSessionInView模式 (在整个接口的生命周期保持数据库的连接,为了hibernate session的延迟加载)。
反直觉的是,为什么只有@Transaction方法开启的数据库连接应用了OSIV模式,其他的数据库调用没有呢?又是一段漫长的源码debug, 原来mybatis默认会在数据库操作完成后关闭连接,除非当前事务上下文(TransactionSynchronizationManager)存在事务 ,就这样@Transaction开启的事务就会被mybatis检测到,从而放弃关闭连接,而普通的非事务数据库操作则还是会关闭连接,则其实是违背了OSIV了,从这里也感受到mybatis与spring的事务管理器并没有很好地适配。
第一次优化:
根据上面的猜测,尝试把OSIV禁用后,从新部署并压测,平均响应时间减少了0.2s~0.3s。到这里觉得应该暂时发现不了什么新的性能问题了(也是对接口的正常响应时间没什么概念),于是暂告一段落。
踩坑:
继上次优化之后,准备重新再看看有哪里能继续优化,于是重新部署了一遍再压测,这次响应时间竟然多了几倍?多达4~5s!用控制变量法与上次相比,代码是一样的、运行环境应该也是一样的(坑、 错1 ),那就只有数据库、下游系统与上次不一样。而查看调用链耗时,显示瓶颈仍然是在获取数据库连接上。
那么是什么导致获取连接慢呢?连接被占用过长时间导致连接池耗尽?如果是 (错2) ,那是什么占用了连接?
难道是积累了一些测试数据,导致数据库响应慢了? (错3) 把测试数据清了重测,没有改善。
难道与数据库的通讯达到了网速上限导致查询阻塞? (错4) 怎么知道是不是达到了网速上限?性能监控上有显示平均网速情况,但是不能知道有没有触发网速上限,于是很麻烦地在容器内部比较了不同负载下的流量情况,也排除了这个可能。
想起druid可以配置监控,于是把监控打开(中间掉坑花不少时间)。虽然监控显示的“连接持有时间分布”、“事务时间分布”都指出确实有不少连接是被长时间占用,(而在“连接池的活跃峰值”这一项指标上没有到达限制值,其实指出了没有耗尽连接池,但被我暂时忽略了 (错5) )
到这里已经意识到凭自己的知识很能排查出来原因,尝试在网上搜索相关的情况,发现一篇有赞开发的 文章 比较符合我这里的情况,他们用tcpdump的方式排查与数据库的连接情况,其实之前自己也想过用这种方式来排查,但是嫌麻烦+不知道怎么过滤单条tcp连接没有实践 (错6) ,既然在文章这里看到了,就实践了一下,把与数据库的tcp数据库dump下来分析:
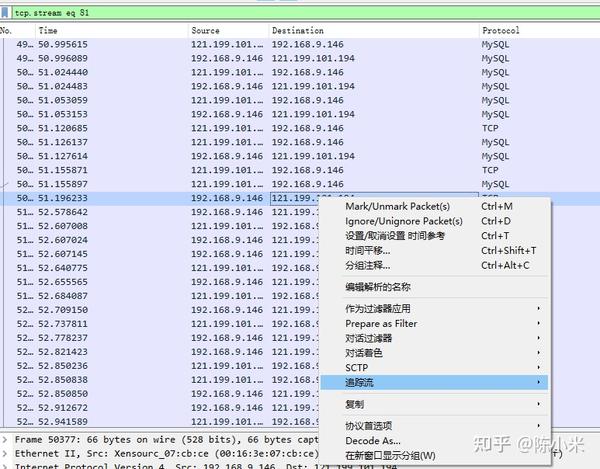
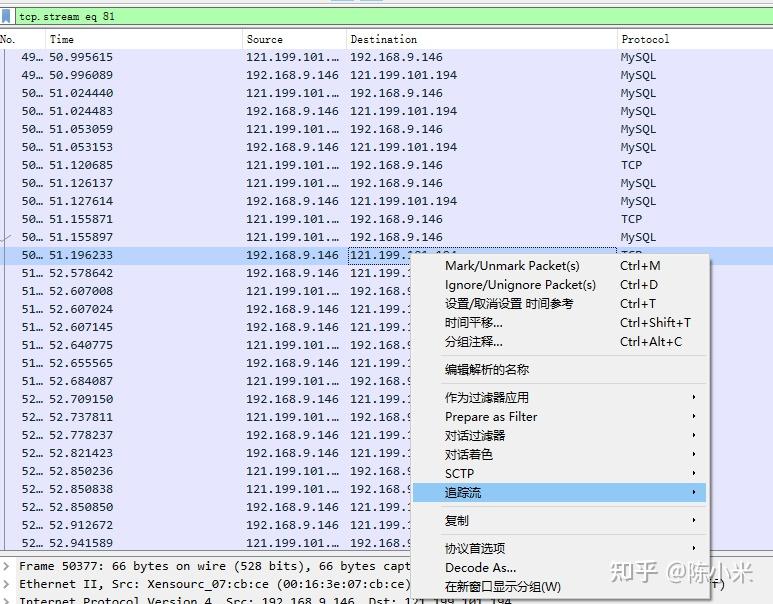
抽样分析结果是,数据库的应答是正常的,没有太大的延迟,至少可以排除外部数据库的原因了,那么问题只能出在代码内部了。
按照那篇文章的说法,问题出在druid本身,把druid换成hikari后,性能依稀记得有大概40%的提升。
但即使是40%的提升,跟第一次优化的1.8s仍然有不少差距。所以这种差距是来自哪里?
其实之前在排查网速原因的时候才发现可能部署时候CPU/内存会不一样(用到了不同规格的容器),但是查看CPU的使用率只在20·~30%(平均),所以一直不觉得CPU是性能瓶颈,但既然问题排查到了druid本身,还是尝试把CPU加大压测一下。
果然,响应时间终于回到了一点多秒。
回顾这一次性能排查,中间翻了很多错误,导致整个过程过于漫长,不过本来就是抱着学习的心态,重要的是总结犯错的原因,下面列出了一些自认为错误的排查方向进行复盘:
- 错1: 对aliyun/k8s不熟悉,没有想到部署时设定的“预分配CPU”值会决定最终容器被分配的CPU资源,同时缺少对CPU等基本资源的关注;
- 错3、错4、错6: 如果尽早使用tcpdump+wireshark分析的方式,应该能更早地排查掉外部依赖与网络相关的嫌疑,对wireshark的使用不够熟练。
- 错2、错5: 先入为主认为 获取连接慢==连接池耗尽,实际上并没有连接池耗尽的证据,甚至druid监控已经给出了连接池没有耗尽的证据、不过等式成立是建立在druid是没问题的前提下,也是一种对使用的框架过于信赖。
总结与反思:
后续换了另个一个应用监控系统datadog,虽然没有展示调用链耗时图,但是通过profile直接分析出了druid的问题:旧版本使用8.0-mysql-connector的时候频繁“吞掉”ClassNotFoundException导致锁等待耗时严重、公平锁存在性能隐患。。。
刚开始的时候比较依赖调用链耗时图,实际上当性能异常的方法埋在比较深的位置的时候(如上面的jdk方法),调用链耗时图只能给出一个大概的位置(getConnection)。这时候与其盲目猜测,更应该关注其他指标,比如 CPU耗时 、 锁等待时间 、 被吞掉的异常 。这时候有一个靠谱的应用监控系统也能达到事半功倍的效果。
另一点是对于CPU利用率的解读,事实上在第一次踩坑的时候CPU利用率并没有达到100%,导致我误以为跟CPU没有关系,但实际上CPU性能不足是如何加剧锁等待,反过来导致CPU闲置的,估计要等后续慢慢研究了。
——————————————
4.1更新:
重新研究了下,之前CPU利用率没到100%的原因大概率是因为本来分配就是0.25个CPU,监控中显示的CPU利用率最大只有25%,其实就相当于已经到达了容器内部CPU的瓶颈了。。。
只能说这也算是对k8s、操作系统的不熟悉造成的错误。。