YOLO系列目标
检测
数据集大全目标
检测
数据集无人机
检测
数据集飞鸟
检测
数据集人脸和口罩
检测
数据集安全帽
检测
数据集火焰
检测
数据集火焰和烟雾
检测
数据集行人
检测
数据集行人车辆
检测
数据集车辆
检测
数据集待更新……
目标
检测
数据集
无人机
检测
数据集
数据集下载:
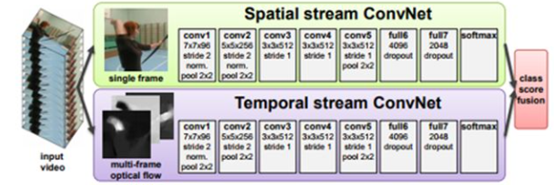
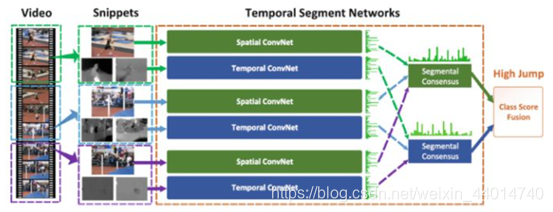
在这篇文章中,我们将介绍一些方法来制作用于
人体
行为识别
的视频分类器。在我们讨论视频分类之前,让我们先了解一下什么是
人体
行为识别
。简单地说,对某人正在执行的活动/动作进行分类或预测的任务称为活动识别。我们可能会有一个问题:这与普通的分类任务有什么不同?这里的问题是,。看看这个人做的这个后空翻动作,我们只有看完整的视频才能判断这是一个后空翻。
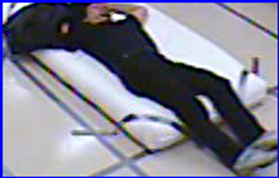
如果我们提供的模型只是来自视频片段的随机快照(如下图),那么它可能会错误地预测动作。
如果一个模型只看到上面的图像,那么它看起来有点像这个人正在下降,所以它预测会下降。
3D Photography Dataset
Multiview stereo data sets: a set of images
Multi-view Visual Geometry group’s data set
Dinosaur, Model House, Corridor, Aerial views, Valbonne Church, Raglan Castle, K
参考文献:https://arxiv.org/abs/2004.07485v1
代码实现:https://github.com/MVIG-SJTU/AlphAction
Asynchronous Interaction Aggregation for Action Detection
理解交互是视频动作
检测
的重要组成部分。我们提出了异步交互聚合网络(AIA),它利用不同的交互促进动作
检测
。其中有两个关键设计:一是交互聚合结构(IA),采用统一的范式对多种交互类型进行建模和集成;另一种是异步内存更新算法