

样本均值的抽样分布:用实例直观验证中心极限定理

1. 什么是抽样分布
抽样分布指样本统计量的分布 。
什么是样本统计量呢?就是 基于样本计算出的统计学指标 ,例如均值,方差,标准差等等。
总体也有对应的统计学指标,不过我们称之为 参数 。
只要总体确定了,其参数理论上是不会变化的(如:一个既定的总体均值不会变化,只是我们不知道是多少而已)。然而,由于从一个既定的总体中抽取容量为n的样本有无穷种可能,因此对应的样本统计量理论上有无穷个,也就是: 样本统计量是变化的,即变量
既然样本统计量是变量,我们就希望能够获取其分布特征,如均值/方差/形态等。因为知道了这些信息之后,就可以进行统计推断了。 毕竟实际研究中是无法获取总体信息的,只能够通过样本信息来对总体进行推断 。
接下来,本文以样本均值(M)为例,抛弃复杂的公式推导,用直观的例子来解释M的分布特征。
2. M抽样分布的均值和方差
为便于理解,我们先编一个简单的总体:
假设某个总体包含以下数据: {2,5,10,11}
则总体均值为: \mu=\dfrac{2+5+10+11}{4}=7
总体方差为: \sigma^2=\dfrac{(2-7)^2+(5-7)^2+(10-7)^2+(11-7)^2}{4}=13.5
现在从该总体中随机抽样(放回),抽取n=2的样本,则所有可能的样本及其均值M如下:


简单计算一下即可发现此时的 16个M的均值刚好等于7 ,也就是总体均值;方差刚好等于6.75,即总体方差除以n: \dfrac{13.5}{2}
这是巧合还是必然?
让我们再验证一下,此时取n=3的样本,注意此时可能的样本一共有64种。

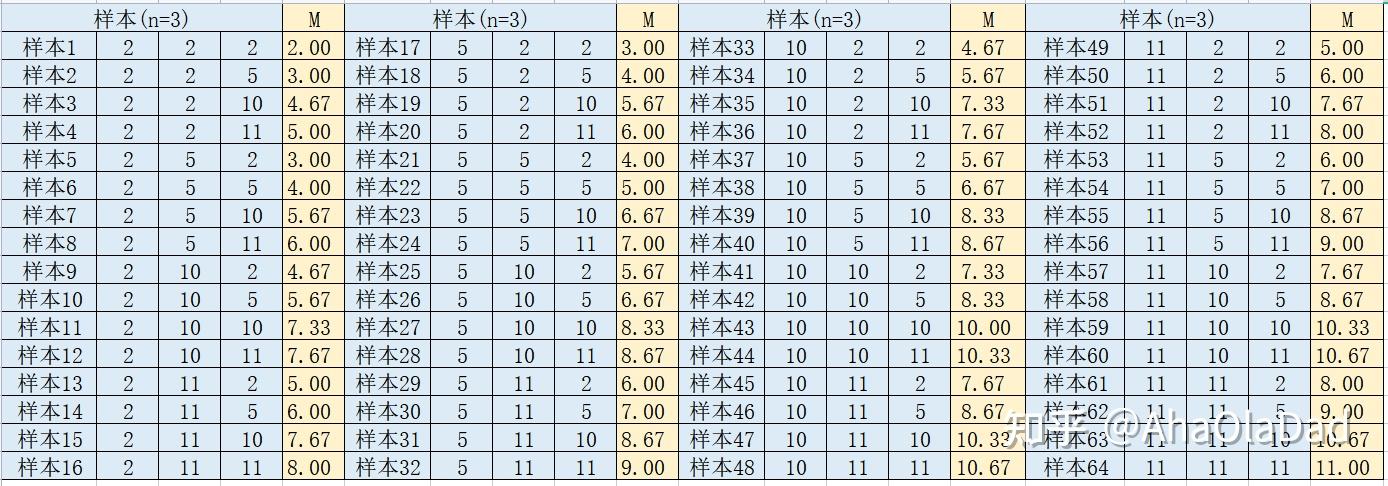
计算一下可以发现,此时的64个M的均值也等于总体均值,方差等于总体方差除以n。
如果小伙伴们还不相信,可以再取更大的样本量进行验算,不过此时可能的样本数量非常大。当然可以用R语言来实现。例如当n=5时:
population=c(2,5,10,11) #定义总体
n=5 #定义样本量
templist=list()
for (i in 1:n){
templist[[i]]=population
allSamples=expand.grid(templist)#生成所有可能样本,每一行是一个样本