上一篇:多表联查和新增——多对多
在customer表里新增四条数据
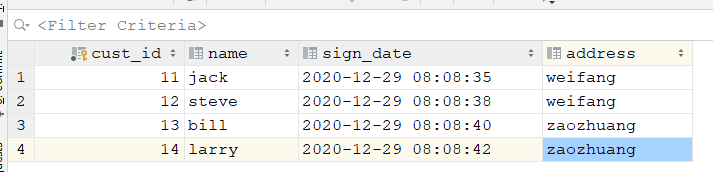
求得以下动态查询结果
select * from customer where name like ? and cust_id = ? and address like ?
在服务实现层
public Page selectiveSpecification(Long id,String name,String address) {
Specification specification =new Specification() {
@Override
public Predicate toPredicate(Root root, CriteriaQuery query, CriteriaBuilder criteriaBuilder) {
List<Predicate> predList = new LinkedList<>();</
上一篇:多表联查和新增——多对多在customer表里新增四条数据求得以下查询结果select * from customer where name like '%a%' and cust_id < 12在服务实现层@Override public Page findBySpecification() { Specification specification = new Specification() { @SneakyThrows
@ApiOperation("通用
查询
")
@ScSecurityPermission(name = "通用
查询
")
public ScResult find(FileInfo fileInfo,
@RequestParam(name="page", defaultValue="1") int page,
@Request.
z_user(id,name,age),z_role(id,name),z_role_user(id,user_id,role_id);
其中z_role_user是关联表,user和role的关系是多对多,所以用到了@ManyToMany注解;
下面是三个实体:
@Entity
@Table(name = "z_user")
public class UserX {
@Id()
@GeneratedValue(strategy = GenerationType.
* 用户管理的Dao接口
public interface UserRepositories extends JpaRepository<User, Integer>,JpaSpecificationExecutor<User>{
*
查询
全部,倒序
* @return
@Query(value = "select u from User u order b
Iterator iter = list.iterator();
while(iter.hasNext()){
Student student = (Student)iter.next();
if(i.equals(student.getParentid())){
list2.add(student.getId());
getAll(student.getId(),list);
return list2;
public List queryCategoryTree(Integer level) {
//
查询
当前级别下类目
List list = categoryDAO.list(level);
//组装好的类目树,返回前端
List categoryTree = new ArrayList();
//所有类目
List allDTOList = new ArrayList();
if (CollectionUtils.isEmpty(list)) {
return categoryTree;
for (CategoryDO categoryDO : list) {
allDTOList.add(new CategoryTreeDTO().convertDOToDTO(categoryDO));
//当前等级类目
categoryTree = allDTOList.stream().filter(dto -> level.equals(dto.getLevel())).collect(Collectors.toList());
for (CategoryTreeDTO categoryTreeDTO : categoryTree) {
//组装类目为树结构
assembleTree(categoryTreeDTO, allDTOList,Constants.CATEGORY_MAX_LEVEL - level);
return categoryTree;
* @return
public CategoryTreeDTO assembleTree(CategoryTreeDTO categoryTreeDTO, List allList, int remainRecursionCount) {
remainRecursionCount--;
//最大递归次数不超过Constants.CATEGORY_MAX_LEVEL-level次,防止坏数据死循环
if(remainRecursionCount < 0){
return categoryTreeDTO;
String categoryCode = categoryTreeDTO.getCategoryCode();
Integer level = categoryTreeDTO.getLevel();
//到达最后等级树返回
if (Constants.CATEGORY_MAX_LEVEL == level) {
return categoryTreeDTO;
//子类目
List child = allList.stream().filter(a -> categoryCode.equals(a.getParentCode())).collect(Collectors.toList());
if (null == child) {
return categoryTreeDTO;
categoryTreeDTO.setChildren(child);
//组装子类目
for (CategoryTreeDTO dto : child) {
assembleTree(dto, allList,remainRecursionCount);
return categoryTreeDTO;
DROP TABLE IF EXISTS `permission`;
CREATE TABLE `permission` (
`permission_id` int(11) NOT NULL COMMENT '主键id',
`permission_zh` varchar(255) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL COMMENT '菜单中文名称',
`permissi
spring-boot-starter-data-jpa是Spring Boot框架提供的一个starter(启动器)依赖,它的作用是简化使用JPA(Java Persistence API)进行数据持久化的开发。
通过引入spring-boot-starter-data-jpa依赖,你可以很方便地配置和使用JPA相关的组件和功能。它内部集成了Spring Data JPA,Spring Data Commons以及Hibernate等技术,提供了一套简化的API和默认的配置,使得开发者能够更快速、更便捷地进行数据库操作。
spring-boot-starter-data-jpa的主要功能包括:
1. 自动配置:它会根据你的项目中的配置和依赖情况,自动配置JPA相关的bean,如EntityManagerFactory、TransactionManager等。
2. 实体映射:它支持将Java实体类映射到数据库表,通过注解或XML配置来定义实体类与数据库表的映射关系。
3. 数据访问:它提供了一组通用的接口和方法,用于对数据库进行增删改查操作。你可以通过继承这些接口,或者使用Spring Data JPA提供的
查询
方法,来进行数据访问操作。
4. 事务管理:它集成了Spring的事务管理机制,可以方便地使用@Transactional注解来管理事务。
总之,spring-boot-starter-data-jpa简化了使用JPA进行数据库操作的配置和开发过程,提供了更高层次的抽象和更便捷的编程接口,帮助开发者提高开发效率。

