package org.example.service;
import java.io.IOException;
import java.net.Socket;
import java.nio.charset.StandardCharsets;
public class InvokeModel {
public static void main(String[] args){
System.out.println(invoke(54.4, 14.4));
public static String invoke(Double sale1, Double sale2) {
String req = sale1 + "," + sale2;
Socket socket = null;
try {
socket = new Socket("127.0.0.1", 10001);
socket.getOutputStream().write(req.getBytes(StandardCharsets.UTF_8));
System.out.println("Request param: " + req);
byte[] buf = new byte[256];
int len = socket.getInputStream().read(buf);
return new String(buf, 0, len);
} catch (IOException e) {
throw new RuntimeException(e);
} finally {
try {
if (socket != null)
socket.close();
} catch (IOException e) {
System.err.println("Invoke model error");
本文示例是一个典型的时间序列处理办法,可以当作经典来用。读者可以多花一些时间消化该案例;事实表明,用LSTM这种工具不仅可以处理NLP,而且可以针对任何的时间序列,比如股票预测。
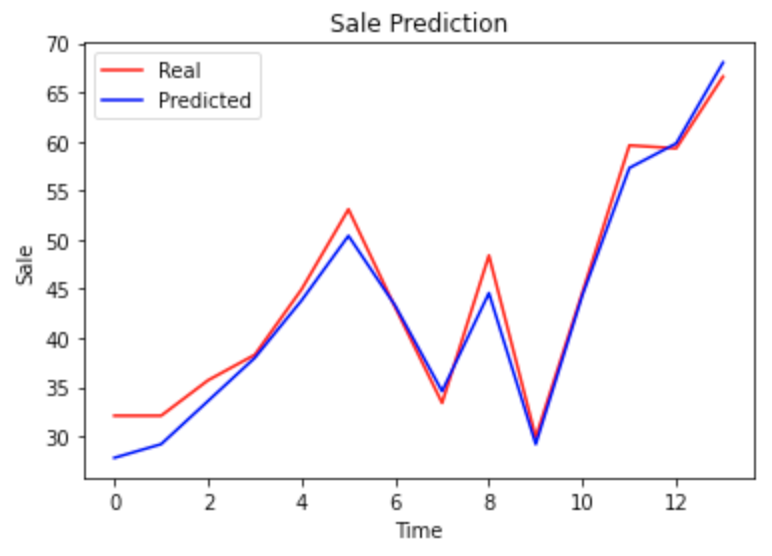
本文主要讲述了如何使用ARIMA和SARIMA模型对Perrin Freres香槟公司的销售数据进行时间序列预测。通过对1964年到1972年的数据进行分析,我们处理了缺失值,进行了单位根检验和差分,然后利用ACF和PACF确定模型参数。通过超参数搜索,我们选择了最优的模型进行预测。最后,我们保存了训练好的模型,并使用它进行未来的销售预测。
提供此竞赛是为了在相对简单和干净的数据集上探索不同的时间序列技术。给定 5 年的商店商品销售数据,并要求您预测 10 家不同商店的 50 种不同商品在 3 个月内的销售额。处理季节性的最佳方法是什么?商店应该单独建模,还是可以将它们合并在一起?深度学习是否比 ARIMA 更有效?可以击败xgboost吗?这是探索不同模型和提高预测技能的绝佳竞赛。这 有马 模型是可应用于非平稳时间序列的 ARMA 模型的推广。
LSTM模型的一个常见用途是对长时间序列数据进行学习预测,例如得到了某商品前一年的日销量数据,我们可以用LSTM模型来预测未来一段时间内该商品的销量。但对于不熟悉神经网络或者对没有了解过RNN模型的人来说,想要看懂LSTM模型的原理是非常困难的,但有些时候我们不得不快速上手搭建一个LSTM模型来完成预测任务。下面我将对一个真实的时间序列数据集进行LSTM模型的搭建,不加入很多复杂的功能,快速的完成数据预测功能。
问题大概如下:某煤矿有一个监测井,我们每20分钟获...
● 数字员工替代人工完成重复繁琐的工作,从而释放大量人力专注于战略性、创新性的任务,不仅能提高员工潜能,使员工获得更满意的工作体验,同时能为企业创造出更大价值。● 在合适的流程部署数字员工的成本远低于雇佣人工,与人工相比,数字员工7*24小时工作不停歇,工作处理速度快,可控且准确率高,避免了人为错误造成的麻烦。● 不需要编程经验,“乐高式”拼接方式,简单易学,人人都可以使用,让企业快速打破技术壁垒,提高员工的“科技获得感”,重构企业价值链。