

预测不同类型的对流天气:深度学习方法

原文地址:
本文是《Forecasting Different Types of Convective Weather: A Deep Learning Approach》的阅读笔记。
介绍
文章开发了基于 数值天气预报(NWP) 数据的 强对流天气(SCW) 深度学习目标预测解决方案,包括 短时大雨(HR)、冰雹、对流阵风(CG)和雷暴 。文章首先建立训练数据集:五年的恶劣天气观测被用来标记 NCEP最终(FNL)分析数据 ,然后为每种天气选择大量标记样本进行模型训练。模型中, 当地的温度、压力、湿度和1000hpa到200hPa的风,以及几十个对流物理参数被作为预测因子 ;然后构建和训练六层 卷积神经网络(CNN) 模型以获得最佳模型权重;之后将训练好的模型用于基于 全球预测系统(GFS) 预测数据作为输入来预测SCW;最后将CNN模型与其他传统方法的性能进行了比较。结果表明:
(1)深度学习算法对HR和冰雹的分类准确率高于支持向量机、随机森林等传统机器学习算法;
(2)使用深度学习算法的客观预测也比预测者的主观预测表现出更好的预测能力:雷暴、HR、冰雹和CG的 威胁评分(TSs) 分别提高了16.1%、33.2%、178%和55.7%。
数据集
NWP数据
NWP数据是2010-14年期间全球1°×1°的NCEP 最终(FNL)分析数据 。所有数据每天提供4次(0000、0600、1200、1800UTC),提供全球天气情景。模型训练完成后,利用 GFS 的1°×1°预测数据对SCW进行预测。
预报因子包含有效描述SCW事件的所有主要环境条件,其中包括基本气象要素,如 压力、温度、位势高度、湿度和风,以及一些可以反映水汽、大气不稳定的对流物理参数和隆起条件 。为了说明不同地区之间的地理差异,模型中使用了 海拔、经度和纬度 。最终共选择了144个预测因子来描述SCW的环境特征(如表1所示),所有这些预测因子都来自FNL分析数据。


SCW观测数据
用于 标记 预测因子的雷暴、HR、冰雹和CG的观测来自 NMC的恶劣天气观测数据集 。
雷暴观测 由中国国家闪电定位网(NLLN)收集的闪电定位数据组成,如果NLLN观测到至少一次雷击,则记录为雷暴。
HR数据 包括每小时降雨量不少于20毫米的观测值。
降雨量 由2420个国家级气象站(NWS)和20,000多个自动气象站的自动雨量计测量。
冰雹和CG观测 来自观察员报告,同样来源于NWS。
深度学习方法
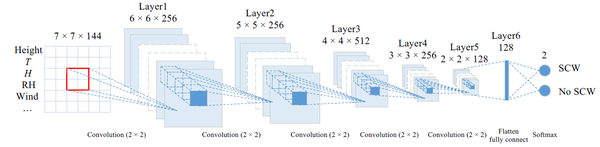
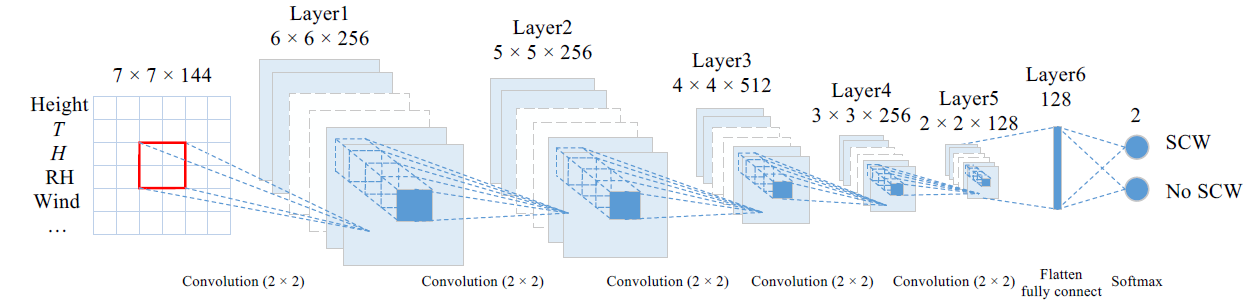
SCW预测的深度学习算法(图1)包括三个主要步骤。首先,收集训练和测试数据集。其次,构建、训练和测试深度学习网络。第三,实施经过训练的网络进行预测。
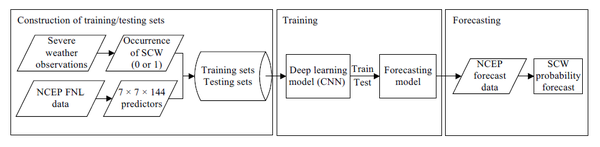
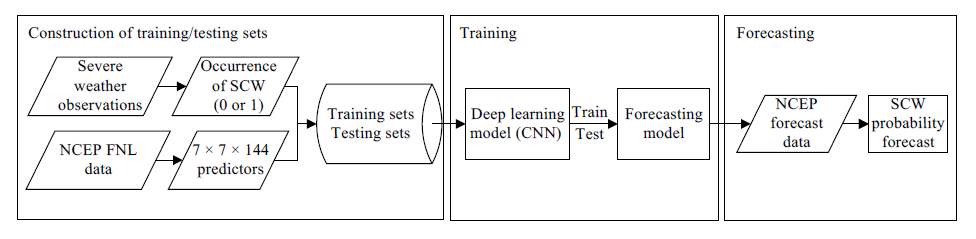
训练集与测试集的构建
天气预报可以看作是一个二分类问题,即0表示不会发生,1表示会发生。模型输入设置为144个观测到的气候变量,分布在以每个SCW事件网格为中心的尺寸为L×L的方形块上。这些L×L×144数据张量由1或0标记,这些标记的数据数组形成训练或测试样本。L的选择可以平衡计算效率和模型性能,文章设置L=7。
由于NWP是网格数据而SCW观测是站点数据,因此需要首先将观测映射到NWP网格。如果观察到的SCW事件发生在网格点的半径R内则网格点标记为1,表示事件发生在该网格点,否则格点标记为0。如果R设置的太小,会出现太多的缺失预测;而如果R太大,就会有太多的误报,所以设置R为20km。
与非SCW事件相比,SCW是一个 高影响和低概率事件: 正样本(标记为“有SCW”)远远少于负样本(标记为“没有SCW”)。这是 样本集不平衡 现象, 因此使用过采样技术,复制正样本以平衡训练集中的正负样本 。但是, 测试集不需要过采样,因为测试集主要用于评估训练模型的性能 。因此构建了没有过采样的测试集,以评估训练模型在真实正负样本比例下的性能。
根据2010-2014年3月至10月期间的SCW观测和NCEPFNL分析数据构建了两个独立的数据集。其中一个包含从2010-14年3月到10月的每个月随机选择一天的50天样本作为 测试集 ;另一个构建的数据集包含所有剩余的正负样本(4,582,577个雷暴样本、3,609,185个HR样本、1,468,158个冰雹样本和1,488,531个CG样本)作为 训练集 。
CNN
文章的CNN模型有 卷积层、全连接层和Softmax层 组成,处理的核心是由五个卷积层(C1到C5)的前馈堆栈执行的,然后是一个输出类别分数的全连接层。五个卷积层的每个通道都是通过将前一层的通道与一组线性2D滤波器(例如求和、添加偏置项和应用逐点非线性)进行卷积而获得的:
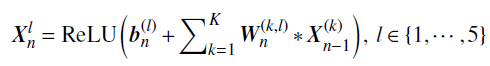
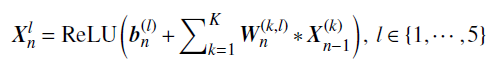
其中 ReLU(x)=max(0,x) 是修正后的线性单元激活函数。符号 * 表示二维卷积运算。 W^{(k,l)}_n 矩阵代表第n层的过滤器,以及特征图l的偏差 b^{(l)}_n 。特征图 X^{(l)}_n 是通过计算来自前一层的特征图的K个卷积的总和获得的。
第五层之后是具有128个神经元的全连接层,它将3D矩阵( X^5 )转换为1D矩阵( \bar{X}^5 )。计算c=0或1的类分数 S_c :
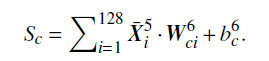
最后将Softmax分类器函数应用于类分数以获得 适当归一化的概率分布(p) ,这可以解释为给定输入和网络参数 W 和 b 的两个类的后验分布:
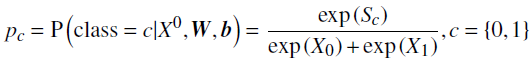
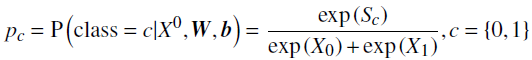
其中 W ={ W^1 , ..., W^6 }是权重集, b ={ b^1 , ..., b^6 }是偏置集。
整体的结构为:
通过最小化 L2 正则化交叉熵损失函数 来优化网络参数。
评价指标(Evaluation Metrics)
选择四个技能指标来衡量预测的性能: 威胁分数(TS)、公平威胁分数(ETS)、检测概率(POD)和误报率(FAR) :
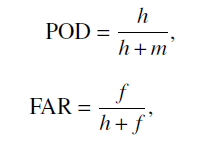

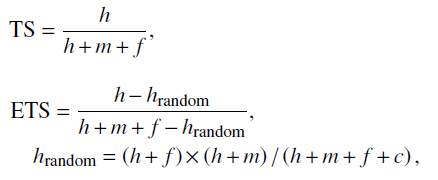
其中h是命中数,m是缺失预测的数量,f是错误预测的数量,c是正确否定的数量。虽然上述分数通常用于评估确定性预测,但它们也可以用于通过对概率预测进行阈值化并将其转化为确定性预测来评估概率预测,因此使用这四个分数来评估深度CNN预测结果。在为每个预测探索不同的阈值后,发现雷暴、HR、冰雹和CG的最有效概率阈值分别为0.5、0.5、0.9和0.9。
结果
不同算法的性能评估
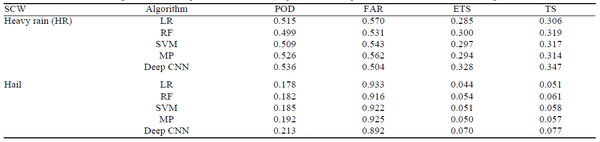
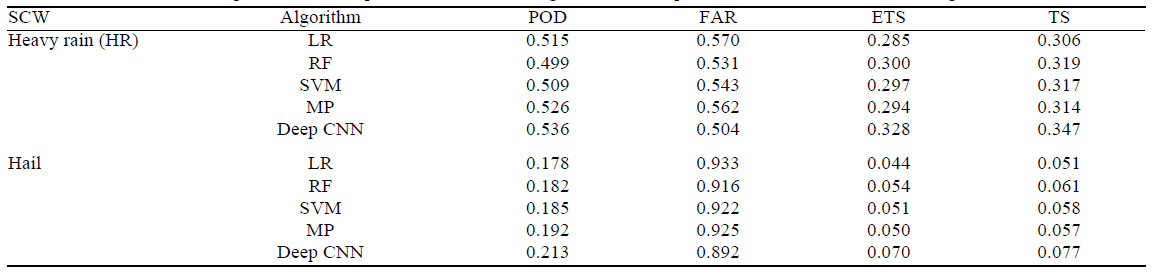
表2中报告了使用HR测试集(592个正样本和14,049个负样本)以及冰雹测试集(149个正样本)的各种算法的分类性能样本和14,492个负样本)。传统ML算法的输入是每个SCW事件网格的144个预测器。从表2可以看出,不同的算法具有不同的分类技巧:RF、SVM、MP的性能在ETS和TS方面相近,略好于LR;深度 CNN 算法在中国的 SCW 预测中优于传统的机器学习算法。
案例评估
2017年9月21日,中国北方大面积出现雷暴、CG和冰雹,同时华南大片地区出现雷暴和HR。SCW对这种情况的观测和预测如图3所示。
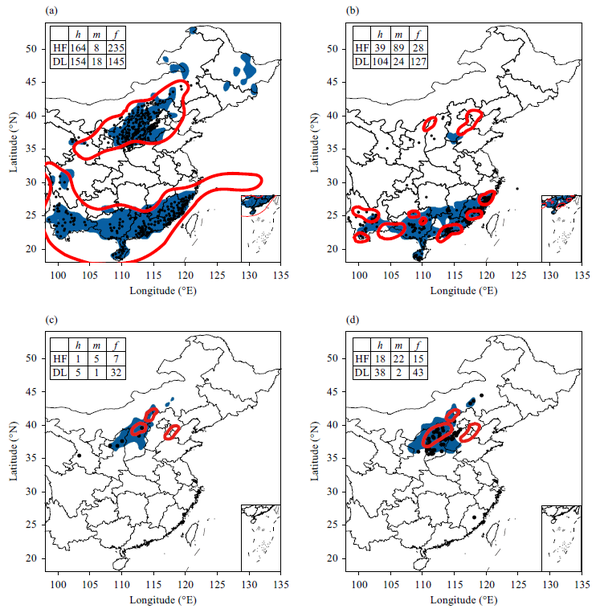
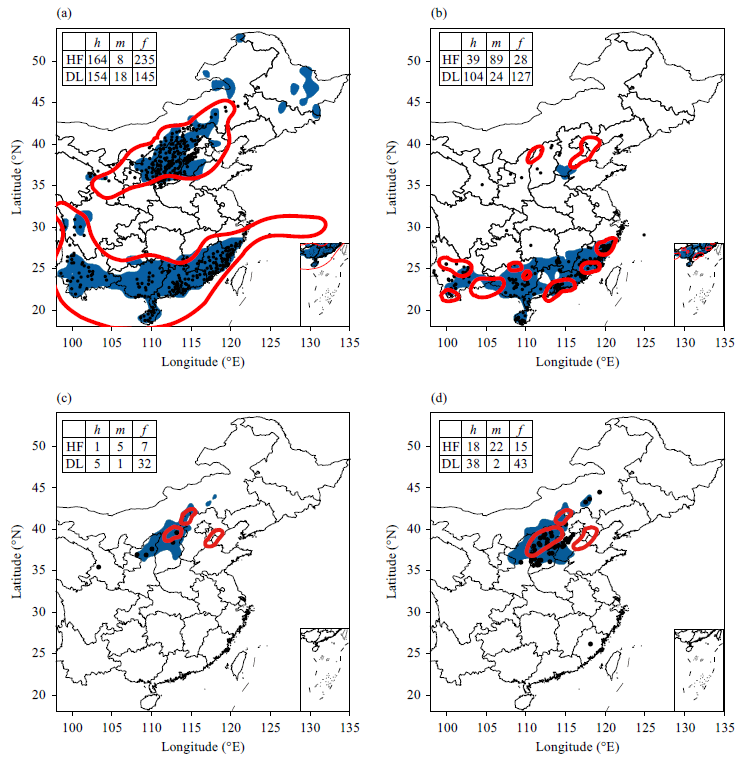
图3清楚地表明, 深度CNN算法对中国北方的雷暴、冰雹和CG有很好的预测能力。根据预测,预测区域内的大部分事件都被成功识别。此外,深度CNN算法在预测中国南方的雷暴和HR方面似乎也很熟练 。
误报案例
选取2015年8月2日发生在中国东北地区的SCW误报来调查误报原因。对于本次SCW,预测表明在内蒙古东部、黑龙江西南部、吉林和辽宁省的大面积地区将出现HR。NWP预报场和分析场之间的比较表明NWP预测和观测之间存在很大差异。图4a显示,实测PWAT值明显低于预测值,吉林中部和辽宁中部PWAT预测值比实测值高约8mm。此外,预测的K指数也比观察结果高3-7°C,如图4b所示。
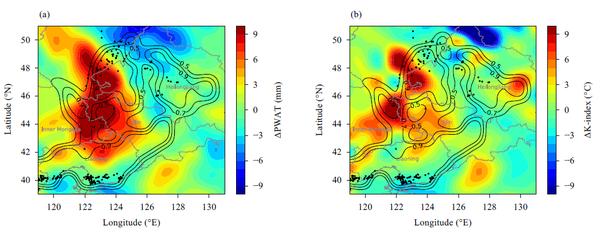
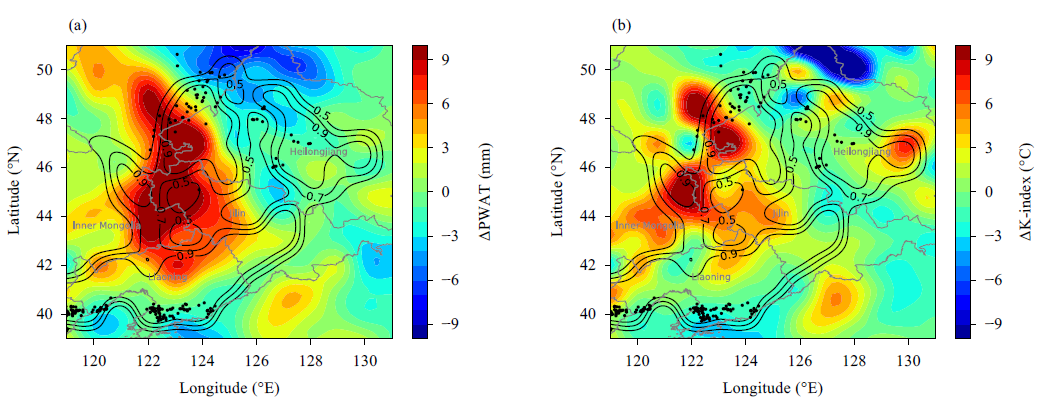
NWP预报中的水汽状况和K指数分布有利于HR事件的发生。为此,发出了SCW的误报。 由于深度CNN算法以错误的NWP预测作为输入,因此也预测了中国东北大面积的HR事件 。
漏报案例
在2015年7月9日的0200-1400BJT期间,深度CNN算法预测HR事件只会发生在四川省中部及其周边地区,而观测表明HR事件实际上发生在川东更大的区域。结果,这是一个错过预测的案例。为了分析漏报的原因,图5显示了GFS预测场和观测值之间的比较。
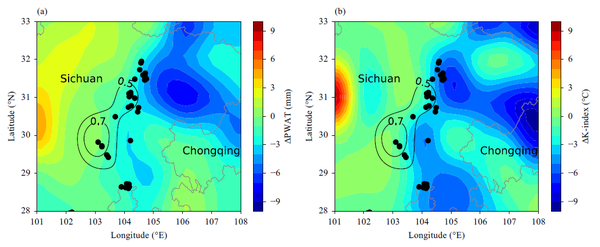
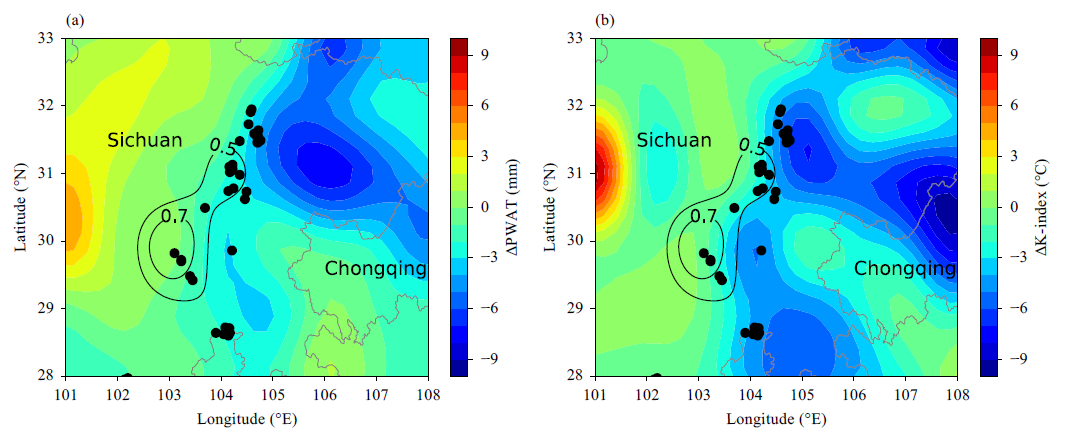
总体而言,FNL分析场与预测场之间存在明显差异。预测和分析之间的显着差异如图5所示,这表明PWAT和K指数的分析值远大于预测错过HR事件的川东预测值。
GFS预报场表明环境条件仅有利于弱对流的发展。相比之下,分析表明,真实的环境条件实际上非常有利于SCW的发展,气象学家也未能预测四川东部的HR事件。文章发现深度CNN算法未能预测SCW事件的原因是因为NWP预测作为输入只对弱对流有利。
总体评价
为了全面评估深度CNN算法的性能,报告了CNN算法和气象学家对2015年、2016年和2017年4-9月SCW的预测(图6)。

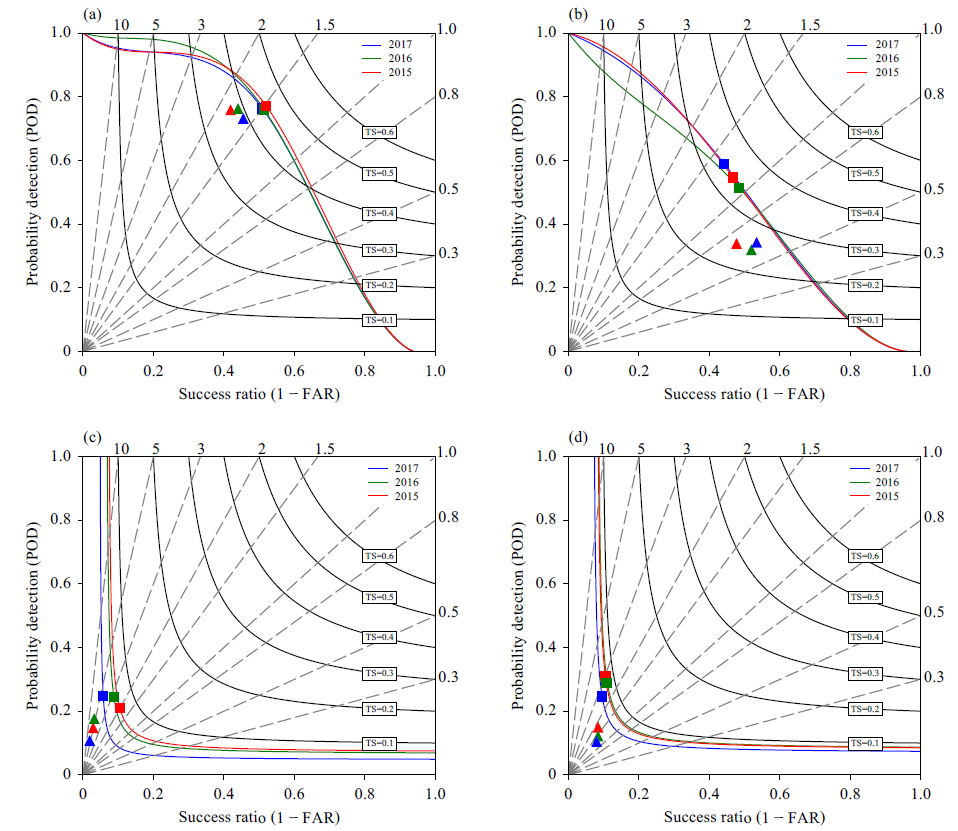
表 3 显示,与预测者的预测相比,深度 CNN 算法显着改善了各种 SCW 的预测。
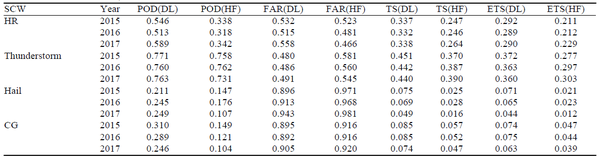
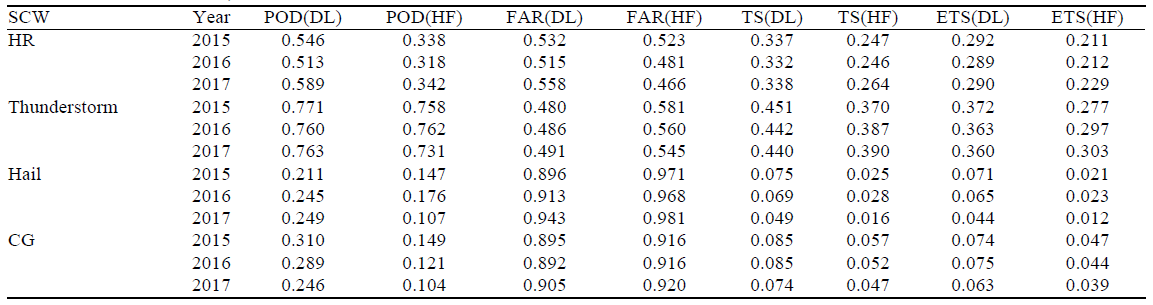
深度 CNN 算法在所有四种类型的 SCW 预测中都显示出更高的能力。 与预测者的预测相比,深度 CNN 预测在定性和定量评估方面都显示出显着的改进,表明该算法具有更好的整体性能。 尽管如此,该算法仍然存在不足,因为它发出了过多的冰雹和重心误报,气象学家的预测中也存在这个问题。 因此,未来改进算法的一个关键目标将是降低预测的 FAR。
