try {
String[] cmd = new String[] { "/bin/sh", "-c", "/opt/software/datax/bin/datax.py ./steamSqlServerMysql.json" };
Process ps = Runtime.getRuntime().exec(cmd);
BufferedReader br = new BufferedReader(new InputStreamReader(ps.getInputStream()));
StringBuffer sb = new StringBuffer();
String line;
while ((line = br.readLine()) != null) {
sb.append(line).append("\n");
String result = sb.toString();
logger.info(result);
} catch (Exception e) {
logger.error("----error-----");
e.printStackTrace();
如果觉得有帮助的话给个免费的点赞吧,Thanks♪(・ω・)ノ
异构数据库数据同步工具DataX教程,安装、数据同步、java执行
前言DataX 是阿里巴巴集团内被广泛使用的离线数据同步工具/平台,实现包括 MySQL、Oracle、SqlServer、Postgre、HDFS、Hive、ADS、HBase、TableStore(OTS)、MaxCompute(ODPS)、DRDS 等各种异构数据源之间高效的数据同步功能。DataX本身作为数据同步框架,将不同数据源的同步抽象为从源头数据源读取数据的Reader插件,以及向目标端写入数据的Writer插件,理论上DataX框架可以支持任意数据源类型的数据同步工作。同时DataX插件
Maxwell:异构数据源实时同步工具
文章目录Maxwell:异构数据源实时同步工具1、概述2、原理解析2.1 Mysql主从复制3、Maxwell安装部署4、增量数据同步5、历史数据全量同步5.1 Maxwell-bootstrap
Maxwell:实时监控Mysql数据库的数据变更操作(包括insert、update、delete),并将变更数据以 JSON 格式发送给 Kafka、Kinesi等流数据处理平台。
Maxwell的工作原理是实时读取MySQL数据库的二进制日志(B
一、dataX概览
1.1 DataX
DataX 是阿里巴巴集团内被广泛使用的离线数据同步工具/平台,实现包括 MySQL、SQL Server、Oracle、PostgreSQL、HDFS、Hive、HBase、OTS、ODPS 等各种异构数据源之间高效的数据同步功能。
1.2 Features
DataX本身作为数据同步框架,将不同数据源的同步抽象为从源头数据源读取数据的Reader插件,以及向目标端写入数据的Writer插件,理论上DataX框架可以支持任意数据源类型的数据同步工作。同时DataX插
如果想实现增量同步,就需要使用where和数据库中的时间字段来判断近期添加和修改的代码。
如果需要修改已有行数据,如果写入数据库为mysql,可以把写入模式改为update
但是公司需要使用sqlserver数据库,该插件对sqlserver不支持writeMode,所示使用sqlserver提供的触发器。判断当前id是否存
DataX 安装及使用
文章目录DataX 安装及使用一、DataX快速入门1.1、DataX概述及安装**概述**DataX安装配置1.2、DataX使用案例
一、DataX快速入门
1.1、DataX概述及安装
DataX 是阿里巴巴集团内被广泛使用的离线数据同步工具/平台,实现包括 MySQL、
Oracle、SqlServer、Postgre、HDFS、Hive、ADS、HBase、TableStore(OTS)、
MaxCompute(ODPS)、DRDS 等各种异构数据源之间高效的数据同步
DataX的安装及使用
文章目录DataX的安装及使用DataX的安装DataX的使用stream2stream编写配置文件stream2stream.json执行同步任务执行结果mysql2mysql编写配置文件mysql2mysql.json执行同步任务mysql2hdfs编写配置文件mysql2hdfs.jsonhbase2mysqlmysql2hbasemysql2Phoenix在Phoenix中创建STUDENT表编写配置文件MySQLToPhoenix.jsonHDFSToHBase
DataX
在新系统中设置定时任务需要实时把客户系统中的新数据及时同步过来。
1.根据客户提供的接口(参数上必带页码和页面容量),在本系统中采用Http的Post请求方式获取接口数据。
2.由于客户提供的接口必带页码和页面容量,因此会涉及到
1.设置定时任务。
2.采用Http的Post方式获取接口数据。
3.涉及多页数据采用递归方
方法一、直接下载DataX工具包:DataX下载地址
下载后解压至本地某个目录,进入bin目录,即可运行同步作业:
$ cd {YOUR_DATAX_HOME}/bin
$ python datax.py {YOUR_JOB.json}
自检脚本:
python {YOUR_DATAX_HO
SpringBoot升级2.4.0所出现的问题:When allowCredentials is true, allowedOrigins cannot contain the specia
62738



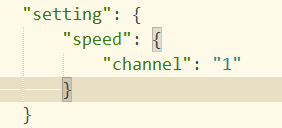
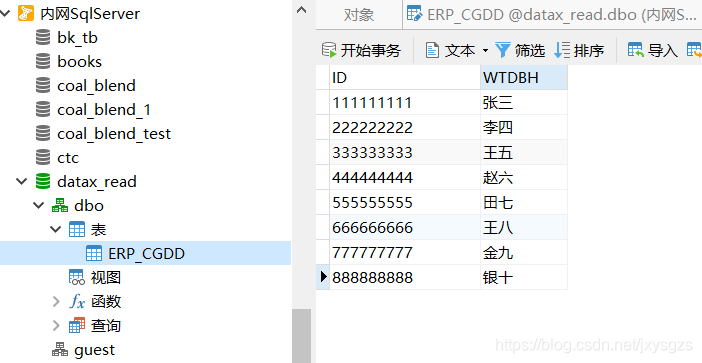
 2. 进入
2. 进入
