

Guided Diffusion Model(s) for Adversarial Purification

文章背景信息
-
作者:
- Weili Nie, Brandon Guo, Yujia Huang, Chaowei Xiao, Arash Vahdat, Anima Anandkumar
- Jinyi Wang, Zhaoyang Lyu, Dahua Lin, Bo Dai, Hongfei Fu
-
论文出处:
- ICML 2022
- Arxiv
-
论文链接:
- [Guided Diffusion Models for Adversarial Purification]( http:// arxiv.org/abs/2205.0746 0 )
- [Guided Diffusion Model for Adversarial Purification]( http://arxiv.org/abs/2106.09667 )
比较有意思的是,两篇文章都是用diffusion来做对抗样本防御(去噪)的,论文标题就差了一个字(笑),意外碰上了,让我们来看看上交和英伟达的论文那个更remarkable !
为了方便表示,用P1代表英伟达的论文,p2代表上交的论文。
个人总结:P1和P2都使用了diffusion模型作为去噪器,其中第一篇文章理论分析较多,对采样过程中的参数选择也比较合理,实验充分;第二篇论文易相对懂一些,但是对参数选择的说明不是非常清楚。两篇文章的原理其实是差不多的,通过扩散模型的前向加噪过程将对抗样本和正常样本都映射到高斯分布,在去噪过程中还原。但是在面对pipeline攻击时的防御效果是没有得到保证的(论文里的setting说的不是很清楚,之后再看看代码)
摘要
对抗净化是指利用生成模型去除对抗扰动的一类防御方法。这些方法不对攻击形式和分类模型做任何假设,因此可以防御先前存在的分类器来抵御看不见的威胁。然而,他们的表现目前落后于对抗训练方法。在这项工作中,我们提出了使用扩散模型进行对抗净化的DiffPure:给定一个对抗样本,我们首先通过正向扩散过程将其与少量噪声进行扩散,然后通过反向生成过程恢复干净的图像。为了以高效且可扩展的方式评估我们的方法抵御强自适应攻击,我们提出使用伴随方法来计算反向生成过程的全梯度。在CIFAR10、ImageNet和CelebA - HQ 3个图像数据集上,采用ResNet、WideResNet和ViT 3种分类器架构进行了大量实验
问题与方法的建模
- p1 理论部分
该定理说明,前向加噪过程中必然是存在对抗样本和干净样本分布相同的时刻,当二者的KL散度对t求导小于零是,t指的是加噪的程度。


在去噪过程中需要保证的是,去噪后的图片和原图不能差太多,这里面用的好像是MSE


- p2 理论部分
主要的理论部分就是这个了,主要的区别是这篇论文用SSIM进行guide来去噪(为啥不用LPIPS)

实验与讨论
- p1 实验结果

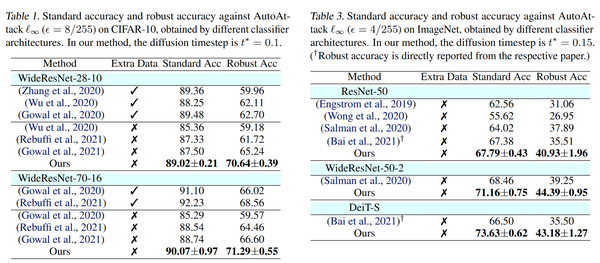
与对抗训练相比的结果,应该是pipeline的攻击,不然不公平
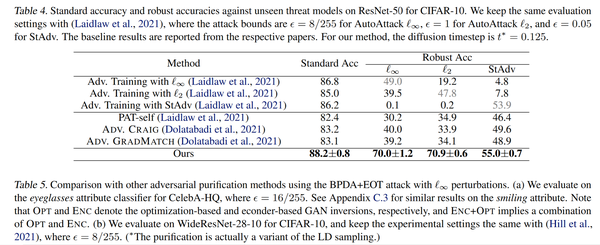
比较重要的一点是,对于没有见过的攻击,即BPDA这样的,对很多防御方法都是致命的,这也是当前做对抗防御必须要做的攻击。
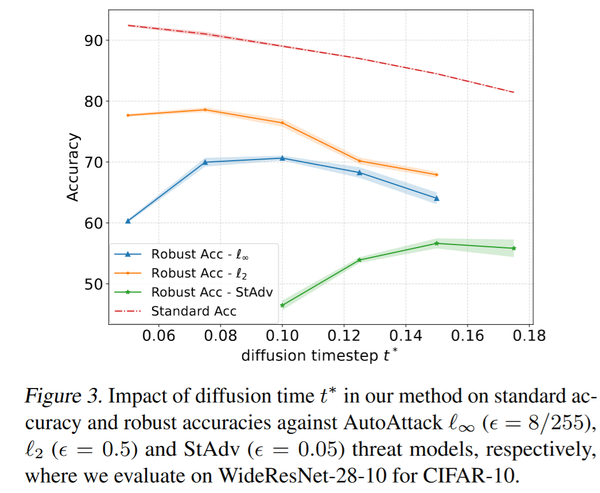
关于加噪过程中参数的选择,若太大会影响干净样本的acc,若太小则很难起到防御的作用。
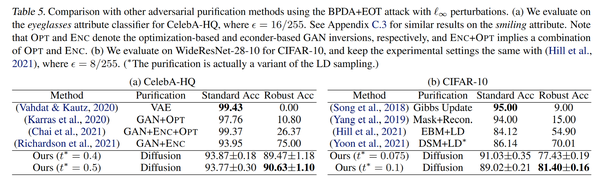
- p2 实验结果
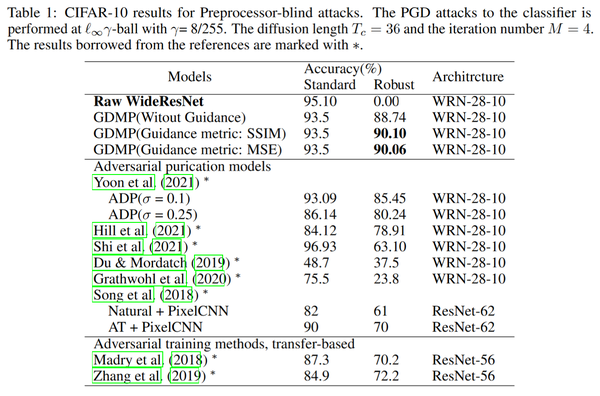
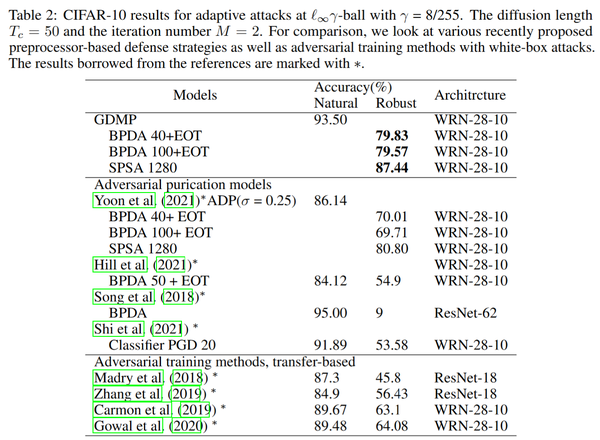
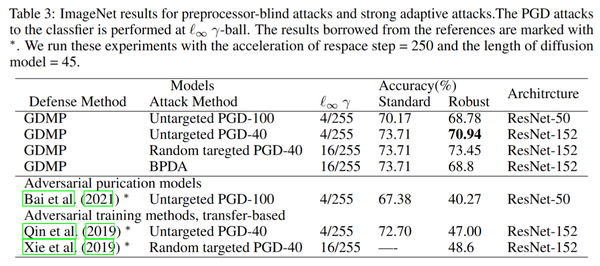
总结
对比下的话,两个方法其实核心差不太多,但是论文包装程度完全不一样,上交的论文里还提到了size256的模型转size224的这些细节,感觉这放在正文里不是非常合适,尽管这些实验结果表明,防御效果已经能够优于对抗训练等方法,但是仍然没有从根本上解决对抗鲁棒性的问题,同时diffusion的处理和训练是非常慢的。
本文使用 Zhihu On VSCode 创作并发布