|
|
|
相关文章推荐

|
气势凌人的稀饭 · mybatis 动态SQL '@P0' ...· 6 月前 · |
|
|
率性的野马 · javascript - ...· 1 年前 · |
|
|
活泼的饼干 · JwtBearerExtensions.Ad ...· 1 年前 · |
|
|
焦虑的柳树 · CSS3绘制四个角不同半径的圆角边框_u01 ...· 1 年前 · |

从朱莉娅.csv文件中提取数据
问
从朱莉娅.csv文件中提取数据
EN
Stack Overflow用户
提问于
2022-08-16 11:20:30
回答 2
查看 164
关注 0
票数 4
我对朱莉娅非常陌生,我有一个.csv文件,它存储在一个gzip中,我想从中提取一些信息,用于教育目的,以便更好地了解该语言。
在Python中,Panda提供了许多有用的函数来帮助解决这个问题,但我似乎无法将问题弄清楚。
这是我的守则(我知道,很弱!):
{
import Pkg
#Pkg.add("CSV")
#Pkg.add("DataFrames")
#Pkg.add("CSVFiles")
#Pkg.add("CodecZlib")
#Pkg.add("GZip")
using CSVFiles
using Pkg
using CSV
using DataFrames
using CodecZlib
using GZip
df = CSV.read("Path//to//file//file.csv.gzip", DataFrame)
print(df)
}我添加了一个屏幕来显示.csv文件中的列是什么样的。
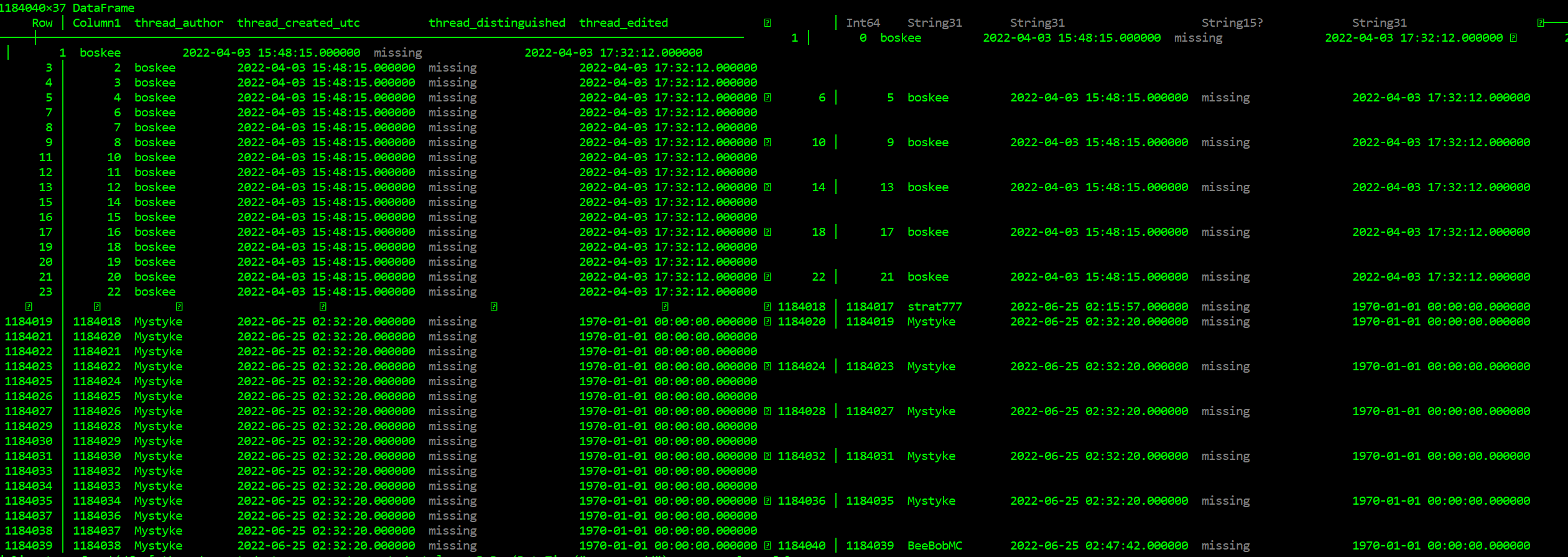
我想提取的日期,并作出一些前10名评论用户,前10天与最多的线程等。
我想指出,这不是给我的练习,而是我自己想做的训练。
我知道熊猫的版本是这样的:
df['threadcreateddate'] = pd.to_datetine(df['thread_created_utc']).dt.date或
df['commentcreateddate'] = pd.to_datetime(df['comment_created_utc']).dt.date为了分类:
pf_number_of_threads = df.groupby('threadcreateddate')["thread_id'].nunique()如果我要策划它:
df_number_of_threads.plot(kind='line')
plt.show()印刷:
head = df.head()
print(df_number_of_threads.sort_values(ascending=False).head(10))有人能帮忙吗?df.select()函数对我不起作用。
EN
回答 2
Stack Overflow用户
发布于 2022-08-16 21:06:27
1.一揽子计划
我们显然需要DataFrames.jl。而且,由于我们在处理数据中的日期,然后进行绘图,我们还将包括
Dates
和
Plots
。
正如CSV.jl文档中的
这个例子
所示,gzipped数据不需要额外的包。CSV.jl可以自动解压缩。因此,您可以从列表中删除其他
using
语句。
julia> using CSV, DataFrames, Dates, Plots2.数据框架的编制
您可以使用
CSV.read
将数据加载到数据帧中,如问题中所示。在这里,我将使用一些示例(简化)数据进行说明,其中只有4列:
julia> df
6×4 DataFrame
Row │ thread_id thread_created_utc comment_id comment_created_utc
│ Int64 String Int64 String
─────┼─────────────────────────────────────────────────────────────────
1 │ 1 2022-08-13T12:00:00 1 2022-08-13T12:00:00
2 │ 1 2022-08-13T12:00:00 2 2022-08-14T12:00:00
3 │ 1 2022-08-13T12:00:00 3 2022-08-15T12:00:00
4 │ 2 2022-08-16T12:00:00 4 2022-08-16T12:00:00
5 │ 2 2022-08-16T12:00:00 5 2022-08-17T12:00:00
6 │ 2 2022-08-16T12:00:00 6 2022-08-18T12:00:003.将字符串转换为DateTime
为了从我们拥有的字符串列中提取线程日期,我们将使用
Dates
标准libary。
根据日期的确切格式,您可能需要添加一个
datefmt
参数来将其转换为
Dates
数据类型(参见朱莉娅手册中的
建筑工人组
of
Dates
)。在示例数据中,日期是ISO标准格式,因此我们不需要显式地指定日期格式。
在Julia中,我们可以直接获得日期,而不需要中间转换为日期时间类型,但是由于无论如何都让列处于正确的类型是个好主意,所以我们首先将现有列从字符串转换为
DateTime
。
julia> transform!(df, [:thread_created_utc, :comment_created_utc] .=> ByRow(DateTime), renamecols = false)
6×4 DataFrame
Row │ thread_id thread_created_utc comment_id comment_created_utc
│ Int64 DateTime Int64 DateTime
─────┼─────────────────────────────────────────────────────────────────
1 │ 1 2022-08-13T12:00:00 1 2022-08-13T12:00:00
2 │ 1 2022-08-13T12:00:00 2 2022-08-14T12:00:00
3 │ 1 2022-08-13T12:00:00 3 2022-08-15T12:00:00
4 │ 2 2022-08-16T12:00:00 4 2022-08-16T12:00:00
5 │ 2 2022-08-16T12:00:00 5 2022-08-17T12:00:00
6 │ 2 2022-08-16T12:00:00 6 2022-08-18T12:00:00
虽然它看起来很相似,但是这个数据框架并没有对日期-时间列使用
String
s,而是有正确的
DateTime
类型值。(有关此
transform!
如何工作的说明,请参阅
DataFrames手册:选择和转换列
。)
编辑:根据现在添加到问题中的屏幕截图,在您的情况下,您将使用
transform!(df, [:thread_created_utc, :comment_created_utc] .=> ByRow(s -> DateTime(s, dateformat"yyyy-mm-dd HH:MM:SS.s")), renamecols = false)
。
4.创建日期列
现在,创建日期列很容易,就像:
julia> df.threadcreateddate = Date.(df.thread_created_utc);
julia> df.commentcreateddate = Date.(df.comment_created_utc);
julia> df
6×6 DataFrame
Row │ thread_id thread_created_utc comment_id comment_created_utc commentcreateddate threadcreatedate
│ Int64 DateTime Int64 DateTime Date Date
─────┼───────────────────────────────────────────────────────────────────────────────────────────────────────
1 │ 1 2022-08-13T12:00:00 1 2022-08-13T12:00:00 2022-08-13 2022-08-13
2 │ 1 2022-08-13T12:00:00 2 2022-08-14T12:00:00 2022-08-14 2022-08-13
3 │ 1 2022-08-13T12:00:00 3 2022-08-15T12:00:00 2022-08-15 2022-08-13
4 │ 2 2022-08-16T12:00:00 4 2022-08-16T12:00:00 2022-08-16 2022-08-16
5 │ 2 2022-08-16T12:00:00 5 2022-08-17T12:00:00 2022-08-17 2022-08-16
6 │ 2 2022-08-16T12:00:00 6 2022-08-18T12:00:00 2022-08-18 2022-08-16
这些代码也可以编写为
transform!
调用,实际上,以前代码段中的
transform!
调用可以替换为
df.thread_created_utc = DateTime.(df.thread_created_utc)
和
df.comment_created_utc = DateTime.(df.comment_created_utc)
。然而,
transform
提供了一个非常强大和灵活的语法,可以完成更多的任务,所以如果要使用DataFrames,那么熟悉它是很有用的。
5.每天获得线程数
julia> gdf = combine(groupby(df, :threadcreateddate), :thread_id => length ∘ unique => :number_of_threads)
2×2 DataFrame
Row │ threadcreateddate number_of_threads
│ Date Int64
─────┼──────────────────────────────────────
1 │ 2022-08-13 1
2 │ 2022-08-16 1
请注意,
df.groupby('threadcreateddate')
变成了
groupby(df, :threadcreateddate)
,这是Python转换中常见的模式。Julia不使用基于
.
的面向对象语法,相反,数据框架是函数的参数之一。
length ∘ unique
使用函数组合运算符
∘
,其结果是应用
unique
和
length
的函数。这里,我们在每个组中取
thread_id
列的
thread_id
值,将
length
应用于它们(因此,等效于
nunique
),并将结果存储在名为
gdf
的新
GroupedDataFrame
中的
number_of_threads
列中。
6.密谋
julia> plot(gdf.threadcreateddate, gdf.number_of_threads)由于我们的分组数据框架可以方便地同时包含日期和线程数,所以我们可以根据日期绘制number_of_threads,从而实现一个良好的、信息丰富的可视化。
票数 5
EN
Stack Overflow用户
发布于 2022-08-16 19:16:54
正如Sundar R评论的那样,很难对你的数据给出一个准确的答案,因为可能会有一些相关的细节。但是,下面是您可以遵循的一般模式:
julia> using DataFrames
julia> df = DataFrame(id = [1, 1, 2, 2, 2, 3])
6×1 DataFrame
Row │ id
│ Int64
─────┼───────
1 │ 1
2 │ 1
3 │ 2
4 │ 2
5 │ 2
6 │ 3
julia> first(sort(combine(groupby(df, :id), nrow), :nrow, rev=true), 10)
3×2 DataFrame
Row │ id nrow
│ Int64 Int64
─────┼──────────────
1 │ 2 3
2 │ 1 2
3 │ 3 1此代码所做的工作:
-
groupby按要聚合的列对数据进行分组 -
带有
combine参数的nrow计数组中的行数,并将其存储在:nrow列中(默认情况下,可以选择其他列名) -
sort通过:nrow对数据帧进行排序,rev=true对数据帧进行降阶。 -
first从这个数据帧中选择10行
如果您想要更类似于R中有管道的dplyr的内容,可以使用由
@chain
导出的DataFramesMeta.jl:
julia> using DataFramesMeta
julia> @chain df begin
groupby(:id)
combine(nrow)
sort(:nrow, rev=true)
first(10)
3×2 DataFrame
推荐文章