

Pandas-数据筛选

我们对 pandas 有了初步的认识,今天我们来学习一些 pandas 中更高阶的知识点。
数据筛选
还是以上一关的
2019年销售数据.csv
为例,我们想要筛选出那些总销售额低于平均值的销售员,同样也只要一行代码即可:


这和 NumPy 中数组的
布尔索引
是一样的,中括号里是筛选条件,返回值是所有符合条件的数据。
df['总和'] < df['总和'].mean()
的结果如下:
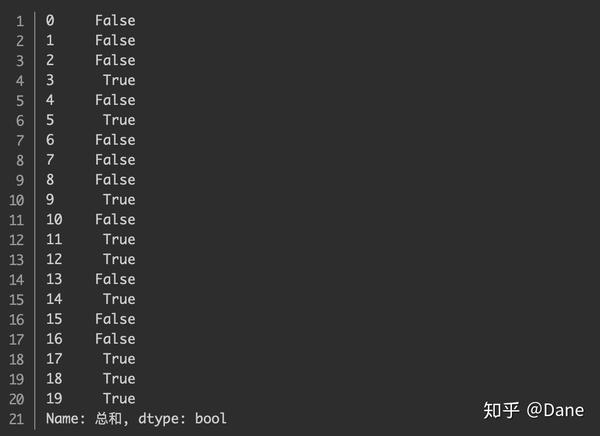
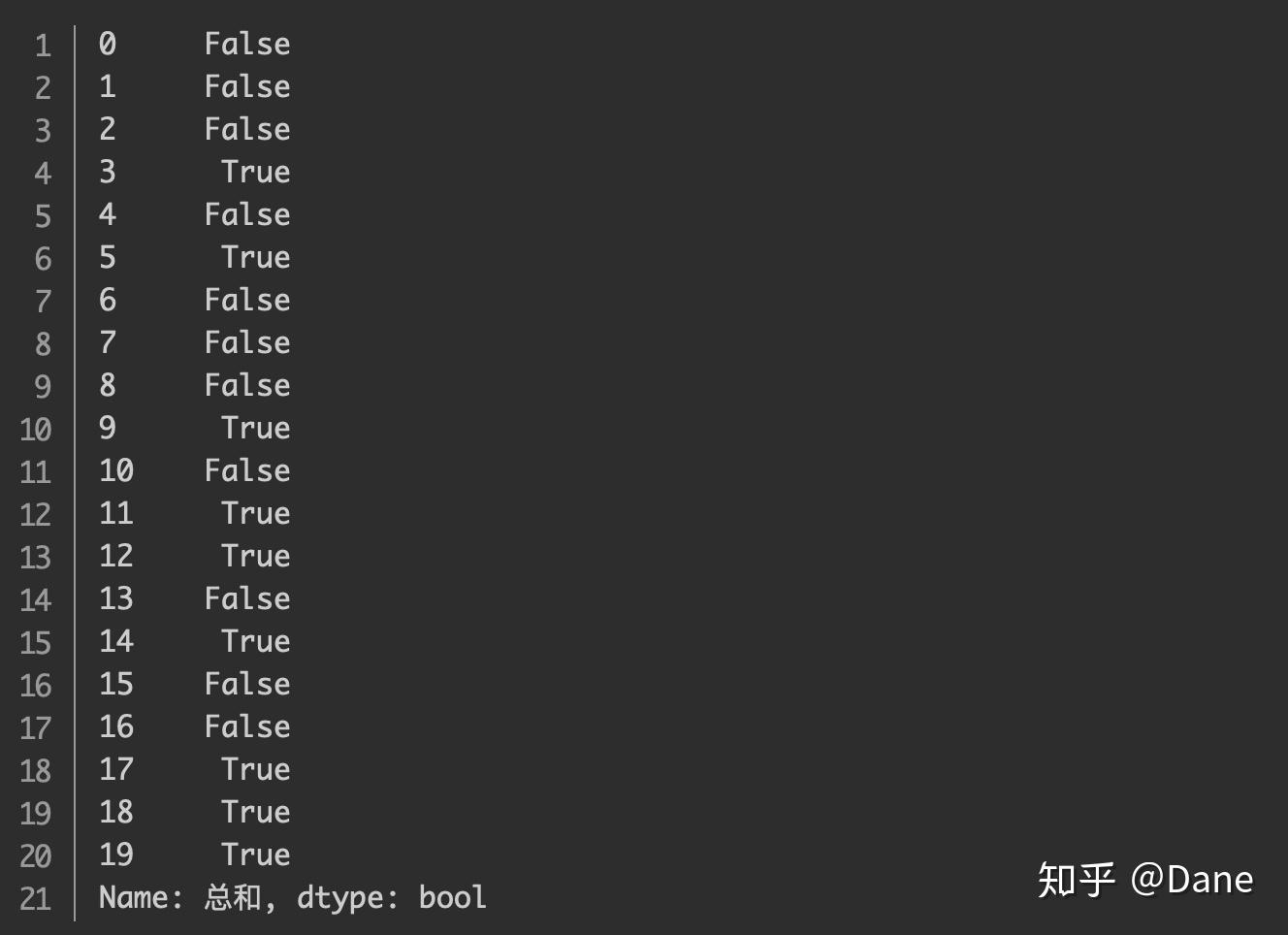
符合条件的为 True,不符合条件的为 False。最终
df[df['总和'] < df['总和'].mean()]
会去除所有结果为 False 的行,只保留下结果为 True 的。最终的返回结果如下:
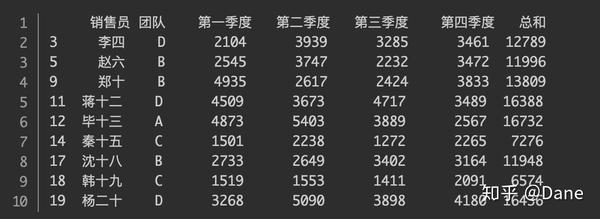
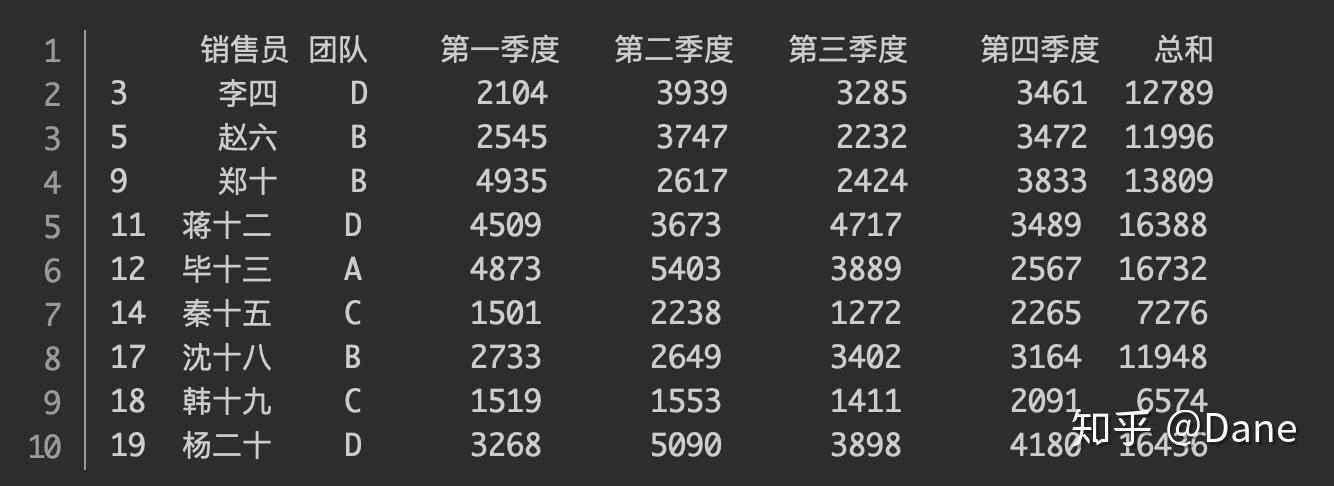
这些人的业绩低于公司业绩的平均值,绩效不合格,需要重点关注他们,帮他们提高业绩。
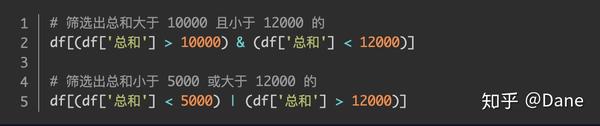
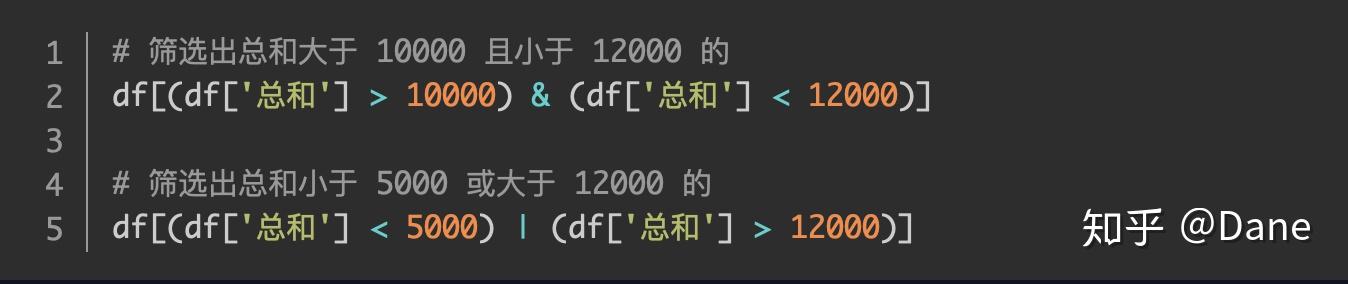
我们也可以写多个条件进行判断,在 pandas 中要表示同时满足,各条件之间要用 & 符号连接。如果要表示只要满足之一,各条件之间要用 | 符号来连接。并且每个条件要用括号括起来,举个例子:


给数据打标签
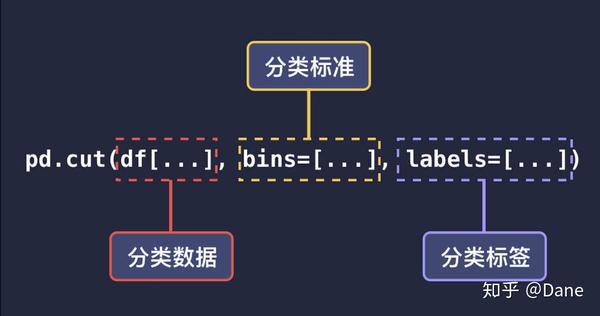
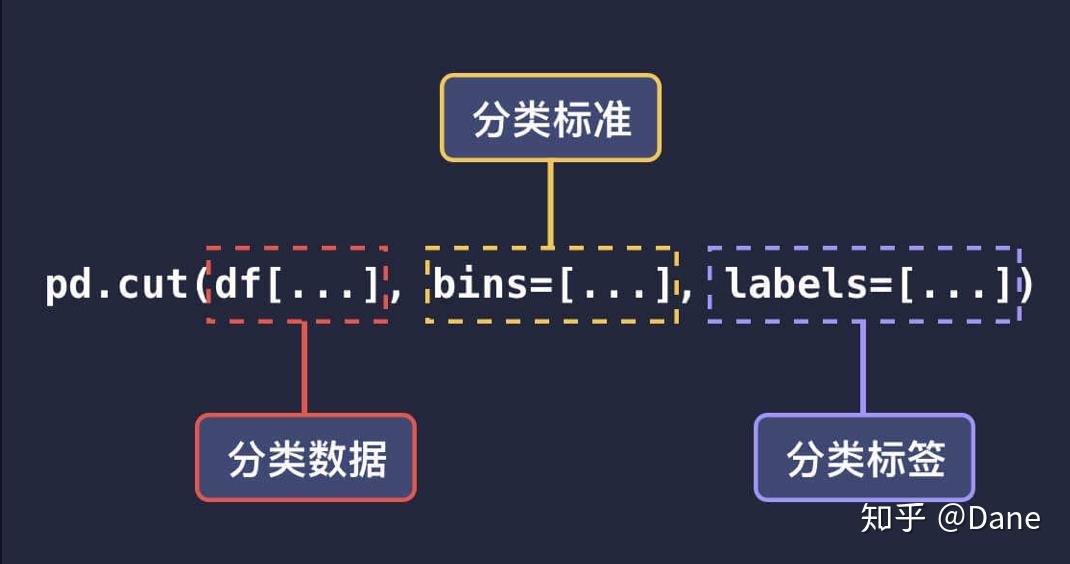
pandas 的
cut()
方法常用于数据的分类和打标签,它的主要参数和用法如下:


第一个参数是要分类的列,参数
bins
是分类的方式,即分类区间。默认是左开右闭,上面的例子中表示按
(0, 1000]
、
(1000, 2000]
和
(2000, 3000]
分为三组。如果你想要左闭右开的方式,可以再添加一个参数
right=False
。
最后的参数
labels
分别对应了这三组的标签名。即
(0, 1000]
表示不合格,
(1000, 2000]
表示良好,
(2000, 3000]
表示优秀。
应用到我们的例子当中,需要按平均值来分类,对应的代码如下:


调用
head()
方法查看上述的前 5 条结果,显示如下:


绩效分打好了,我们还需要将其作为一列添加到表格当中,方法如下:


我们调用
print(df.head())
来查看一下效果。
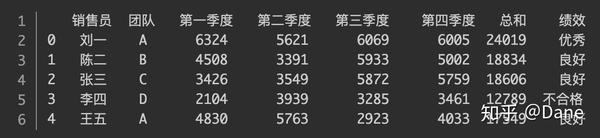
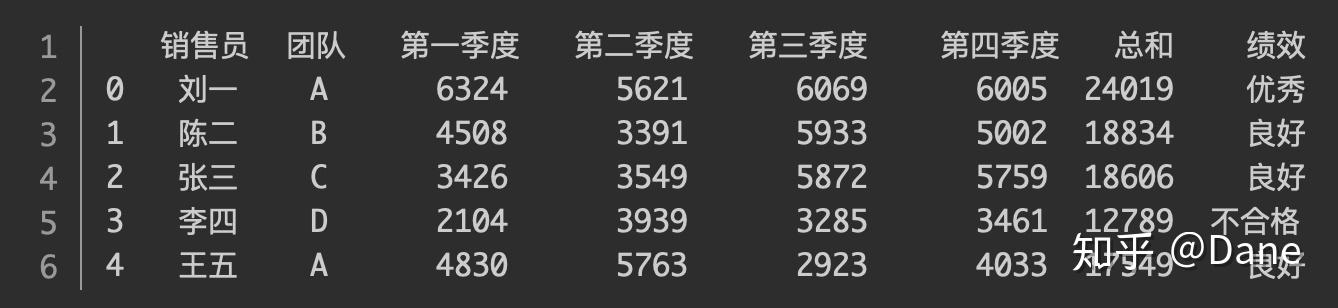
可以看到,使用 pandas,只要一行代码就完成了对员工的绩效评分。
之前我们都是对列进行操作,接下来我们一起看看关于行的操作。
行的查改增删
首先,我们用 DataFrame 构建一个简单的表格:


然后我们能得到下面这样的表格:


列是通过列名来获取的,同理,行是通过最左边的索引来获取。在不指定的情况下,索引值默认从 0 开始依次递增。我们可以使用
loc
基于索引进行表格行的查改增删。
查看行
以查看上面表格中第一行的数据为例,代码如下:


注意,
loc
并不是一个方法,而是类似于字典。所以我们使用的是
[]
而不是
()
,这里千万不要用错。这样我们就能得到第一行的数据,运行结果如下:


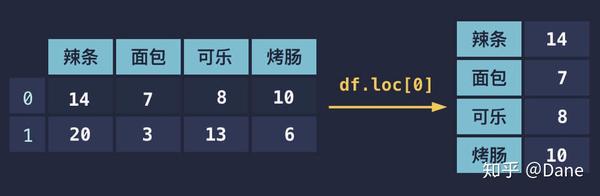
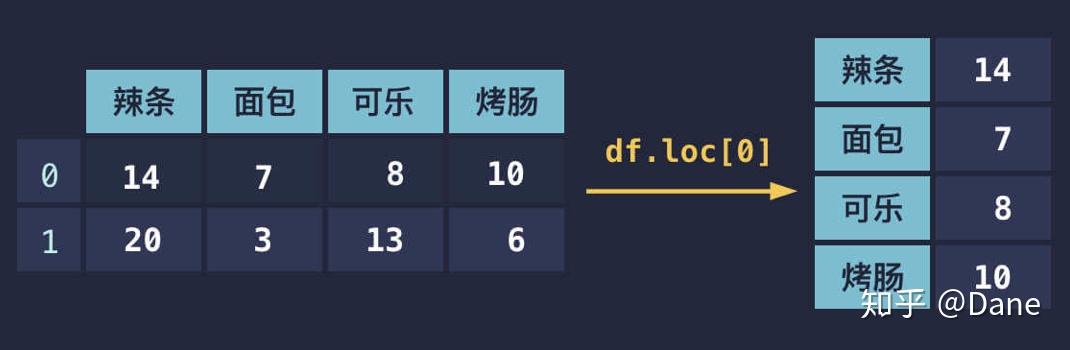
如果你在构建表格时像下面这样单独设置了索引,同样也可以用对应的索引值来获取表格行的数据:
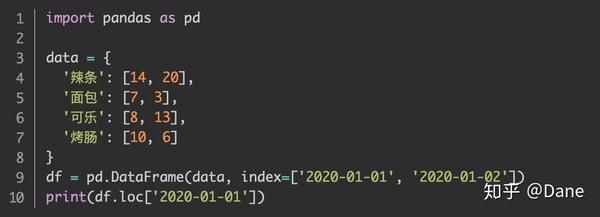
上面的代码中,表格的索引是日期。我们查看对应日期的数据时就需要将对应的日期作为索引,运行结果如下:


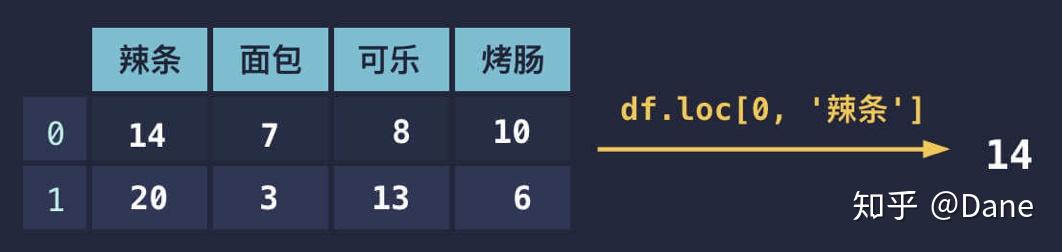
除了第一个参数索引外,还支持第二个参数列名。即同时基于行和列获取指定的数据,比如:


上面代码的意思是获取行为 0 且列为辣条的数据,运行的结果为 14。

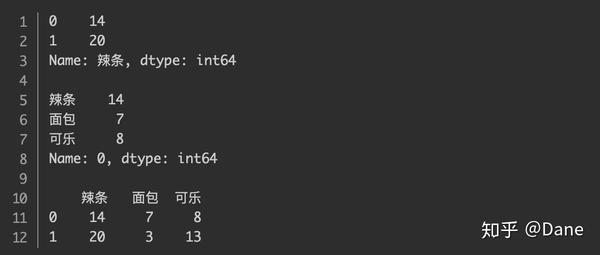
同时,行和列还支持分片的写法,我们来看几个例子:


需要注意的是,这里的分片和 Python 中列表的分片不太一样,这里的分片结果是 前后都包含 的,而列表分片只包含前面不包含后面。上面代码的运行结果分别如下:
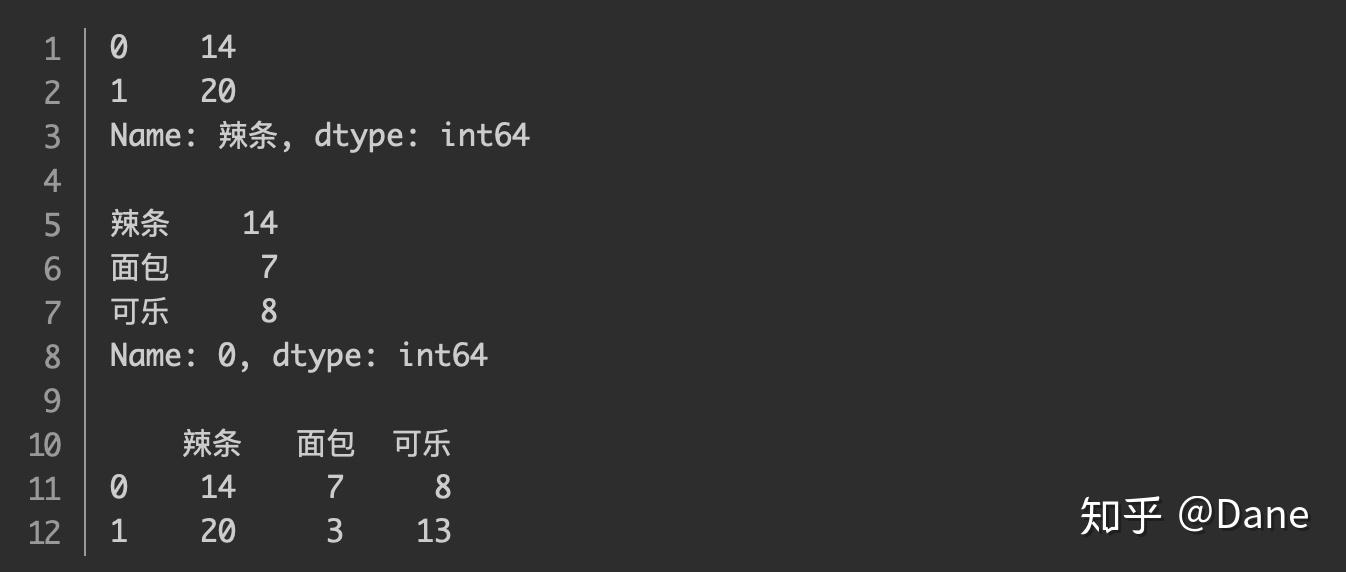
你也可以通过省略冒号前后的内容来实现全选,例如:
df.loc[:, '辣条':'可乐']
,这一点和列表的分片是一样的。
loc
同时也支持布尔索引来进行数据的筛选,比如获取辣条销量大于 15 的数据:


上面的写法等价于
df[df['辣条'] > 15]
,不同之处在于
loc
还能通过第二个参数筛选出只想查看的列,比如:




多条件筛选的写法前面说过,这里不再赘述。最后来总结一下
loc
的语法:
除了比较常用的
loc
之外,我们还能使用
iloc
。用法和
loc
一样,区别在于
loc
使用的参数是索引,而
iloc
的参数是位置,即第几行。
因此,在不指定索引的情况下,
loc
和
iloc
的效果是一样的。但当单独指定了索引,我们想获取前 3 行数据时可以像下面这样写:
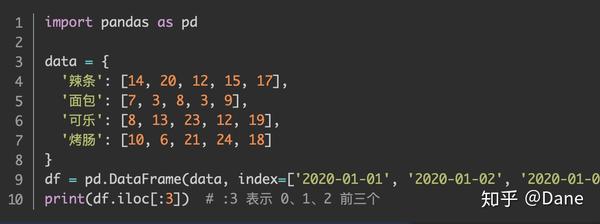
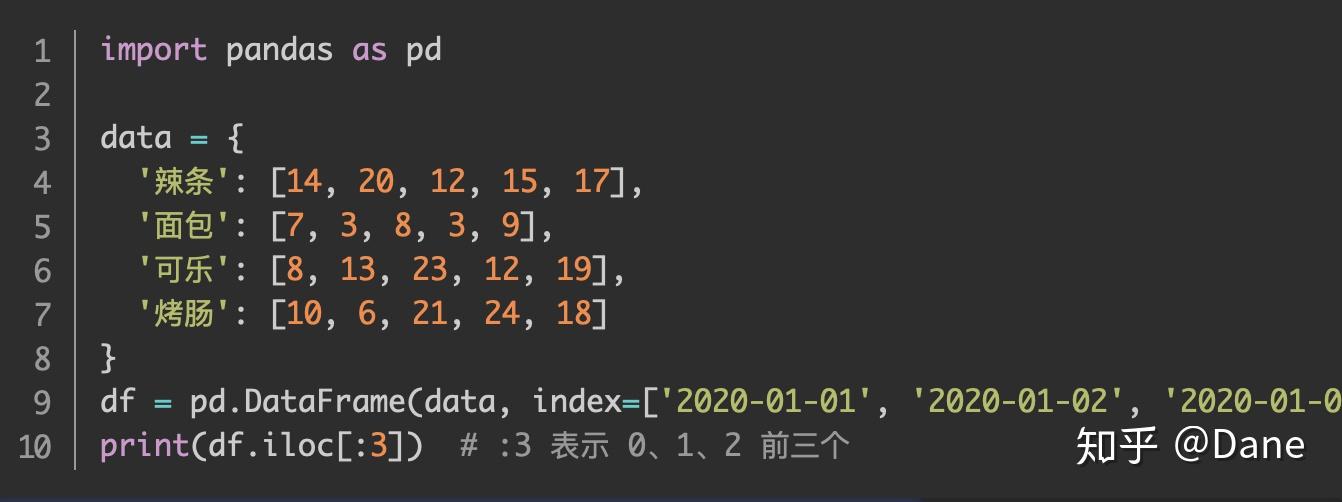
索引变成了日期,想要按位置获取数据的话只能使用
iloc
,这时如果使用
df.loc[:3]
将会报错。上面的代码运行结果如下:


注意,
iloc
的分片和 Python 的列表分片一样,要和
loc
的分片规则区分开来。
修改行
假设某行的数据有问题,我们需要进行修正。修改起来同样也很简单,直接赋值即可。这里分为两种情况:
- 赋值为一个数字;
- 赋值为长度和列数相等列表。


对于第一种情况,这一行所有的数据都会被修改成同样的数字:




第二种情况则是按列表顺序修改对应的列:




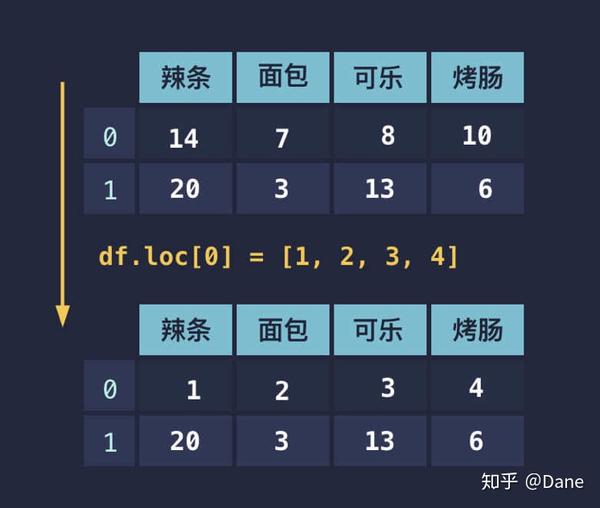
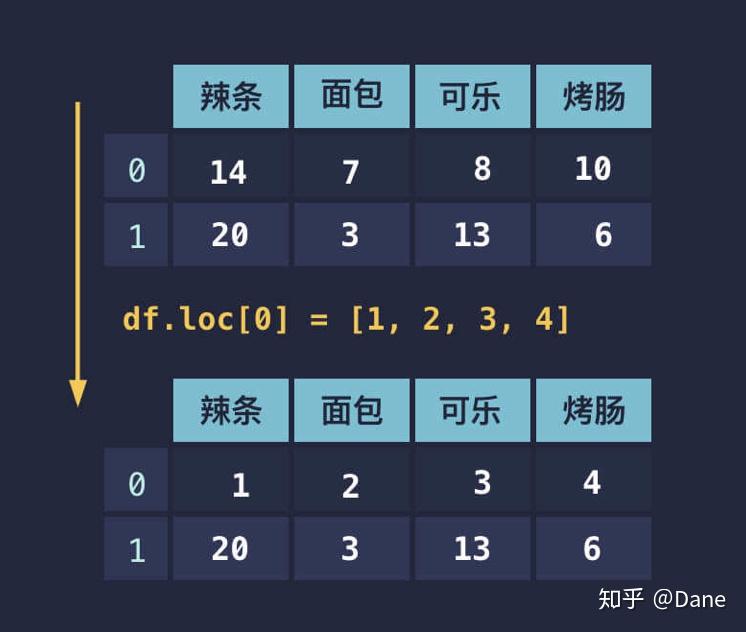
当然你也可以使用例如
df.loc[0, '辣条'] = 23
定位到行和列来修改特定的数据。
新增行
你应该也发现了,行和列的基本操作都是类似的,只是具体的方式不同。新增行也是如此,只需传入表格中不存在的索引即可。




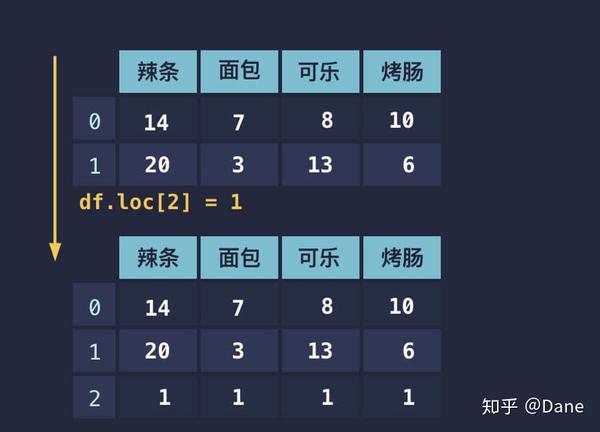
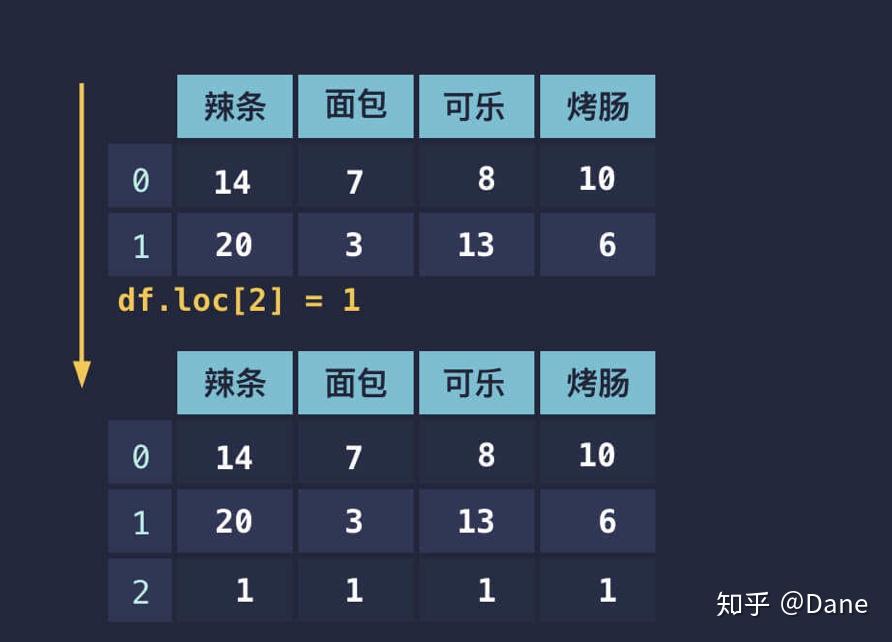
删除行
删除行和删除列一样,都是使用
drop()
方法。删除列的使用传入了
axis=1
表示对列进行删除,
axis
默认为 0,因此删除行时省略
axis
参数即可。




在前面的案例中,公司老板嘉奖完最佳销售员工后,想知道哪个团队的总销售额最高,再给最佳销售团队颁个奖。这个任务对 pandas 来说也是小菜一碟,我们一起来看看如何解决。
最佳销售团队
pandas 提供了
groupby()
方法用于数据的分组,第一个参数用于指定按哪一列进行分组。我们要按团队分组就可以像下面这样写:


但仅仅进行分组是没有结果的,还需要调用
max()
、
min()
、
mean()
、
sum()
等方法进行分组后的计算。要找出最佳销售团队的话,就需要对其求和,即调用
sum()
方法。


分组统计后的结果如下:
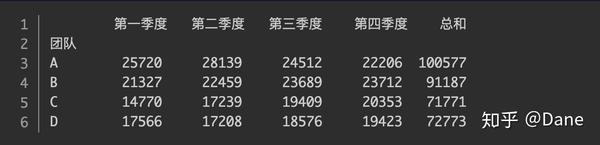

pandas 自动帮我们对第一到第四季度以及总和的销售额进行了求和,能很清晰地看出每个团队的销售情况。
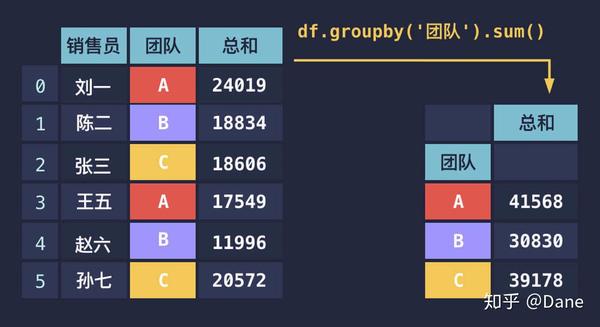
我们再对它按总和排个序来找到最佳销售团队:


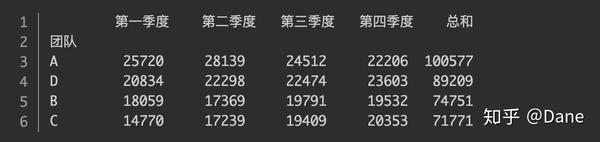
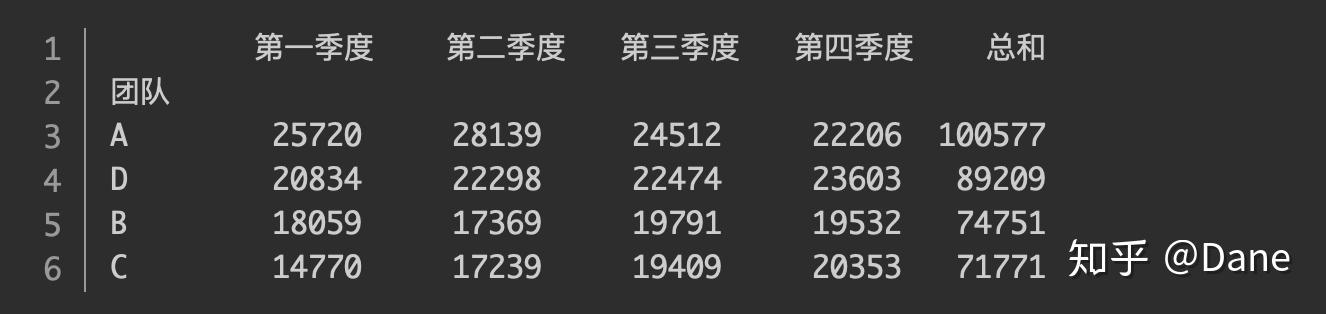
可以看到,A 团队是最佳销售团队,而 C 团队则销售额垫底。
我们还能调用
mean()
方法查看各个团队的平均销售额:

