

excel to python 总结(pandas)


1、生成数据表
#读取文件
data=pd.read_excel('./excelandpython.xls')
#转化为DataFrame格式
df3=pd.DataFrame(data)
df3
#也可以把上面两个步骤合为一个步骤: df3=pd. DataFrame (pd.read_excel('./excelandpython.xls')
2、数据表检查
(1)数据表信息: df3.info ()
(2)查看数据维度(行、列): df3.shape
(3)查看行:①df3.head(5)--前5行 ②df3.tail(5)--后5行 ③df3.columns--返回列的名称
(4)查看空值:
①返回所有值:df3.isnull()
②返回某1列:df3['XX'].isnull()
③返回多列:df3 [[ 'x1列名','x2列名' ]] .isnull()
(5)查看唯一值:
df3['XX'].unique():重复值只显示1个
3、数据清洗
(1)处理空值
①删除空值:df3.dropna(how='any')
②填充空值:--平均值填充:df3['xx'].fillna(df3['xx'].mean()) ;--用0填充:df3['xx'].fillna(value=0)
(2)查看重复值:df3['xx'].duplicated().value_counts()
(3)删除重复值: df3.drop_duplicates("xx",inplace=True) /df3.drop_duplicates()
(4)值修改与替换:df3['xx'].replace("a","b")
(5)处理空格:df3['xx']=df3['xx'].map(str.strip)
#strip:用于移除字符串头尾指定的字符(默认为空格)或字符序列。注意:该方法只能删除开头或是结尾的字符,不能删除中间部分的字符。
(6)更换数据格式:df3['xx'].astype('int')
(7)更换数据列名:df3.rename(columns={'abc': 'cde'}) #有打印输出,原数据未改变
若是增加inplace=True,则替换原来的数据,原数据发生改变
(8)异常值过滤(人为定义)
①根据实际情况,定义异常值
cond=(a<=800) & (a>=100)
a[cond]
②3σ
cond=np.abs(data)>3*σ(如果是正态分布3)
a[cond]
(9)过滤数据filter
df3.filter(items=['price'])
4、数据预处理
(1)数据表合并(类似于VLOOKUP)
①left join :data3=pd.merge(data1,data2,on='xx列名',how='left')
②right join:data3=pd.merge(data1,data2,on='xx列名',how='right')
③inner join:data3=pd.merge(data1,data2,on='xx列名',how='inner')
④full join:data3=pd.merge(data1,data2,on='xx列名',how='outer')
(2)设置索引列
①设置索引:df3.set_index('xx列名'):把某一列作为索引
②重置索引:df3.reset_index()
5、数据提取
(1)获取数据:df3['xx列名']--1列 df3[['x1列名','x2列名']]
(2)按照标签提取( loc )- 标签就是行索引 :
①同时取3行:df3[["A","C","E"]]---A\C\E为索引名字
②索引与列名相结合:df3.loc['A'::2,['x1列名','x2列名']]--A是索引
(3)按照位置提取(iloc):
①单行索引:df3.iloc[0]--第1行
②多行索引:df3.iloc[[0,2,4]]--第1、3、5行;与上面df3[["A","C","E"]]取出来的数据一样
③索引与切片:df3.iloc[0:4,[0,2]]:行-前4行;列-第1列与第3列(索引不算为1列)
(4)按照标签和位置提取(ix):ix是loc和iloc的混合,既能按索引标签提取,也能按位置进行数据提取
df3.ix[:'C',:4]--左边代表行,右边代表列
(5)按照条件提取(区域和条件值):
data3.loc[data3['city'].isin(['shanghai','shenzhen'])]
总结:loc与iloc的区别
loc可以选区连续行或者单个列,列需是字符类型
ilco行列都是整数或者范围,相当于切片
6、数据增删
(1)数据删除
书写规则:DataFrame.drop(labels=None,axis=0, index=None, columns=None, inplace=False)
*axis 默认为0,指删除行,因此删除columns时要指定axis=1;
*index 直接指定要删除的行
*columns 直接指定要删除的列
*inplace=False,默认该删除操作不改变原数据,而是返回一个执行删除操作后的新dataframe;inplace=True,则会直接在原数据上进行删除操作,删除后无法返回。
①删除某两列:
方式1:data3.drop(['x1列名','x2列名'],axis=1) 方式2:data3.drop(columns=['B','C'])
②删除某两行:
方式1:data3.drop([0,1])--删除第1行和第2行 方式2: data3.drop(index=[0, 1])
df3.drop(labels=[2,8]) 默认情况下删除行
(2)数据插入
①插入行
append or concat
②插入列
data3.insert(0, 'x增列名', data3.pop('x减列名'))
7、数据筛选
(1)loc :Python中使用loc函数配合筛选条件来完成筛选功能。配合sum和count函数还能实现Excel中sumif和countif函数的功能。
①loc:多条件筛选
*精确筛选: data3.loc[(data3["x1列名"]=='beijing')&(data3["x2列名"]>200)]--保留所有列
data3.loc[(data3["x1列名"]=='beijing')&(data3["x2列名"]>200),['X1列名','x2列名','x3列名']]
*模糊筛选:data3.loc[data3['存货名称'].str.contains("摄像|手")] #筛选存货名称含有摄像或手的信息
②loc与sort
data3.loc[(data3["area"]!='beijing'),['X2列名','X3列名','X5列名',]].sort_values(['X2列名'],ascending=True)
③loc与sum(实现EXCEL中sumif的功能)
data3.loc[(data3["area"]!='beijing')|(data3["goods"]=="camera"),['code','goods','tax','profit']].sort_values(['goods'],ascending=True).profit.sum()
④loc与count(实现EXCEL中countif的功能)
data3.loc[(data3["area"]=='beijing')].profit.count()
(2)query
①一般筛选
data3.query("area==['beijing','shanghai']")
②与sum结合使用(实现EXCEL中的sumif功能)
data3.query("area==['beijing','shanghai']").profit.sum()
8、数据分类汇总:group by (计数与求和)
①sum
data3.groupby(["area","goodsname"])["profit","cost"].sum()
②count
data3.groupby(["area","goodsname"])["profit"].count()
③与agg函数相结合:
data3.groupby('area')['profit'].agg([len,np.sum, np.mean])--按地区分类,对profit进行求和和求平均
*获取按area分组后求profit列的最大值
data3.groupby(by="area").agg({"profit":"max"})
*获取按area分组后求profit列的最大值和最小值
data3.groupby(by="area").agg({"profit":["max","min"]})
*获取按area分组后求profit列的最大值和最小值以及cost列的最大值
data3.groupby(by="area").agg({"profit":["max","min"],"cost":"min"})
9、数据透视:pivot_table(也是一种数据分类汇总的方式,但功能比group by强大)
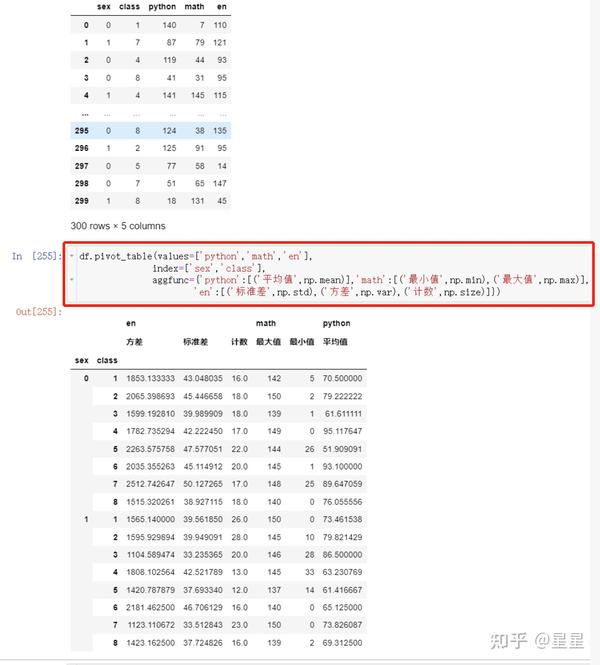
pd.pivot_table(df_inner,index=["city"],values=["price"],columns=[ "size"],aggfunc=[len,np.sum],fill_value=0,margins=True)
-index:行 column:列 values:值 fill_value空值填充值 margins汇总
①多行汇总(没有columns)
pd.pivot_table(data3,index=["area",'city'],values=["profit"],aggfunc=np.sum,fill_value=0,margins=True)
②多行多个汇总(没有columns)
pd.pivot_table(data3,index=["area",'city'],values=["profit"],aggfunc=[len,np.sum,np.mean],fill_value=0,margins=True)
③多行一列汇总
*pd.pivot_table(data3,index=["area",'city'],values=["profit"],columns=[ "goodsname"],aggfunc=np.sum,fill_value=0,margins=True)
*pd.pivot_table(data3,index=["area",'city'],values=["profit"],columns=[ "goodsname"],aggfunc=[len,np.sum,np.mean],fill_value=0,margins=True)
10、数据统计
①累加和df.cumsum()
②累乘和df.cumprod()
③标准差df.std()
④方差df.var()
⑤协方差df.cov()
⑥相关性系数df.corr()
11、数据输出
df_inner.to_Excel('Excel_to_Python.xlsx', sheet_name='abc')