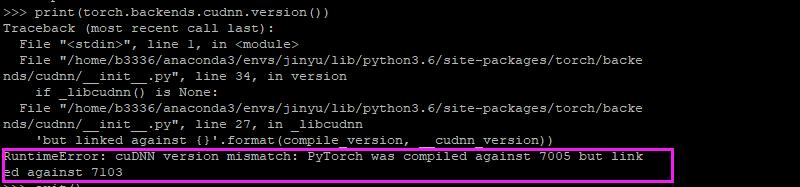
报错:RuntimeError:
cuDNN version mismatch:
PyTorch was
compiled against 7102 but
linked against 7301
解决办法:conda install
cudnn=7.1.2
计算单个模型的内存使用量
Model Sequential : params: 0.450304M
Model Sequential : interm
edite variables: 336.089600 M (without backward)
Model Sequential : interm
edite variables: 672.179200 M (with backward)
跟踪GPU内存使用量
# 30-Apr-21-20:25:29-gpu_mem_track.txt
该存储库包含一些用于语义分割的模型以及在
PyTorch中实现的训练和测试模型的管道
Vanilla FCN:分别为VGG,ResNet和DenseNet版本的FCN32,FCN16,FCN8( )
U-Net( )
SegNet( )
PSPNet()
GCN()
DUC,HDC()
PyTorch 0.2.0
PyTorch的TensorBoard。 安装
其他一些库(在运行代码时查找丢失的内容:-P)
转到models目录并在config.py中设置预训练模型的路径
转到数据集目录并按照自述文件进行操作
DeepLab v3
RuntimeError:
cuDNN version mismatch:
PyTorch was
compiled against 7102 but
linked against
7102 是
cudnn 7.1.2 的意思
7605 是
cudnn 7.6.5 的意思
重新安装一个
cudnn就好了 这边就安装
cudnn7.1.2
1、为什么会出现这个问题呢,
因为要运行pytorch做模型训练,自己安装了9.0的cuda和7.0.5的cudda,本以为ok了,运行程序出现标题字样的错误
2、首先翻译为Cudnn版本不兼容:PyTorch是针对7005编译的,但与6021链接
经过一顿百度,怀疑安装了dudda
python
import torch...
由于遇到了不能使用两块 k80GPU,
和pycharm 远程连接服务器的时候不能调试的问题:ImportError: dlopen: cannot load any more object with static TLS然后 conda install 的 pytorch 使用的 cudnn 版本的6的,使用
torch.backends.cudnn.version()来查看使用的 cunn
Gitee Pages(国内): ://apachecn.gitee.io/
pytorch-doc-zh
第三方站长[网站]
pytorch中文文档: ://www.bookstack.cn/search/result?wd
pytorch
地址A:xxx(欢迎留言,我们完善补充)
PyTorch官方入口
中文文档: :
克隆此仓库并运行代码
$ git clone https://github.
com/KaiyangZhou/
pytorch-center-loss
$ cd
pytorch-center-loss
$ python main.py --eval-freq 1 --gpu 0 --save-dir log/ --plot
您将在终端中看到以下信息
Currently using GPU: 0
Creating dataset: mnist
Creating model: cnn
== > Epoch
1.faster-rcnn训练报错
Load
ed runtime
CuDNN library: 7600 (
compatibility
version 7600) but source was
compiled with 7004;
Check fail
ed: stream->parent()->GetConvolveAlgorithms( conv_parameters.
目录文章简介Issues环境配置Ref-Reasoning数据集格式train(val)_expression.jsontrain(val)_sgs.jsontrain(val)_sg_seqs.json
Graph-Structured Referring Expressions Reasoning in The Wild
Issues
在作者代码的README中,有环境配置的步骤,不过python2.7+pytorch0.4.0支持的cuda版本和本机显卡支持的cuda版本
UnavailableInvalidChannel: HTTP 404 NOT FOUND for channel pytorch-lightning <https://conda.anaconda.org/pytorch-lightning> The channel is not accessible or is invalid. You will need to adjust your conda configuration to proceed. Use `conda config --show channels` to view your configuration's current state, and use `conda config --show-sources` to view config file locations.
这个错误提示是在使用 conda 安装 pytorch-lightning 时发生的。出现这个错误可能有以下原因:
1. pytorch-lightning 这个 channel 确实不存在或不可用。
2. conda 配置中缺少 pytorch-lightning 这个 channel。
3. conda 配置中 pytorch-lightning 这个 channel 的优先级低于其他 channel。
你可以尝试使用以下命令来添加 pytorch-lightning 这个 channel:
conda config --add channels pytorch-lightning
然后再尝试安装 pytorch-lightning,看看是否还会报错。如果还有问题,建议查看一下 conda 配置中其它 channel 的优先级,看是否与 pytorch-lightning 冲突。
secureCRT登录`No compatible key-exchange method. The server supports these methods: diffie-hellman`
42071