


接口自动化框架封装思想

接口封装编程思想
框架实现,把所有的接口请求分装成一个方法,目的利于后期维护,以及日志的添加,异常处理,自动实现了cookin关联。
目的是:不需要写代码就能实现接口自动化。
1,第一步接口请求底层分装,处理请求传入参数,处理多个url请求请求地址,通过一个yaml公共文件维护,每次只需修改yaml文件实现全局修改,同一个项目调用多个不同的地址。
2,接口之间的关联,通过分装方法将公共参数写入yaml文件,请求参数通过读取方法获取到值
3,yaml文件用例模板规范,
3.1.必须要有四个以及关键字:name,base_url,requests,validate
3.2,在requests下面必须包含两个二级关键字必填method、url,(harders、params、data、json)其中的一个
3.4,接口请求通过requests下面的二级关键字传参,
get通过 :params参数
post 通过 data、json、file都是通过这几个关键字传参
4,接口文件之间的关联,设置yaml文件中的以及关键字extract。通过读取判断extract是否存在,第种方式使用re.rearch((.*?),str)正则表达式查询,第二种返回res.json()的数据格式通过字段提取值写入公共文件。
5,接口动态参数的封装(使用debug_talk.py热加载的方式)。视同${使用方法名(参数)},使用getattr()方法:反射,通过函数名称字符串去调用函数。
6,断言:通过yaml文件读取validate的值,通过解析,提取出预期与实际进行比较。第一个必须断言状态码,第二业务断言。
7,csv数据驱动测试,使用一级关键字paramters,解析数据,进行替换。返回一个字典list。通过parametrize参数化
8,logger日志封装使用。
接口请求分装,在公共文件(common),封装公共请求方法,设置请求参数。
- 创建请求类,,一般请求有很多种类型,get、post、....常用的就这两种,get请求通过params传参,post通过json和data传参。常用的传参有几种multipart/formdata 文件上传,application/xwwwformurlencoded 键值对形式,raw 里面包含 Content-Type:application/json json传参,Content-Type:text/html html常用的就这几种。
- ptthon用requests发送请求,请求(method,url,params=None,data=None,headers=None,files=None,json=None,cookies=None,)cookie是所有web项目都要关联的东西,我们一般会用session方式表示同一个会话里面。
- 我们首先创建一个类,类名遵循驼峰命名规则,ResquestsUtil,创建一个session会话请求session = requests.session(),因为requests.post,底层逻辑最终会经过session发送请求,创建发送请求的公共方法 def send_requst(self,name,method, url,headers=None,files=None,**kwargs)分装请求必传的参数,
- 发起请求的方法,res=RequestsUtil.session.request(method=method,url=self.base1_url,headers=self.last_headers,verify=False, **kwargs),发送请求必须有,URL,method,headers的传参,其他参数通过不定长参数传入。最终返回请返回的数据 return res
- 接口请求通过调用该请求方法,传参返回结果。
- 用到的知识点,接口请求入参规范。conkin关联 requests.seesion()。
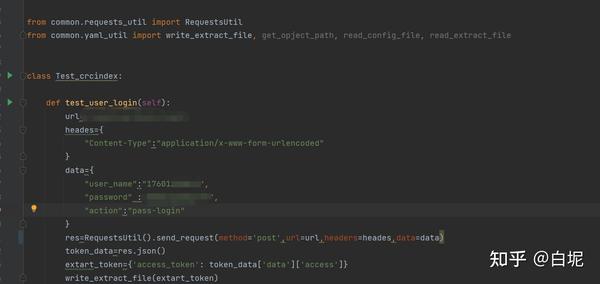

接口关联使用方法,这里要了解yam文件格式的使用规则
1,以前提取参数,通过设置成全局参数,来调用,跨文件不是很实用。接下来使用yaml文件来实现。
简单的方法,我们将提取出来的tooken或者其他参数写入到yam文件里面,已键对值保存,新建一个yml文件,创建一个读取yml文件的方法,传入一个关键字,这个关键字代表key:value的值,把key:value的值写到yml文件里。
def get_opject_path(): #获取系统绝对路径,避免部署时路径不对应
return os.path.abspath(os.getcwd().split('common')[0])
os.getcwd()该方法获取当前文件所在位置的上级目录,split()字符串切割,切割路径取第一个值
2,def write_extract_file(data):#创建写入yal文件的方法,将token写入到yaml文件
with open(get_opject_path() + '/extract.yml', encoding='utf-8',mode='a') as f:
value = yaml.dump(data,stream=f,allow_unicode=True)
- data:写入的数据
- stream:文件流
- allow_unicode = True 如果添加的数据包含中文,避免写入的数据出现乱码
- 写入文件的方式以追加的方式mode = 'a'写入的,所以yaml文件中鼠标的光标要放在最后面,否则就会导致,光标在哪里,追加的内容就从那里开始。
mode='a' 已追加的二进制方式写入, yaml.dump()写入到ymal文件,data写入的值、strem传入的值 allow_unicode 允许以,utf-8写入。
例如:写入到文件里面,
extart_token={'access_token': token_data['data']['access']}
write_extract_file(extart_token)
3,在创建一个读取文件的方法
def read_extract_file(node_name):# 读取yml文件里面的参数
with open(get_opject_path()+'/extract.yml',encoding='utf-8') as f:
value=yaml.load(stream=f, Loader=yaml.FullLoader)
return value[node_name]
yaml.load()读取yml文件
4,那么问题来了如何解决再次请求,怎么确保数据的是否是最新的,我们就用到pytest里面的conftest.py文件
首先新建一个方法请求清空yml文件里面的值。
def clear_extract_file():#清空token,重新清空文档里参数
with open(get_opject_path() + '/extract.yml', encoding='utf-8', mode='w') as f:
f.truncate()
rtuncate()清除文件, mode='w' 写入
在conftest里面清空
from common.yaml_util import clear_extract_file
pytest.fixture(scope='session',autouse=True)
def clear_extract():
clear_extract_file()
使用yml文件编写接口请求参数,这注意yml文件格式
1,yml文件的使用规则:大小写使用敏感,缩进代表层级关系、缩进使用不能用tab建 。数据结构方面:对象表示符号 :表示键值对的集合,读出来是字典类型数据。 - 按照序列的顺序排列的值,又称序列列表。纯量:数字,字符串,
我们写的文件必须包含四个键值对,name ,base_url,requests,validate,我们使用方法读取yml文件数据进行判断传值,
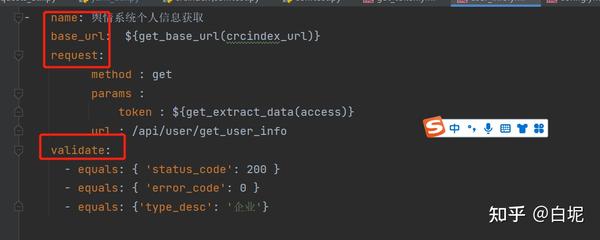

def read_testcase_file(yaml_path):#传入yml文件路径读取文件
with open(get_opject_path()+yaml_path,encoding='utf-8') as f:
caseinfo=yaml.load(stream=f,Loader=yaml.FullLoader),加载完整的yml文件,
return caseinfo
读取文件,并返回读取返回值。传入用例参数化,进行执行
pytest.mark.parametrize('caseinfo',read_testcase_file('/testcasess/get_token.yml'))
读取出数据
[{'name': '舆情系统登录1', 'base_url': '${get_base_url(crcindex_url)}', 'parameters': {'name-user_name-password-action-assert_str']不完整
- 一个符号代表一个列表,代表一组请求数据,多个列表代表多个请求数据,形成一个列表字典。
读取yml文件解析参数,判断数据、发送请求
我们创建一个方法读取分析,解析yaml文件传过来的参数,def analysis_yml(self,caseinfo):self,我在里面创建的一个方法,caseinfo是我用来解析的数据。
首先我们来接口请求参数在yaml文件里面已经规划好了,key必传,name ,base_url,requests,validate
caseinfo_key=dict(caseinfo).keys() ,将转化成字典格式,提取key的值,我们判断必传值在不在里面
if 'name' in caseinfo_key and 'request' in caseinfo_key and 'base_url' in caseinfo_key and 'validate' in caseinfo_key:
如果存在下一步,request_keys=dict(caseinfo)['request']#取到request里面键对值
if 'method' in request_keys and 'url' in request_keys: #判断method和URL从在否则无法发送请求,接口请求必传的两个参数,
self.base_url=caseinfo['base_url'] 这个后面说,主要是环境域名的使用
url =caseinfo['request']['url'] #获取url
del caseinfo['request']['url'] #因**caseinfo关键字,前面已经传过,后面需要进行删除。
method=caseinfo['request']['method']#获取使用方法
del caseinfo['request']['method']
headers=None 头部传空
if jsonpath.jsonpath(caseinfo,'$..headers'):#判断是不是有headers,如果有进行下一步传值,jsonpath是提取参数的一种方式..代表提取的层级。
headers=caseinfo['request']['headers'] #提取出headers
del caseinfo['request']['headers']

files=None
if jsonpath.jsonpath(caseinfo,'$..files'):#判断是否有files文件传参
files=caseinfo['request']['files']#取出fil文件地址下面字典
for key, value in dict(files).items():#字典进行循环取出key和value值
files[key]=open(value,'rb')#打开上传的文件
del caseinfo['request']['files']
res=self.send_request(name=name,method=method,url=url,headers=headers,files=files,**caseinfo['request'])
**caseinfo['request'] 表示,上传requests下面的所有值,所以删除了前面删除了**caseinfo['request']的值,因为已经提取出来了。
调用分装的请求方法,就可以请求成功了。
所用到的知识点,dict.items() 、jsonpath、
读取ymal用例,替换参数化变量值
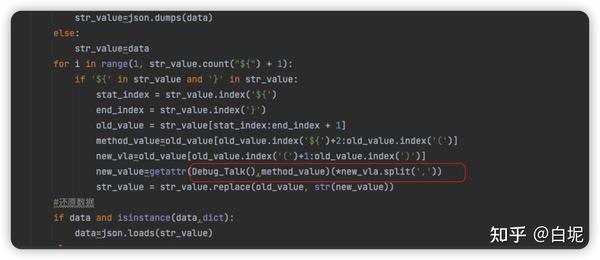
yaml文件读取出来的数据包含${ }或者没有,这是我设置的规范写法,来读取括号里面的值。
def replace_value(self,data):
try:
if data and isinstance(data,dict): 判断传进来的数据是否存在,并且是字典类型。
str_value=json.dumps(data) 如果是字段类型装换成字符串
else:
str_value=data #否则就是字典类型
for i in range(1, str_value.count("${") + 1): 查找字符创中有多少个需要替换的变量值,进行循环替换。
if '${' in str_value and '}' in str_value: 判断是否存在。
stat_index = str_value.index('${')查找${下标位置
end_index = str_value.index('}')
old_value = str_value[stat_index:end_index + 1] 获取读取出来的所有值${ain_value(access)}
method_value=old_value[old_value.index('${')+2:old_value.index('(')] 读取ain_value参数
new_vla=old_value[old_value.index('(')+1:old_value.index(')')] 读取到access的值
new_value=getattr(Debug_Talk(),method_value)(*new_vla.split(','))通过getattr反射的方法,Debug_Talk()所属类,method_value方法,字符串的形式展示,调用method_valued的方法里面的数据进行解包切割。
str_value = str_value.replace(old_value, str(new_value))设置变量数据替换成新的数据
#还原数据
if data and isinstance(data,dict):
data=json.loads(str_value)
else:
data=str_value
return data
except Exception as error:
error_loging('接口关联公共参数替换失败')
知识点:
json.dumps()字典转化成字符串 json.loads()字符串转换成字典 value .replace()字符串替换
isinstance(传入两个值),判断是是什么类型。如果为真返回ture。
getattr(类,方法)通个反射调用方法,用来获取对象中的属性值;
获取对象object的属性或者方法,如果存在打印出来;如果不存在,打印出默认值,默认值可选。
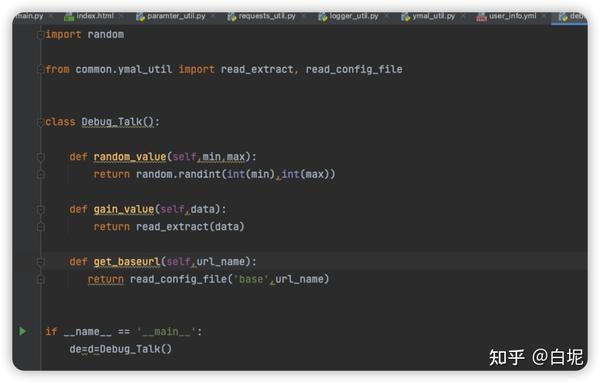
yml文件里token如何获取参数
1,我们通过热加载的方式,把前一个接口提取出的tooken存放在了yaml文件里面了
新建一个debug_talk.py文件,编写一个读取参数方法,在通过传入的参数,调用读取yaml文件的方法获取参数
#读取变量文件
def read_extract(data):
with open(get_dir()+'/extract.yml',encoding='utf-8')as f:
read=yaml.load(stream=f,Loader=yaml.FullLoader)
return read[data]
replace_value()方法,当用例文件读取出来,通过该方法去替换设置的变量名称


接口请求断言
def validate_result(self,expect,actual,result_code): #设置断言传入的变量值,预期结果、实际结果、接口响应的状态码。
try:
num=0 #设置变量统计是否有断言失败的。
write_loging(f'预期断言数据: {expect}') 日志
write_loging(f"实际返回结果: {actual}")
if expect and isinstance(expect,list): #判断期望结果存在,类型为list
for value in expect: 循环 断言的list
for expect_key,expect_value in dict(value).items(): 循环列表里面的字典
if isinstance(expect_value,str): 判断期望值是字符串类型
expect_value=eval(expect_value) 将期望的值转化成本身的类型,转换几点里面的字符串为字典
if expect_key=="equals": 断言是否有规定字段equals
for exp_key ,exp_value in dict(expect_value).items(): 如果有,循环key,value取值
if exp_key=="status_code": 判断预期key的值等于status_code
if exp_value!=result_code:
num+=1
error_loging(f'期望值{exp_key}:{exp_value} 不等于实际结果{exp_key}:{result_code}')
else:
key_list= jsonpath.jsonpath(actual,'$..%s' %exp_key)
if key_list:
if exp_value not in key_list:
num+=1
error_loging(f'断言失败{exp_key}:{[exp_value]}断言的值与实际{exp_key}:{key_list}不符')
else:
num+=1
error_loging(f'在实际结果里面查找不到:{exp_key}字段')
elif expect_key =='contain':
if expect_value not in json.dumps(actual):
num+=1
error_loging(f'断言{expect_key}:{expect_value}在实际结果里面查询不到')
else:
error_loging('断言的方法不存在')
assert num==0
write_loging('-----------------------接口请求结束-------------------------')
except Exception as error:
write_loging('-------接口请求失败或者断言失败------')
error_loging('接口断言失败%s'%traceback.format_exc())
实现思维:通过接口请求之后,根据预期值,实际结果,接口响应的状态码,传入这个方法进行判断,首先判断有预期断言validata,否则就没有断言,同键取出它的值,判断是不是list类型,进行循环取到字典的值,再通过字典dic().items取到key,value ,判断key==equals,通过字典dic().items取到key ,if key=='status_code' 在判断期望的value=接口实际返回来的状态码,不等于断言失败,自定义变量num加一。否则判断key==equals下面还有其他的不等于key=='status_code'的相等断言。通过jsonpath判断在实际结果里存在相同断言其他的值进行提取出来,判断是否存在,不存在num加一,断言的数据在实际结果里面找不到,断言失败加1。
在判断包含内容的断言,expect_key =='contain’ 判断 values not in actual,期望结果值在实际结果里面包含,不包含加一
或者断言的结果key不存在,没有该断言的方式。
csv参数化读取用例执行
def csv_reard_file(path):
try:
csv_data_list=[]
with open(get_dir()+"/" + path) as file:
csv_data =csv.reader(file)
for row in csv_data:
csv_data_list.append(row)
return csv_data_list
except Exception as error:
error_loging('读取csv文档出错%s'%traceback.format_exc())
读取csv文件,读取数据,分析数据,将数据每一列添加到列表里面。将数据返回出来。
#读取测试文件
def read_case_yaml(yml_url):
try:
with open(get_dir()+yml_url) as file:
conf=yaml.load(stream=file,Loader=yaml.FullLoader)
if len(conf)>=2:
return conf
else:
params_key=dict(*conf).keys()
if 'paramters' in params_key:
parameter_list=analysis_paramter(*conf)
return parameter_list
else:
return conf
except Exception as error:
error_loging('读取csv参数化用例%s'%traceback.format_exc())
通过 read_case_yaml(yml_url)读取yaml用例文件,判断ymal文件里有几个list,如果存在两个list不进行参数化,
返回原有数据,当yaml文件只有一条用例时候,判断他是否有paramters关键字存在,存在进行参数,analysis_paramter(*conf)方法进行解析,替换参数。
def analysis_paramter(conf):
try:
conf_key=dict(conf).keys() 获取yaml文件字典key的值
if 'paramters' in conf_key: 判断参数化paratmes的值是否存在
paramer_value=conf['paramters']
for key,value in dict(paramer_value).items(): 循环键对值
parame_key=str(key).split("-") 把键的参key值进行切割
str_conf=json.dumps(conf) 把加载出来的用例转换成字符串,提供下面进行替换值。
csv_list=csv_reard_file(value) 调用读取csv的方法,读取出数据
one_value=csv_list[0] 取的第一列设置好的字段,参数的自定义的名称
lenght_flag=True 定义一个变量,当不满足条件给变为false
for row in csv_list: 循环读出来的列表。
if len(row)==len(one_value): 判断csv第一行自定义的参数化列数量与参数数量是一样的
if parame_key==str(one_value):在判切割出来的key与第一列的值相等。符合条件跳出循环否则
赋值 lenght_flag = False
pass
else:
lenght_flag = False
write_loging(f'参数化{row}列的行数不等于{one_value}无法进行参数化,直接传入原始值')
break
定义一个列表,将替换出来的数据放到列表里面,判断为真,进行循环从csv第一行开始,到最后一行结束,
在从第一列开始0还,长度是第一行的len。进行循环。temp_conf这个作用是每次使用原始数据进行替换
避免替换之后的数据在进行替换,是无效果。从读取的数据中设置替换变量的值,通过获取第csv第一行的变量key,在获取第二行的新值,进行替换。最后将他转化成字段。并返回数据。
param_list=[]
if lenght_flag:
for x in range(1,len(csv_list)):
temp_conf=str_conf
for y in range(0,len(csv_list[x])):
temp_conf=temp_conf.replace('$csv{'+csv_list[0][y]+'}',csv_list[x][y])
param_list.append(json.loads(temp_conf))
return param_list
else:
return conf
except Exception as error:
error_loging('csv数据替换出错%s'%traceback.format_exc())
allure报告装饰
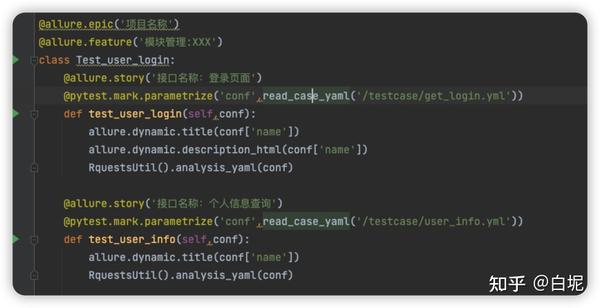

项目名称:@allure.epic(‘项目名称’)
模块名称:@allure.feature(‘模块名称’)在类的上方
接口名称: @allure.story(‘1’) 接口名称
allure.dynamic.title()用例标题。
日志的创建
class LoggerUtil:
def create_log(self, logger_name='log'):
#创建一个文件日志对象
self.logger=logging.getLogger(logger_name)
#设置文件全局日志级别
self.logger.setLevel(logging.DEBUG)
#防止日志重复
if not self.logger.handlers:
#获得日志文件名称
self.file_log_path=get_dir()+ '/logs/' + read_config_file('log','log_name')
#创建文件日志控制器
self.handler=logging.handlers.TimedRotatingFileHandler(self.file_log_path,when='midnight', interval=1, backupCount=7, atTime=datetime.time(0, 0, 0, 0))
self.fromatter=logging.Formatter(*read_config_file('log','log_format'))
#设置文件日志级别
file_log_lever=str(read_config_file('log','log_level')).lower()
if file_log_lever== 'debug':
self.handler.setLevel(logging.DEBUG)
if file_log_lever == 'info':
self.handler.setLevel(
http://
logging.INFO
)
if file_log_lever == 'warning':
self.handler.setLevel(logging.WARNING)
if file_log_lever == 'error':
self.handler.setLevel(logging.ERROR)
if file_log_lever == 'critical':
self.handler.setLevel(logging.CRITICAL)
self.handler.setFormatter(self.fromatter)
self.logger.addHandler(self.handler)
'''设置一个console日志级别'''
self.console=logging.StreamHandler()
#设置控制台日志日志级别
console_log_lever=str(read_config_file('log', 'log_level')).lower()
console_fromatter = logging.Formatter(*read_config_file('log', 'log_format'))
if console_log_lever== 'debug':
self.console.setLevel(logging.DEBUG)
if console_log_lever == 'info':
self.console.setLevel(
http://
logging.INFO
)
if console_log_lever == 'warning':
self.console.setLevel(logging.WARNING)
if console_log_lever == 'error':
self.console.setLevel(logging.ERROR)
if console_log_lever == 'critical':
self.console.setLevel(logging.CRITICAL)
self.console.setFormatter(console_fromatter)
# fmt = "[%(asctime)s]-[%(filename)s] %(funcName)s line:%(lineno)d [%(levelname)s]: %(message)s", datefmt = "%Y-%m-%d %H:%M:%S"
self.logger.addHandler(self.console)
return self.logger
def write_loging(log_name):
LoggerUtil().create_log().info(log_name)
def error_loging(lognname):
LoggerUtil().create_log().error(lognname)
raise Exception(lognname)
if __name__=='__main__':
LL=LoggerUtil()
write_loging('测试222')
# error_loging('测试mawnenqi')
封装思路:创建一个日志类方法,创建一个日志入口,设置日志的全局级别,添加日志处理器headers,将日志文件存放在文件夹里面,设置文件夹类型以天进行分割logging.handlers.TimedRotatingFileHandler ,设置处理器的日志级别。我是通过读取文件里面的配置进行判断,设置日志保存的格式self.handler.setFormatter(ogging.Formatter(*read_config_file('log','log_format'))) 将它添加到loger的对象里面
进行调用,控制台输出都差不多一样:logging.StreamHandler()
一个loger入口可以有多个处理器,将日志输出到不同的位置,这里注意的是,判断.logger.hander是否存在,如果存在会产生两条一样的日志。件判断不存在的时候创建,存在不创建。
如果觉得还可以的点点赞推荐书籍
