|
|
|



附一个page cache操作工具: caisonglu/cachemaster
------------------------------------------------------------------------------------
阿里云数据库团队急缺人缺各种人:底层内核/分布式系统/大数据分析/数据库内核/DevOPS系统开发/数据库中间件等开发。如有意向请私信我
语言不限:c/c++/java/golang/python/erlang 等
工作地点:杭州/北京/深圳/上海/西雅图/硅谷 等
------------------------------------------------------------------------------------
n年前写的一篇文章,顺手贴上了,mmap的行为远比大家想象得复杂,内存和IO茵曼不断,交织甚深,本文只对mmap函数本身做一些阐述。
mmap详解
1.函数定义
void *mmap(void *start, size_t length, int prot, int flags, int fd, off_t offset);
start起始地址,一般默认为NULL即可
length 映射长度,映射文件时一般设为文件长度
prot 内存区域权限,读、写、执行等
flags 做映射时的其他辅助标记
fd 文件描述符,非文件映射时设为-1
offset 偏移,映射文件时一般设为0
2.prot和flags解释
prot:
- prot_read 以读模式打开
- prot_write 以写模式打开
- prot_exec, prot_none 本文不表
- 多个模式可以组合,比如 PROT_READ|PROT_WRITE表示读写都可以
flags:
- MAP_SHARED 多个进程可以共享该映射,确切地说是共享改内存区域对应的物理页page frame,因为不同进程有不同的地址空间。
- MAP_PRIVATE 建立一个copy on write的映射,当对这块区域进行写操作的时候会重新建立到新的page frame的映射。
- MAP_LOCKED 将内存lock住,当系统进行page reclaim时会跳过这些带有locked标记的内存。这个标记也会触发文件的预读操作。
- MAP_ANONYMOUS 申请一块匿名页,和文件没有关系了
- MAP_POPULATE 对映射的文件进行预读,并且建立内存页表映射。可以理解为对数据的预热。
- 其他flag,本文不表
这些flag有些是互斥的,比如MAP_SHARED和MAP_PRIVATE,有些是可以混着使用的,比如MAP_SHARED|MAP_LOCKED。
3.各种应用场景与示例
3.1 为了方便观测mmap在各种场景下的行为,我们写了个测试程序
#include <iostream>
#include <sys/mman.h>
#include <sys/types.h>
#include <stdio.h>
#include <stdlib.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <errno.h>
using namespace std;
int main(int argc, char *argv[]){
if(argc<4){
cout<<"error parameter"<<endl;
exit(-1);
char *filename = argv[1];
int fd = open(filename, O_RDWR, 0644);
struct stat s;
if (fstat(fd, &s) < 0) {
close(fd);
return -1;
int prot = 0;
char *prot_str = argv[2];
if(strstr(prot_str, "PROT_READ") != NULL){
prot |= PROT_READ;
if(strstr(prot_str, "PROT_WRITE") != NULL){
prot |= PROT_WRITE;
int flag = 0;
char *flag_str = argv[3];
if(strstr(flag_str, "MAP_SHARED") != NULL){
flag |= MAP_SHARED;
if(strstr(flag_str, "MAP_PRIVATE") != NULL){
flag |= MAP_PRIVATE;
if(strstr(flag_str, "MAP_POPULATE") != NULL){
flag |= MAP_POPULATE;
if(strstr(flag_str, "MAP_LOCKED") != NULL){
flag |= MAP_LOCKED;
char *base = (char*)mmap(0, s.st_size, prot, flag, fd, 0);
volatile char ch;
for(int i=0; i<s.st_size; i+=4096){//测试时进行读操作
ch = base[i];
for(int i=0; i<s.st_size; i+=4096){//测试时进行写操作
base[i] = '\0';
cout<<"mmap region 0x"<<hex<<(long)base<<" "<<strerror(errno)<<endl;
sleep(1000);
munmap(base, s.st_size);
close(fd);
return 0;
}3.2 读+shared打开
a) 单个进程
命令:./m data 'PROT_READ' 'MAP_SHARED'
结果:cat /proc/$pid/smaps | grep data -A8
2adffd75c000-2ae01bfa4000 r--s 00000000 08:08 20657454 /home/zijia/cachemaster/data
Size: 500000 kB
Rss: 0 kB
Shared_Clean: 0 kB
Shared_Dirty: 0 kB
Private_Clean: 0 kB
Private_Dirty: 0 kB
Swap: 0 kB
Pss: 0 kBb) 两个进程
命令:两个终端执行 ./m data 'PROT_READ' 'MAP_SHARED'
结果:
进程1:
2b5f70509000-2b5f8ed51000 r--s 00000000 08:08 20657454 /home/zijia/cachemaster/data
Size: 500000 kB
Rss: 0 kB
Shared_Clean: 0 kB
Shared_Dirty: 0 kB
Private_Clean: 0 kB
Private_Dirty: 0 kB
Swap: 0 kB
Pss: 0 kB进程2:
2b26caf4a000-2b26e9792000 r--s 00000000 08:08 20657454 /home/zijia/cachemaster/data
Size: 500000 kB
Rss: 0 kB
Shared_Clean: 0 kB
Shared_Dirty: 0 kB
Private_Clean: 0 kB
Private_Dirty: 0 kB
Swap: 0 kB
Pss: 0 kBc) 单进程加上预读
命令: ./m data 'PROT_READ' 'MAP_SHARED|MAP_POPULATE'
结果:
2ac693023000-2ac6b186b000 r--s 00000000 08:08 20657454 /home/zijia/cachemaster/data
Size: 500000 kB
Rss: 500000 kB 文件都在物理内存中
Shared_Clean: 0 kB
Shared_Dirty: 0 kB
Private_Clean: 500000 kB 由于只读并且是单进程打开,private & clean
Private_Dirty: 0 kB
Swap: 0 kB
Pss: 500000 kB 平均占用物理页500Md) 两个进程加上预读
命令:两个终端执行 ./m data 'PROT_READ' 'MAP_SHARED|MAP_POPULATE'
结果:
2ac693023000-2ac6b186b000 r--s 00000000 08:08 20657454 /home/zijia/cachemaster/data
Size: 500000 kB
Rss: 500000 kB
Shared_Clean: 500000 kB 多个进程时变成shared clean
Shared_Dirty: 0 kB
Private_Clean: 0 kB
Private_Dirty: 0 kB
Swap: 0 kB
Pss: 250000 kB 占用的物理空间被平均到了250Me) 分析:
多个进程打开时,private clean变成shared clean,占用物理空间也因为平均变小。这种场景一般用在打开只读文件。
3.3 读+shared+lock打开
a) 单个进程
命令:./m data 'PROT_READ' 'MAP_SHARED|MAP_LOCKED'
结果:
2b685e23e000-2b687ca86000 r--s 00000000 08:08 20657454 /home/zijia/cachemaster/data
Size: 500000 kB
Rss: 500000 kB
Shared_Clean: 0 kB
Shared_Dirty: 0 kB
Private_Clean: 500000 kB
Private_Dirty: 0 kB
Swap: 0 kB
Pss: 500000 kBb) 多个进程
命令:./m data 'PROT_READ' 'MAP_SHARED|MAP_LOCKED'
结果:
2b685e23e000-2b687ca86000 r--s 00000000 08:08 20657454 /home/zijia/cachemaster/data
Size: 500000 kB
Rss: 500000 kB
Shared_Clean: 500000 kB
Shared_Dirty: 0 kB
Private_Clean: 0 kB
Private_Dirty: 0 kB
Swap: 0 kB
Pss: 250000 kBc) 分析:
带MAP_LCOKED标记时kernel自己会做映射和“预读”,和MAP_POPULATE时做预读的机制不同,后面会详细解释。这种场景一般应用在需要将文件lock在内存中的情形。
3.4 读写+shared打开(表现和读+shared打开相同)
3.5 读写+shared+lock打开
a) 单个进程
命令:./m data 'PROT_READ|PROT_WRITE' 'MAP_SHARED|MAP_LOCKED'
结果:
2b738ead2000-2b73ad31a000 rw-s 00000000 08:08 20657454 /home/zijia/cachemaster/data
Size: 500000 kB
Rss: 500000 kB
Shared_Clean: 0 kB
Shared_Dirty: 0 kB
Private_Clean: 0 kB
Private_Dirty: 500000 kB
Swap: 0 kB
Pss: 500000 kBb) 多个进程
命令:./m data 'PROT_READ|PROT_WRITE' 'MAP_SHARED|MAP_LOCKED'
结果:
2ab6d5450000-2ab6f3c98000 rw-s 00000000 08:08 20657454 /home/zijia/cachemaster/data
Size: 500000 kB
Rss: 500000 kB
Shared_Clean: 4144 kB
Shared_Dirty: 495856 kB
Private_Clean: 0 kB
Private_Dirty: 0 kB
Swap: 0 kB
Pss: 250000 kBc) 分析:
当带有shared和locked标记时,kernel会执行do_no_page函数,然后把page标记位dirty,后续通过iostat和其他工具可以验证该文件发生回写。我们甚至都没有对文件进行写操作,为什么kernel会把page标记为dirty呢,后续会有分析。
3.6 读+private打开(private方式下不支持MAP_POPULATE预读)
a) 单个进程
命令:./m data 'PROT_READ' 'MAP_PRIVATE'
结果:
2ae1c8d08000-2ae1e7550000 r--p 00000000 08:08 20657454 /home/zijia/cachemaster/data
Size: 500000 kB
Rss: 0 kB
Shared_Clean: 0 kB
Shared_Dirty: 0 kB
Private_Clean: 0 kB
Private_Dirty: 0 kB
Swap: 0 kB
Pss: 0 kBb) 多个进程(命令和结果同上)
c) 单进程加上预读,自己加几句代码实现
在mmap打开之后加上代码:
volatile char ch;
for(int i=0; i<s.st_size; i+=4096){
ch = base[i];
}命令:./m data 'PROT_READ' 'MAP_PRIVATE'
结果:
2b9aff9ed000-2b9b1e235000 r--p 00000000 08:08 20657454 /home/zijia/cachemaster/data
Size: 500000 kB
Rss: 500000 kB
Shared_Clean: 0 kB
Shared_Dirty: 0 kB
Private_Clean: 500000 kB
Private_Dirty: 0 kB
Swap: 0 kB
Pss: 500000 kBd) 多进程加上预读
命令:./m data 'PROT_READ' 'MAP_PRIVATE'
结果:
2b271ddc2000-2b273c60a000 r--p 00000000 08:08 20657454 /home/zijia/cachemaster/data
Size: 500000 kB
Rss: 500000 kB
Shared_Clean: 500000 kB
Shared_Dirty: 0 kB
Private_Clean: 0 kB
Private_Dirty: 0 kB
Swap: 0 kB
Pss: 250000 kBe) 结论:
当private方式打开时需要自己来预读,如果没有write操作,多个进程还是共享同一块物理内存。不过只读+private的场景很少,因为private本身就是为了write而存在。
3.7 读写+private打开
a) 当没有写操作时(结果同上)
b) 写操作+单进程
模拟写操作:
for(int i=0; i<s.st_size; i+=4096){
base[i] = '\0';
}结果:
2b70f7c01000-2b7116449000 rw-p 00000000 08:08 20657454 /home/zijia/cachemaster/data
Size: 500000 kB
Rss: 500000 kB
Shared_Clean: 0 kB
Shared_Dirty: 0 kB
Private_Clean: 0 kB
Private_Dirty: 500000 kB
Swap: 0 kB
Pss: 500000 kBc) 写操作+多进程
结果:结果与单进程同,各自占500M物理内存,而且都转成了匿名页
3.8 读写+private+lock打开
a) 单个进程
命令:./m data 'PROT_READ|PROT_WRITE' 'MAP_PRIVATE|MAP_LOCKED'
结果:
2ae8f0cd6000-2ae90f51e000 rw-p 00000000 08:08 20657454 /home/zijia/cachemaster/data
Size: 500000 kB
Rss: 500000 kB
Shared_Clean: 0 kB
Shared_Dirty: 0 kB
Private_Clean: 0 kB
Private_Dirty: 500000 kB
Swap: 0 kB
Pss: 500000 kBb) 多个进程
命令和结果都与单进程相同
c) 分析:
对private在程序中进行实际写和加MAP_LOCKED标记产生的效果相同,就是最后都转变为private_dirty,每个进程拥有各自的匿名页。
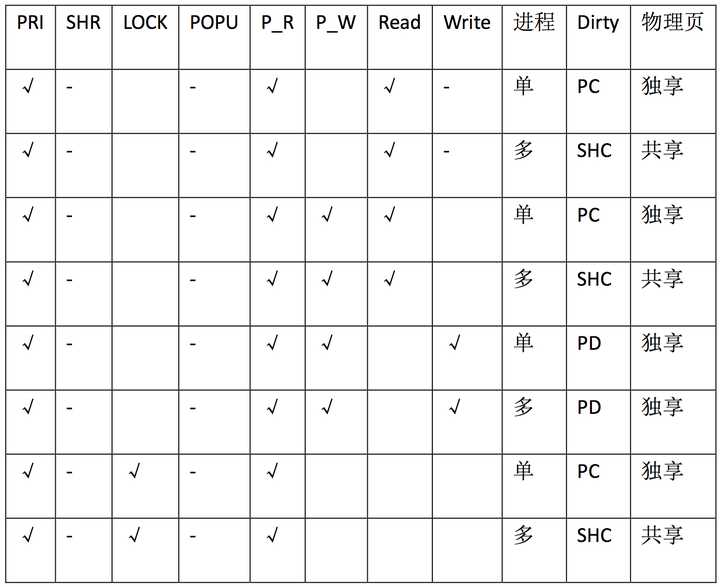
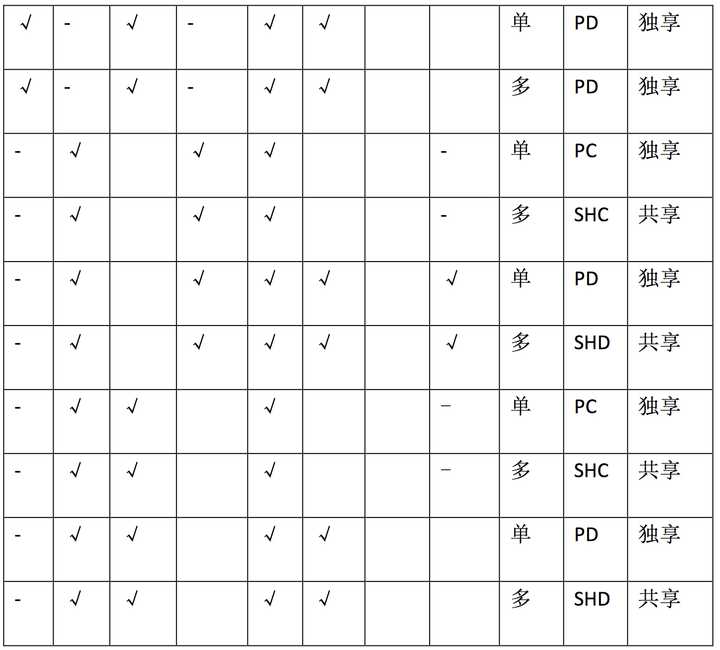
3.9 图表总结:
PRI:MAP_PRIVATE缩写
SHR:MAP_SHARED缩写
POPU:MAP_POPULATE缩写
P_R:PROT_READ缩写
P_W:PROT_WRITE缩写
PC:private_clean
PD:private_dirty
SHC:shared_clean
SHD:shared_dirty
单:表示单进程
多:表示多进程
物理页:就是物理内存page frame
Read:读内存操作,比如读一个内存地址的值。
Write:写内存操作,比如写值到一个内存地址。
√:表示设置该选项
-:表示该选项和其他选项互斥
4.部分现象分析
4.1 prot_write+预读之后是clean的,为何prot_write+map_lock之后却是dirty?
prot_write之后预读时会发生缺页中断,然后会调用函数do_page_fault,该函数原型为:
/*
* This routine handles page faults. It determines the address,
* and the problem, and then passes it off to one of the appropriate
* routines.
asmlinkage void __kprobes do_page_fault(struct pt_regs *regs, unsigned long error_code)这时传给函数的error code的第1位为0(位数从0开始),如果第1位被清0,表示异常由读访问或者执行访问引起,为1,异常由写访问引起,由于我们是在读的时候发生的缺页终端,该位为0,该位就是PF_WRITE。
接下来这个函数中有如下代码:
switch (error_code & (PF_PROT|PF_WRITE)) {
default: /* 3: write, present */
/* fall through */
case PF_WRITE: /* write, not present */
if (!(vma->vm_flags & VM_WRITE))
goto bad_area;
write++;
break;这个地方计算了一个变量write,当读访问导致缺页中断时write=0
后面接着调用:
handle_mm_fault(mm, vma, address, write)调用
int __handle_mm_fault(struct mm_struct *mm, struct vm_area_struct *vma,
unsigned long address, int write_access)调用
handle_pte_fault(mm, vma, address, pte, pmd, write_access);调用
static int do_no_page(struct mm_struct *mm, struct vm_area_struct *vma,
unsigned long address, pte_t *page_table, pmd_t *pmd,
int write_access)write最终传值给了write_access,这个write_access决定了后来一系列各种行为
在do_no_page函数中有代码:
/*
* Should we do an early C-O-W break?
if (write_access) {如果为1走这个分支
if (!(vma->vm_flags & VM_SHARED)) {如果是private打开的,会走这个分支
struct page *page;
if (unlikely(anon_vma_prepare(vma)))
goto oom;
page = alloc_page_vma(GFP_HIGHUSER, vma, address);
if (!page)
goto oom;
copy_user_highpage(page, new_page, address);从page cache copy到匿名页中
page_cache_release(new_page);
new_page = page;
anon = 1;设置匿名页标记,后面会用到
} else {如果是shared模式打开的,会走到该分支,这段代码没多少营养
/* if the page will be shareable, see if the backing
* address space wants to know that the page is about
* to become writable */
vfs_check_frozen(vma->vm_file->f_dentry->d_inode->i_sb,
SB_FREEZE_WRITE);
if (vma->vm_ops->page_mkwrite &&
vma->vm_ops->page_mkwrite(vma, new_page) < 0
page_cache_release(new_page);
return VM_FAULT_SIGBUS;
}省略该函数中间部分代码:
/*
* This silly early PAGE_DIRTY setting removes a race
* due to the bad i386 page protection. But it's valid
* for other architectures too.
* Note that if write_access is true, we either now have
* an exclusive copy of the page, or this is a shared mapping,
* so we can make it writable and dirty to avoid having to
* handle that later.
/* Only go through if we didn't race with anybody else... */
if (pte_none(*page_table)) {
flush_icache_page(vma, new_page);
entry = mk_pte(new_page, vma->vm_page_prot);
if (write_access) {如果为1
entry = maybe_mkwrite(pte_mkdirty(entry), vma);标记为dirty
dirty_pte++;
lazy_mmu_prot_update(entry);
set_pte_at(mm, address, page_table, entry);
if (anon) {
inc_mm_counter(mm, anon_rss);统计匿名页占用的物理内存
lru_cache_add_active(new_page);把该匿名页放到lru链表中
page_add_new_anon_rmap(new_page, vma, address);
unlock_page(new_page);
} else {//MAP_SHARED模式打开
inc_mm_counter(mm, file_rss);统计文件占用的物理页
page_add_file_rmap(new_page);设置NR_FILE_MAPPED统计项
unlock_page(new_page);
if (write_access) {如果为1
dirty_page = new_page;记录下当前page为dirty page,后续flush用
get_page(dirty_page);
} else {
/* One of our sibling threads was faster, back out. */
unlock_page(new_page);
page_cache_release(new_page);
goto unlock;
}从上述代码可以看出,如果用户读操作导致缺页中断,是不会产生dirty page的。
那我们看看prot_write+map_lock是如何产生dirty page的,当带上MAP_LOCKED标记时,走的是另外一个路径:
unsigned long do_mmap_pgoff(struct file * file, unsigned long addr,
unsigned long len, unsigned long prot,
unsigned long flags, unsigned long pgoff)其中有代码:
if (vm_flags & VM_LOCKED) {
mm->locked_vm += len >> PAGE_SHIFT;
make_pages_present(addr, addr + len); 表示立刻要把文件内容读到物理内存中
}接着调用:
int make_pages_present(unsigned long addr, unsigned long end)
int ret, len, write;
struct vm_area_struct * vma;
vma = find_vma(current->mm, addr);
if (!vma)
return -1;
write = (vma->vm_flags & VM_WRITE) != 0; 这个地方算出来的write为1
BUG_ON(addr >= end);
BUG_ON(end > vma->vm_end);
len = (end+PAGE_SIZE-1)/PAGE_SIZE-addr/PAGE_SIZE;
ret = get_user_pages(current, current->mm, addr,
len, write, 0, NULL, NULL); 干活的函数
if (ret < 0)
return ret;
return ret == len ? 0 : -1;
}接着调用:
int get_user_pages(struct task_struct *tsk, struct mm_struct *mm,
unsigned long start, int len, int write, int force,
struct page **pages, struct vm_area_struct **vmas)该函数部分代码:
vm_flags = write ? (VM_WRITE | VM_MAYWRITE) : (VM_READ | VM_MAYREAD);
vm_flags &= force ? (VM_MAYREAD | VM_MAYWRITE) : (VM_READ | VM_WRITE);
struct page *page;
if (write)
foll_flags |= FOLL_WRITE; 设置了FOLL_WRITE标记位
cond_resched();
while (!(page = follow_page(vma, start, foll_flags))) {
int ret;
ret = __handle_mm_fault(mm, vma, start,
foll_flags & FOLL_WRITE);接着调用:
int __handle_mm_fault(struct mm_struct *mm, struct vm_area_struct *vma,
unsigned long address, int write_access)和刚开始分析的代码接上头了,此时write_access为1,所以后面就有了dirty page
4.2 map_private+prot_write的内存如何变成匿名页?
上面的分析中我们看到,当再加上MAP_LOCKED标记时会导致copy on write
当写这块内存时,write_access=1,也会导致copy on write,而copy on write就产生了匿名页
5. 延伸讨论:文件预读(预热)
a) 何为预读?如何预读?
预读就是将文件中的的内容读到物理内存中,这是在很多系统中都存在的需求。Mmap文件预读有两层含义,一是将文件内容读到page cache中,二是建立虚地址空间和page cache的映射。
预读有多种方法,最简单的就是在外层cat一下要预热的文件,预读到page cache中,然后程序中访问时发生缺页中断,建立和page cache的映射;一种是自己在程序中做read,然后在顺序访问建立映射;一种是顺序访问mmap好的内存,发生缺页中断,然后再去从磁盘读文件;一种是用MAP_POPULATE或者MAP_LOCKED标记,当执行mmap映射时,就将文件读进来并建立好映射关系,这两个标记看起来预热效果差不多,但其实底层实现相差很多,预热速度也大不相同;还有一种是调用posix_fadvise函数预读文件到page cache,然后再顺序访问一次建立映射,本质上和cat那个方法差不多。
接下来分析集中预热方法的实现机制和耗时情况。
b) 外围cat,程序内部顺序访问
Cat会用read系统调用读文件到用户态buffer,而且cat有很多额外逻辑,比如要往外输出等。
耗时:顺序读文件到page cache+copy到用户态buffer+额外逻辑处理+顺序访问
c) 自己程序做顺序read,然后顺序访问
耗时:顺序读文件到page cache+copy到用户态buffer+顺序访问
d) 顺序访问mmap好的内存
如文章最开始的那种read方法,让缺页中断的处理程序去触发读文件的过程
但是这种方式有个缺点,就是读文件的效率不高,没法给读文件的过程做一些hint,如POSIX_FADV_WILLNEED这种标记位,文件系统不知道这种读操作是顺序的,虽然底层有io操作的合并,但是依然无法做出最优的处理。
耗时:半随机读文件到page cache+顺序访问
e) MAP_POPULATE
有这个标记时mmap会调用函数filemap_populate,这个函数会以最大的窗口去预读文件到page cache,然后在顺序访问建立映射。这种预读方式有个缺点就是没法和MAP_PRIVATE标记合用。
耗时:顺序读文件到page cache+顺序访问
f) MAP_LOCKED
和顺序访问mmap的内存原理差不多
耗时:半随机读文件到page cache+顺序访问
g) Posix_fadvise+顺序访问
调用函数posix_fadvise(POSIX_FADV_WILLNEED),将文件读取到page cache中,然后顺序访问。该方法适用于所有的文件和各种flag。
耗时:顺序读文件到page cache+顺序访问
h) 实验验证:
用上面提到的各种方法读取一个1G的文件,看谁的耗时更少
实验代码:
#include <iostream>
#include <sys/mman.h>
#include <sys/types.h>
#include <stdio.h>
#include <stdlib.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <errno.h>
#include <sys/time.h>
using namespace std;
#define READ_BUF_SIZE (1024*1024l)
void readall(int fd, char* buffer);
void visitall(char *base, size_t file_size);
float get_elapse_time(struct timeval *begin, struct timeval *end);
int main(int argc, char *argv[]){
if(argc<2){
cout<<"error parameter"<<endl;
exit(-1);
char *filename = argv[1];
int fd = open(filename, O_RDWR, 0644);
struct stat s;
if (fstat(fd, &s) < 0) {
close(fd);
return -1;
char *base = NULL;
char buffer[READ_BUF_SIZE];
struct timeval begin, end;
posix_fadvise(fd, 0, s.st_size, POSIX_FADV_DONTNEED);
gettimeofday(&begin, NULL);
base = (char*)mmap(0, s.st_size, PROT_READ, MAP_SHARED, fd, 0);
readall(fd, buffer);
visitall(base, s.st_size);
gettimeofday(&end, NULL);
cout<<"user read time used:"<<int(get_elapse_time(&begin, &end))<<" ms"<<endl;
munmap(base, s.st_size);
posix_fadvise(fd, 0, s.st_size, POSIX_FADV_DONTNEED);
base = (char*)mmap(0, s.st_size, PROT_READ, MAP_SHARED, fd, 0);
gettimeofday(&begin, NULL);
visitall(base, s.st_size);
gettimeofday(&end, NULL);
cout<<"sequntial page fault time used:"<<int(get_elapse_time(&begin, &end))<<" ms"<<endl;
munmap(base, s.st_size);
posix_fadvise(fd, 0, s.st_size, POSIX_FADV_DONTNEED);
gettimeofday(&begin, NULL);
base = (char*)mmap(0, s.st_size, PROT_READ, MAP_SHARED|MAP_POPULATE, fd, 0);
gettimeofday(&end, NULL);
cout<<"map populate time used:"<<int(get_elapse_time(&begin, &end))<<" ms"<<endl;
munmap(base, s.st_size);
posix_fadvise(fd, 0, s.st_size, POSIX_FADV_DONTNEED);
gettimeofday(&begin, NULL);
base = (char*)mmap(0, s.st_size, PROT_READ, MAP_SHARED|MAP_LOCKED, fd, 0);
gettimeofday(&end, NULL);
cout<<"map locked time used:"<<int(get_elapse_time(&begin, &end))<<" ms"<<endl;
munmap(base, s.st_size);
posix_fadvise(fd, 0, s.st_size, POSIX_FADV_DONTNEED);
gettimeofday(&begin, NULL);
base = (char*)mmap(0, s.st_size, PROT_READ, MAP_SHARED, fd, 0);
posix_fadvise(fd, 0, s.st_size, POSIX_FADV_WILLNEED);
visitall(base, s.st_size);
gettimeofday(&end, NULL);
cout<<"fadvise with sequential page fault time used:"<<int(get_elapse_time(&begin, &end))<<" ms"<<endl;
munmap(base, s.st_size);
close(fd);
return 0;
void readall(int fd, char* buffer){
while(read(fd, buffer, READ_BUF_SIZE) > 0);
void visitall(char *base, size_t file_size){
volatile char ch;