File "/home/me/ai/FlagAI/flagai/model/predictor/aquila.py", line 41, in aquila_generate
next_token = sample_top_p(probs, top_p)
File "/home/me/ai/FlagAI/flagai/model/predictor/aquila.py", line 84, in sample_top_p
next_token = torch.multinomial(probs_sort, num_samples=1)
RuntimeError: probability tensor contains either `inf`, `nan` or element < 0):
输入:
{“prompt”:“冒泡排序算法代码”}
输出:
下面是冒泡排序的 Python 代码实现:
def bubble_sort(array):
n = len(array)
# 遍历所有数组元素
for i in range(n):
# 最后 i 个元素不需要遍历
for j in range(n-i-1):
# 如果当前元素大于下一个元素,则交换它们
if array[j] > array[j+1]:
# 交换元素
array[j], array[j+1] = array[j+1], array[j]
return array
输入:
{“prompt”:“用golang实现冒泡排序算法”}
报错输出:
prompt is 用golang实现冒泡排序算法
INFO: 127.0.0.1:41664 - "POST / HTTP/1.1" 500 Internal Server Error
ERROR: Exception in ASGI application
Traceback (most recent call last):
File "/home/me/ai/FlagAI/venv/lib/python3.10/site-packages/uvicorn/protocols/http/h11_impl.py", line 428, in run_asgi
result = await app( # type: ignore[func-returns-value]
File "/home/me/ai/FlagAI/venv/lib/python3.10/site-packages/uvicorn/middleware/proxy_headers.py", line 78, in __call__
return await self.app(scope, receive, send)
File "/home/me/ai/FlagAI/venv/lib/python3.10/site-packages/fastapi/applications.py", line 282, in __call__
await super().__call__(scope, receive, send)
File "/home/me/ai/FlagAI/venv/lib/python3.10/site-packages/starlette/applications.py", line 122, in __call__
await self.middleware_stack(scope, receive, send)
File "/home/me/ai/FlagAI/venv/lib/python3.10/site-packages/starlette/middleware/errors.py", line 184, in __call__
raise exc
File "/home/me/ai/FlagAI/venv/lib/python3.10/site-packages/starlette/middleware/errors.py", line 162, in __call__
await self.app(scope, receive, _send)
File "/home/me/ai/FlagAI/venv/lib/python3.10/site-packages/starlette/middleware/exceptions.py", line 79, in __call__
raise exc
File "/home/me/ai/FlagAI/venv/lib/python3.10/site-packages/starlette/middleware/exceptions.py", line 68, in __call__
await self.app(scope, receive, sender)
File "/home/me/ai/FlagAI/venv/lib/python3.10/site-packages/fastapi/middleware/asyncexitstack.py", line 20, in __call__
raise e
File "/home/me/ai/FlagAI/venv/lib/python3.10/site-packages/fastapi/middleware/asyncexitstack.py", line 17, in __call__
await self.app(scope, receive, send)
File "/home/me/ai/FlagAI/venv/lib/python3.10/site-packages/starlette/routing.py", line 718, in __call__
await route.handle(scope, receive, send)
File "/home/me/ai/FlagAI/venv/lib/python3.10/site-packages/starlette/routing.py", line 276, in handle
await self.app(scope, receive, send)
File "/home/me/ai/FlagAI/venv/lib/python3.10/site-packages/starlette/routing.py", line 66, in app
response = await func(request)
File "/home/me/ai/FlagAI/venv/lib/python3.10/site-packages/fastapi/routing.py", line 241, in app
raw_response = await run_endpoint_function(
File "/home/me/ai/FlagAI/venv/lib/python3.10/site-packages/fastapi/routing.py", line 167, in run_endpoint_function
return await dependant.call(**values)
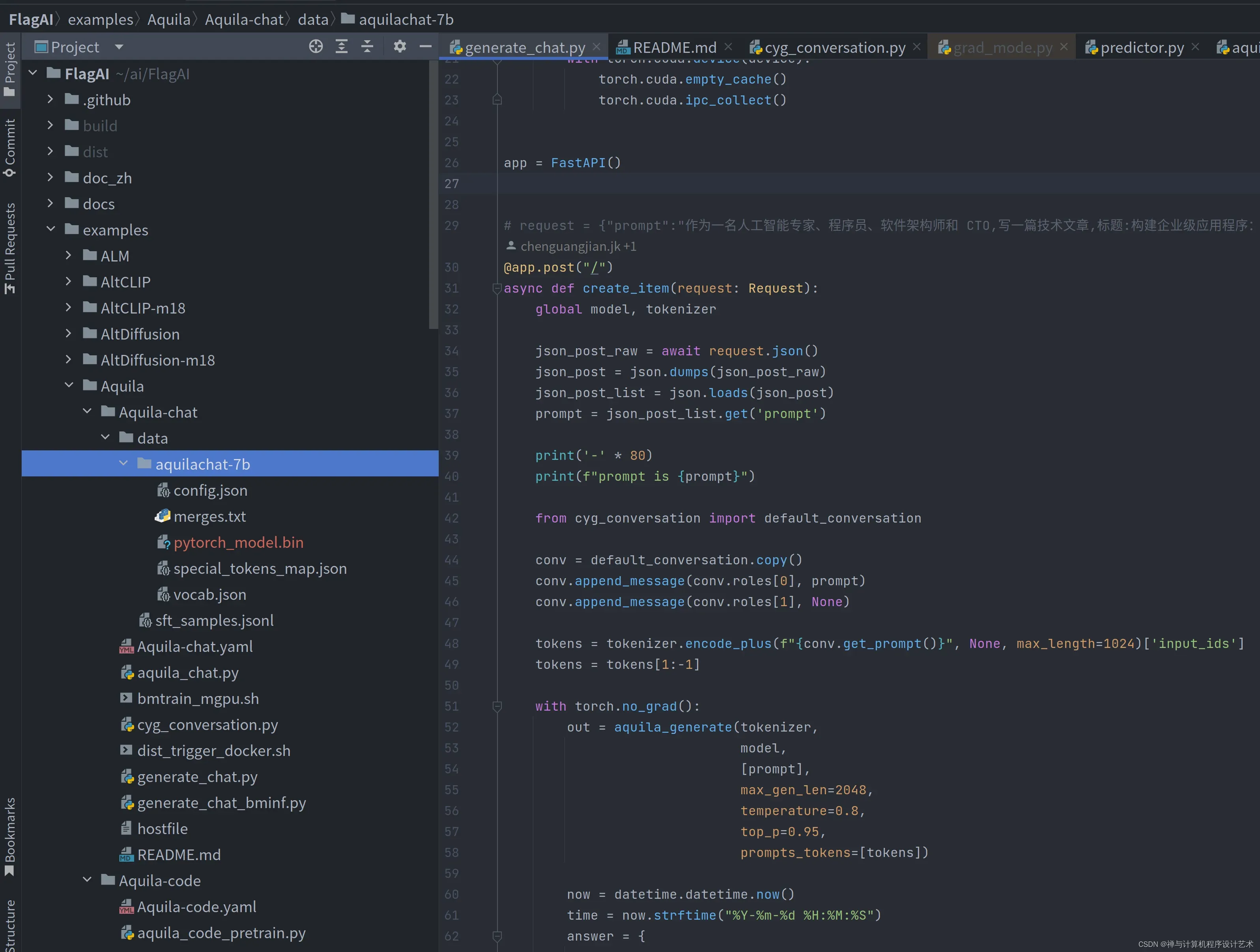
File "/home/me/ai/FlagAI/examples/Aquila/Aquila-chat/generate_chat.py", line 52, in create_item
out = aquila_generate(tokenizer,
File "/home/me/ai/FlagAI/flagai/model/predictor/aquila.py", line 41, in aquila_generate
next_token = sample_top_p(probs, top_p)
File "/home/me/ai/FlagAI/flagai/model/predictor/aquila.py", line 84, in sample_top_p
next_token = torch.multinomial(probs_sort, num_samples=1)
RuntimeError: probability tensor contains either `inf`, `nan` or element < 0
AquilaChat 快速开始
环境依赖安装
python ./setup.py install
# Licensed under the Apache License, Version 2.0 (the "License")
from setuptools import find_packages, setup
setup(
name="flagai",
version="v1.7.1",
description="FlagAI aims to help researchers and developers to freely train and test large-scale models for NLP/CV/VL tasks.",
long_description=open("README.md", encoding="utf-8").read(),
long_description_content_type="text/markdown",
author="FlagAI-Open",
author_email="open@baai.ac.cn",
url="https://github.com/FlagAI-Open/FlagAI",
packages=find_packages(exclude="tests"), # same as name
license="Apache 2.0",
include_package_data=True,
python_requires=">=3.8",
install_requires=[
'nltk==3.6.7',
'sentencepiece==0.1.96',
'boto3==1.21.42',
'pandas==1.3.5',
'jieba==0.42.1',
'scikit-learn==1.0.2',
'tensorboard==2.9.0',
'transformers==4.27.1',
'datasets==2.0.0',
'setuptools==66.0.0',
'protobuf==3.19.6',
'ftfy == 6.1.1',
'Pillow >= 9.3.0',
'einops == 0.3.0',
'diffusers == 0.7.2',
'pytorch-lightning == 1.6.5',
'taming-transformers-rom1504 == 0.0.6',
'rouge-score == 0.1.2',
'sacrebleu == 2.3.1',
{
“response”: “A chat between a curious human and an artificial intelligence assistant. The assistant gives helpful, detailed, and polite answers to the human’s questions.###Human: 怎样才算是优秀的技术人:理解技术的基本原则、本质和发展演化史,写一篇文章,分章节.10000字.###Assistant: 优秀的技术人应该具备以下三个方面的能力:1. 理解技术的基本原则和技术本质:优秀的技术人应该能够理解技术的的基本原则和本质,包括计算机科学、编程语言、算法和数据结构等。他们应该能够掌握各种技术的优缺点和应用场景,并能够根据需求选择合适的语言和工具。2. 编写高质量的技术代码:优秀的技术人应该具备编写高质量的技术代码的能力,包括代码的可读性、可维护性和可扩展性等。他们应该能够熟练掌握各种编程语言和开发工具,并且能够根据项目的需求进行合理的选择和运用。3. 学习和适应新技术:优秀的技术人应该能够不断学习新技术和新工具,并根据项目的需求进行学习和适应。他们应该能够跟踪技术的发展趋势,并根据技术的发展方向进行学习和实践。除此之外,优秀的技术人还应该具备团队合作和沟通能力,能够与团队成员和良好的协作,并能够有效地与客户进行沟通和协调。总之,优秀的技术人应该具备全面的能力和素质,能够在项目中发挥重要的作用,并为技术的发展做出贡献。”,
“status”: 200,
“time”: “2023-06-13 02:45:51”
}
Create a new directory named
aquilachat-7b
inside
./checkpoints_in
. Place the fine-tuned checkpoint and all other files from the original
aquilachat-7b
model, including
config.json
,
mergex.txt
,
vocab.json
, and
special_tokens_map.json
, into this directory.
Step 2: 修改参数/ Modify Parameters
cd /examples/Aquila/Aquila-sft
配置
hostfile
文件, 参考这里 ; Configure the
hostfile
file, refer to here
配置
bmtrain_mgpu.sh
文件, 将
SCRIPT_FILE
改成
aquila_sft.py
; configure the
bmtrain_mgpu.sh
file, change
SCRIPT_FILE
to
aquila_sft.py
(可选) 在
Aquila-sft.yaml
文件里更改参数 ; (optional) change parameters in
Aquila-sft.yaml
参数名 Parameter
类型 Type
描述 Description
batch_size
int
每次迭代训练时,从数据集中抽取的样本数。一般来说,它越大,处理速度越快,但会占用更多的内存; The number of samples extracted from the dataset for each iteration during training. Generally, a larger batch size can speed up processing but may also consume more memory
gradient_accumulation_steps
int
在更新模型权重之前,要对多个小批次进行梯度计算的次数。主要应用于GPU显存较小的情况下,可以使用小的batch_size,通过梯度累积达到与大batch_size相同的效果; The number of samples extracted from the dataset for each iteration during training. Generally, a larger batch size can speed up processing but may also consume more memoryimages
lr
float
指控制模型更新参数时的步长或速率。学习率过高可能导致模型不收敛,而学习率过低则可能导致训练时间过长或者陷入局部最优解; The step size or rate at which the model updates its parameters during training. A high learning rate may cause the model not to converge, while a low learning rate may result in long training times or being stuck in a local optimum
warm_up
float
初始学习率与原始学习率的比例; The ratio between the initial learning rate and the original learning rate
save_interval
int
模型保存的间隔,即每训练多少个iteration保存一次模型。当训练时间较长时,保存间隔可以避免因突然中断或出现错误导致训练成果全部丢失; The interval at which the model is saved, i.e., how often the model is saved per epoch during training. When training takes a long time, saving intervals can prevent all training achievements from being lost due to sudden interruptions or errors.
接下来会输出下列信息,注意
NODES_NUM
应该与节点数相等,
LOGFILE
是模型运行的日志文件;The following information will be output. Note that
NODES_NUM
should be equal to the number of nodes, and
LOGFILE
is the log file for the model run.
The Aquila language model inherits the architectural design advantages of GPT-3 and LLaMA, replacing a batch of more efficient underlying operator implementations and redesigning the tokenizer for Chinese-English bilingual support. It upgrades the BMTrain parallel training method, achieving nearly 8 times the training efficiency of Magtron+DeepSpeed ZeRO-2 in the training process of Aquila. The Aquila language model is trained from scratch on high-quality Chinese and English corpora. Through data quality control and various training optimization methods, it achieves better performance than other open-source models with smaller datasets and shorter training times. It is also the first large-scale open-source language model that supports Chinese-English-Knowledge, commercial licensing, and complies with domestic data regulations.
AquilaChat-7B is a conversational language model that supports Chinese-English dialogue. It is based on the Aquila-7B model and fine-tuned using SFT. AquilaChat-7B model was developed by Beijing Academy of Artificial Intelligence.
The AquilaChat model was primarily developed to verify the capabilities of the foundational model. You can use, modify, and commercialize the model according to your needs, but you must comply with all applicable laws and regulations in your country. Additionally, you must provide the source of the Aquila series models and a copy of the Aquila series model lincense to any third-party users.
We used a series of more efficient low-level operators to assist with model training, including methods referenced from flash-attention and replacing some intermediate calculations, as well as using RMSNorm. Building upon this foundation, we applied the BMtrain for lightweight parallel training, which utilizes methods such as data parallelism, ZeRO (zero redundancy optimizer), optimizer offloading, checkpoint and operation fusion, and communication-computation overlap to optimize the model training process.
The tokenizer used in the Aquila model was trained from scratch by us and supports both English and Chinese. We used different tokenizers to extract ten thousand data samples from English, Chinese, and code data respectively, obtained the count of tokens for each sample, and also included it in the table. The parameters of this tokenizer are compared to those of other tokenizers in the table below:
模型/Model
词表大小/Vocab size
说明/Note
英文平均tokens量/Avg tokens(English)
中文平均tokens量/Avg tokens(Chinesse)
代码平均tokens量/Avg tokens(code)
GPT2
50527
bpe
1717
1764
2323
LLaMA
32000
sp(bpe)
1805
1257
1970
Aquila
100000
bpe
1575
477
1679
训练数据集/Training data
我们采用了一系列高质量中英文数据集来训练和微调我们的对话语言模型,并且在不断更新迭代。
We used a series of high-quality Chinese and English datasets to train and fine-tune our conversational language model, and continuously updated it through iterations.
我们额外支持了两种多模态的指令: 文图生成和图片编辑,数据集格式请参考这里
We have added support for two additional multimodal instructions: text-to-image generation and image editing. Please refer to the dataset format here.