|
|
|


Dataphin支持创建Flink SQL代码任务。本文为您介绍如何基于Ververica Flink引擎创建Flink SQL任务。
背景信息
阿里云实时计算Flink版是一套基于Apache Flink构建的⼀站式实时大数据分析平台,提供端到端亚秒级实时数据分析能力,并通过标准SQL降低业务开发门槛,助力企业向实时化、智能化大数据计算升级转型。
前提条件
在开始执行操作前,请确认项目已开启实时引擎并已配置Ververica Flink计算源。具体操作,请参见 创建项目 。
步骤一:新建Flink SQL任务
-
在Dataphin首页,单击顶部菜单栏 研发 。
-
按照下图操作指引,进入 新建Flink_SQL任务 对话框。
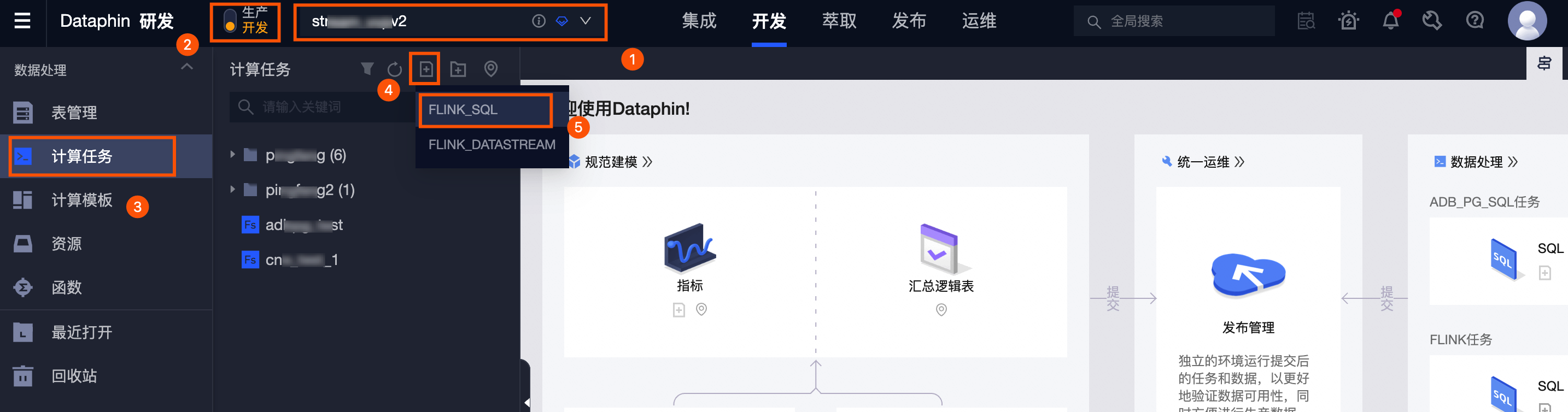 ①区域选择编码研发的项目空间,如果您选择了Dev-Prod模式的项目空间,则需要在区域②选择为
开发
。
①区域选择编码研发的项目空间,如果您选择了Dev-Prod模式的项目空间,则需要在区域②选择为
开发
。
-
在 新建Flink_SQL任务 对话框,配置参数后,单击 确定 。
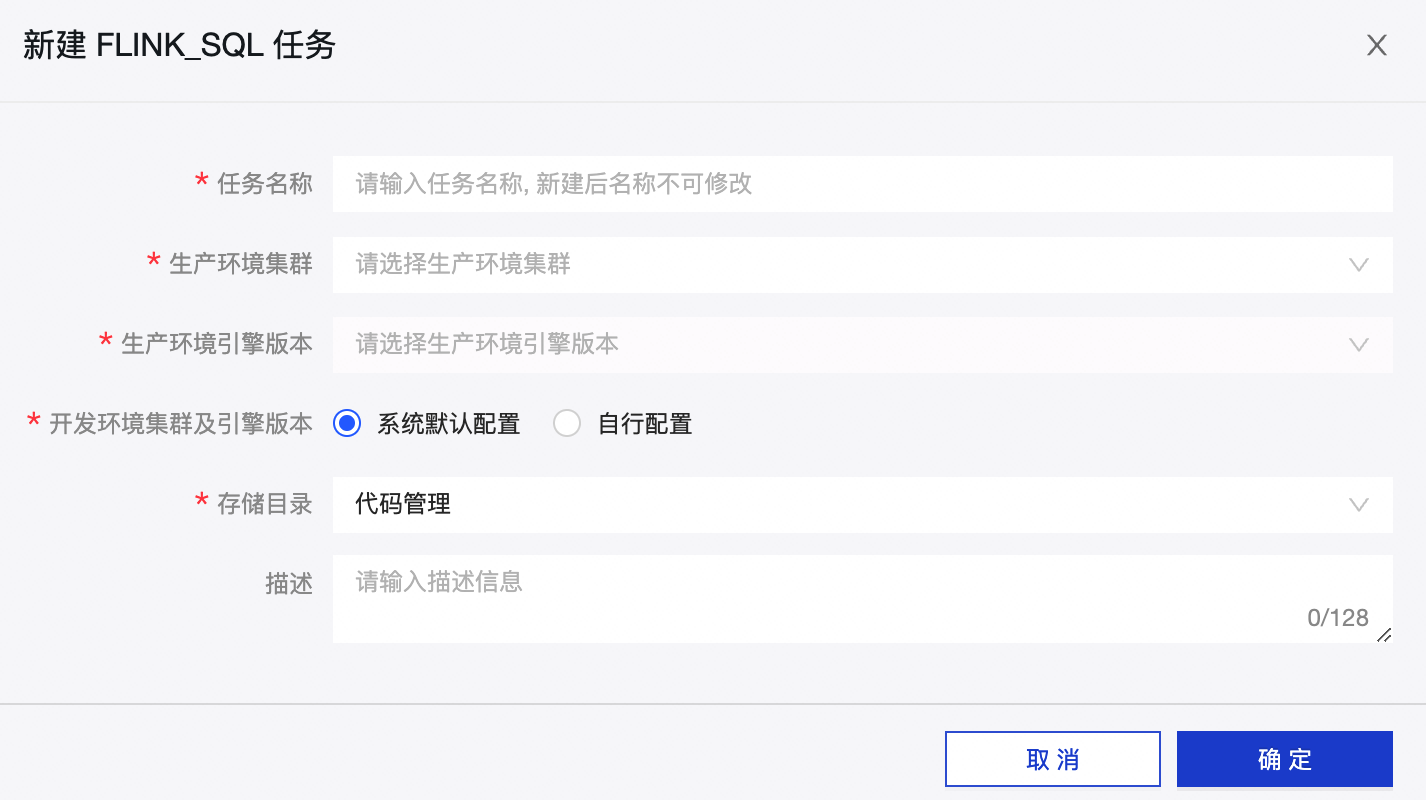
参数
说明
任务名称
名称的命名规则如下:
-
只能包含小写英文字母、数字、下划线(_)。
-
名称的长度范围为3~62个字符。
-
项目内的名称不支持重复。
-
名称仅支持以英文字母开头。
生产环境集群
选择Flink SQL任务所在集群。
生产环境引擎版本
选择生产环境下任务运行的引擎版本。
说明若您的项目空间为Basic模式,该配置项为 引擎版本 。
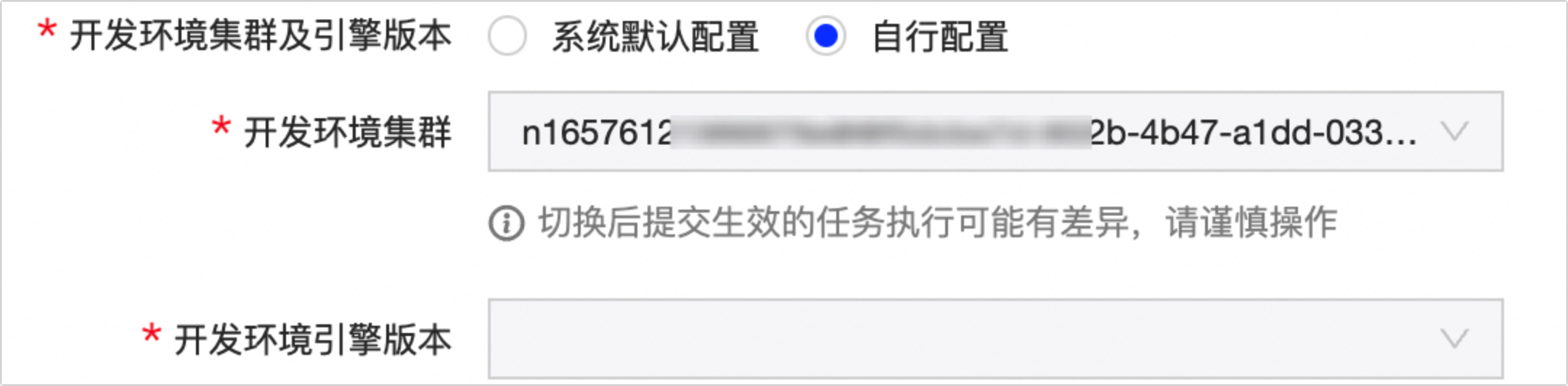
开发环境集群及引擎版本
支持选择 系统默认配置 或 自行配置 。
系统默认配置 :默认选择,使用与生产环境相同的环境集群与引擎版本。
自行配置 :您可自行选择开发环境任务运行的环境集群及引擎版本。
说明若您的项目空间为Basic模式,则无需配置该配置项。
存储目录
默认选择为代码管理,同时您也可以在 计算任务 页面创建目标文件夹后,选择该目标文件夹为Flink SQL任务的目录。
描述
填写对Flink SQL任务的简单描述。
-
步骤二:开发 与预编译 Flink SQL任务代码
-
在Flink SQL任务代码页面,编写任务的代码。
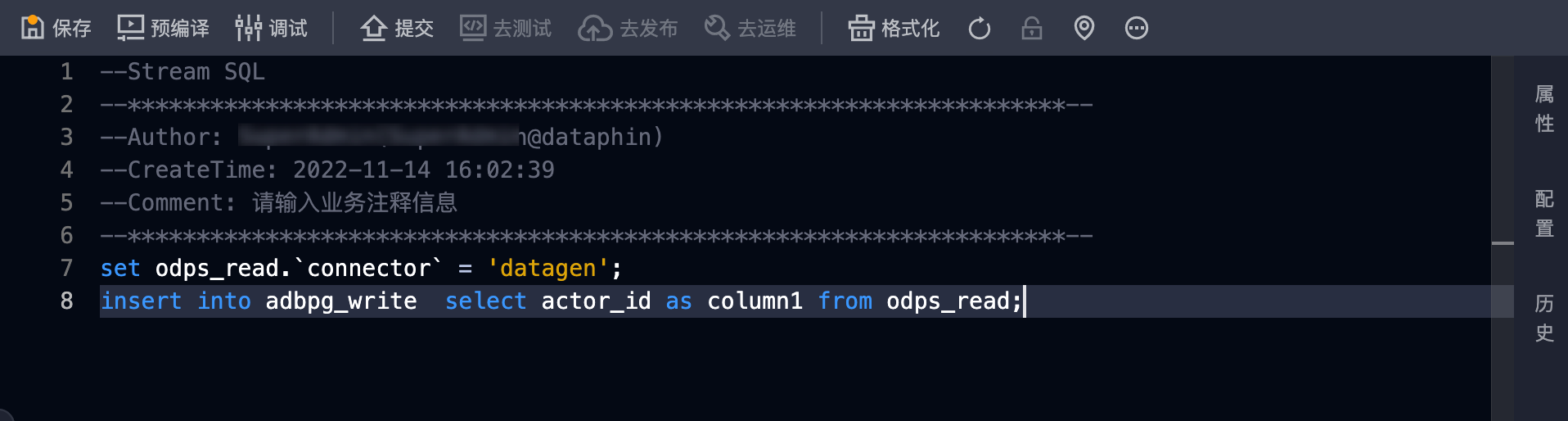 说明
说明您可以单击页面右上方的
 按钮,系统自动调整SQL代码格式。
按钮,系统自动调整SQL代码格式。
-
单击页面左上方的
 按钮,校验代码任务的语法及权限问题。
说明
按钮,校验代码任务的语法及权限问题。
说明-
预编译成功,在页面上方出现
 弹窗。
弹窗。
-
预编译失败,在页面上方出现
 弹窗,单击页面底部
Console
,查看预编译失败日志。
弹窗,单击页面底部
Console
,查看预编译失败日志。
-
步骤三: 调试 Flink SQL任务代码
Dataphin支持调试已开发的代码。单击页面右上方的
![]() 按钮,代码任务采样数据并进行本地调试,保障代码任务的正确性。
按钮,代码任务采样数据并进行本地调试,保障代码任务的正确性。
-
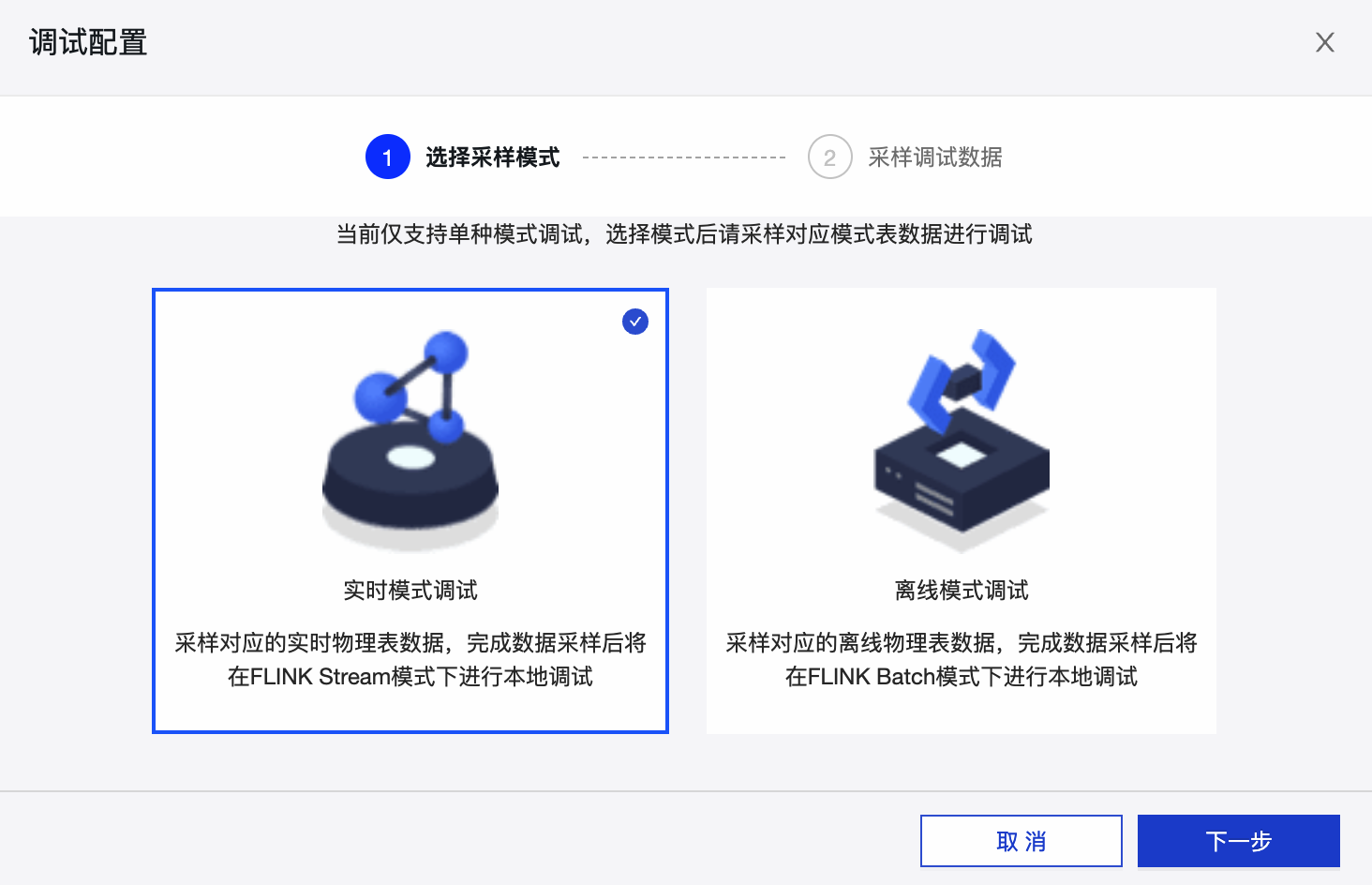
在 调试配置 对话框的 选择采样模式 页签中,选择调试的模式后,单击 下一步 。
-
在 采样调试数据 页签中,为元数据进行采样调试。
您可以通过自动抽样和上传数据的方式,为元数据进行采样调试。适用场景说明如下:
-
自动抽样
自动抽样到的数据是随机的,所以适用于对采集到的数据没有限制的场景。选择 自动抽样 后,需要配置 抽样条数 。仅支持DataHub,MaxCompute,TimeTunnel数据源进行自动抽样。
重要如果元数据表中没有数据,则自动抽样将采集不到数据。
调试任务时读取的开发表或生产元表,根据元表的配置决定,如何查看及配置元表的任务调试读取数据表,请参见 新建元表 。详细说明如下:
-
元表的 任务调试时可读取 参数选中 开发表 ,详细说明如下:
-
任务中使用的是
Project_Name_dev.元表名,则自动抽取开发元表。如果数据源无开发元表,则不支持 自动抽样 。 -
任务中使用的是
Project_Name.元表名,则自动抽取生产元表。如果您没有生产环境元表权限,则会报错。如何申请生产元表权限,请参见 申请表权限 。 -
任务中使用的是
${Project_Name}.元表名或元表名,则自动抽取开发元表。如果数据源无开发元表,则不支持 自动抽样 。
-
-
元表的 任务调试时可读取 参数选中 生产表 ,详细说明如下:
-
任务中使用的是
Project_Name_dev.元表名,则自动抽取开发元表。如果数据源无开发元表,则不支持 自动抽样 。 -
任务中使用的是
Project_Name.元表名,则自动抽取生产元表。 -
任务中使用的是
${Project_Name}.元表名或元表名,根据参数中已经设置替换${project_name},则调试读取的表使用参数中指定开发或生产项目确定使用生产元表还是开发元表;若未指定${project_name},则自动抽取生产元表。
-
-
-
上传本地数据
针对不支持的数据源或者自动抽样满足不了场景的构造或性能较差时元数据采集不到或数据抽样的逻辑比较严格,例如从100万条数据中抽取其中1条数据,这样采集效率就很低,可以选择手动上传本地数据。
上传本地数据前需要先下载样例,根据下载的样例编辑需要上传的数据,单击 上传 后,数据自动填充至 元数据采样 区域。

-
手动输入
适用于采集的数据比较少,或者需要修改已采集到的数据的场景。
-
-
完成所有数据表的元数据采样后,单击页面下方的 确定 。
-
在 Result 页面,查看 调试数据 、 中间结果 和 调试结果 。

步骤四:配置Flink SQL任务
完成开发及调试后,您需要为Flink SQL任务配置任务的资源、属性、依赖关系、任务参数信息。同时Dataphin实时计算支持流批一体任务,使用统一的流批计算引擎,在一份代码上可同时配置 流+批 的任务配置,基于同一份代码生成不同模式下的实例。开启批处理需在实时任务配置页面开启离线模式并进行资源、调度依赖等相关配置。各配置说明如下:
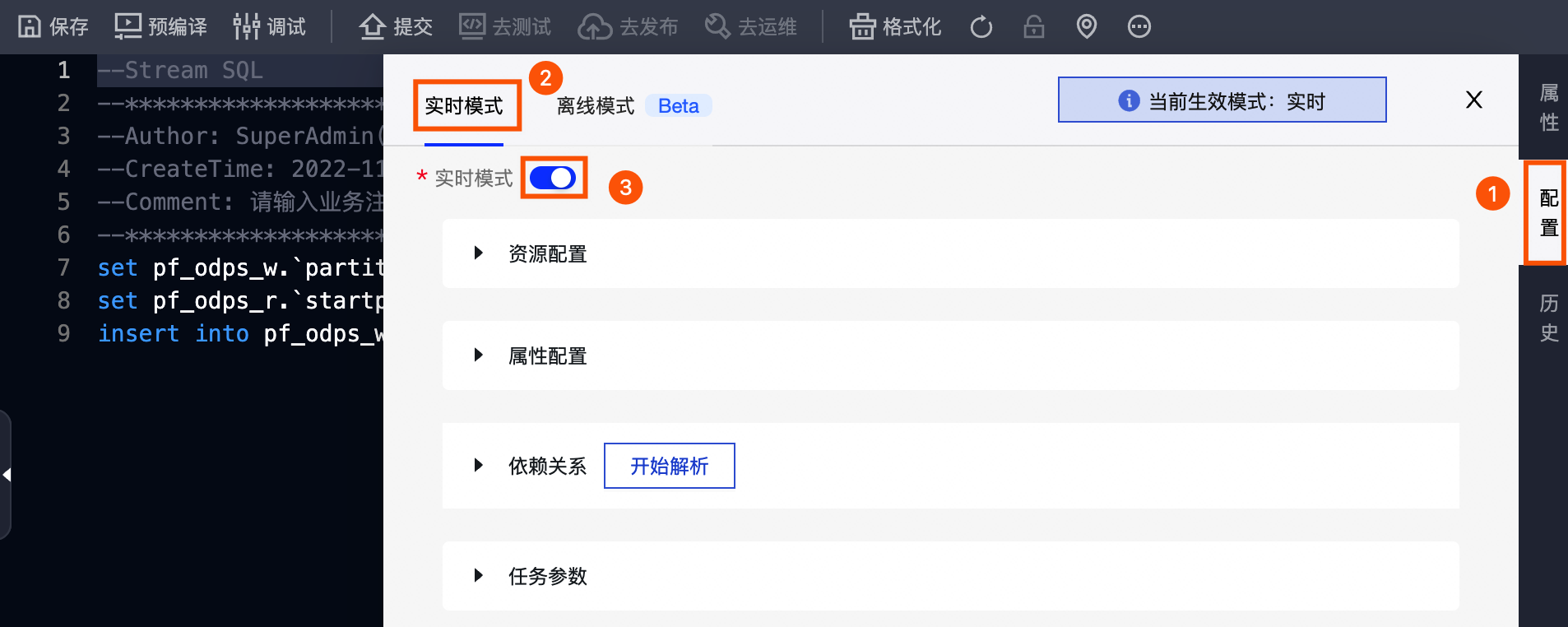
实时模式
按照下图操作指引 , 在 实时模式 页签下配置Flink SQ任务的实时模式参数。
-
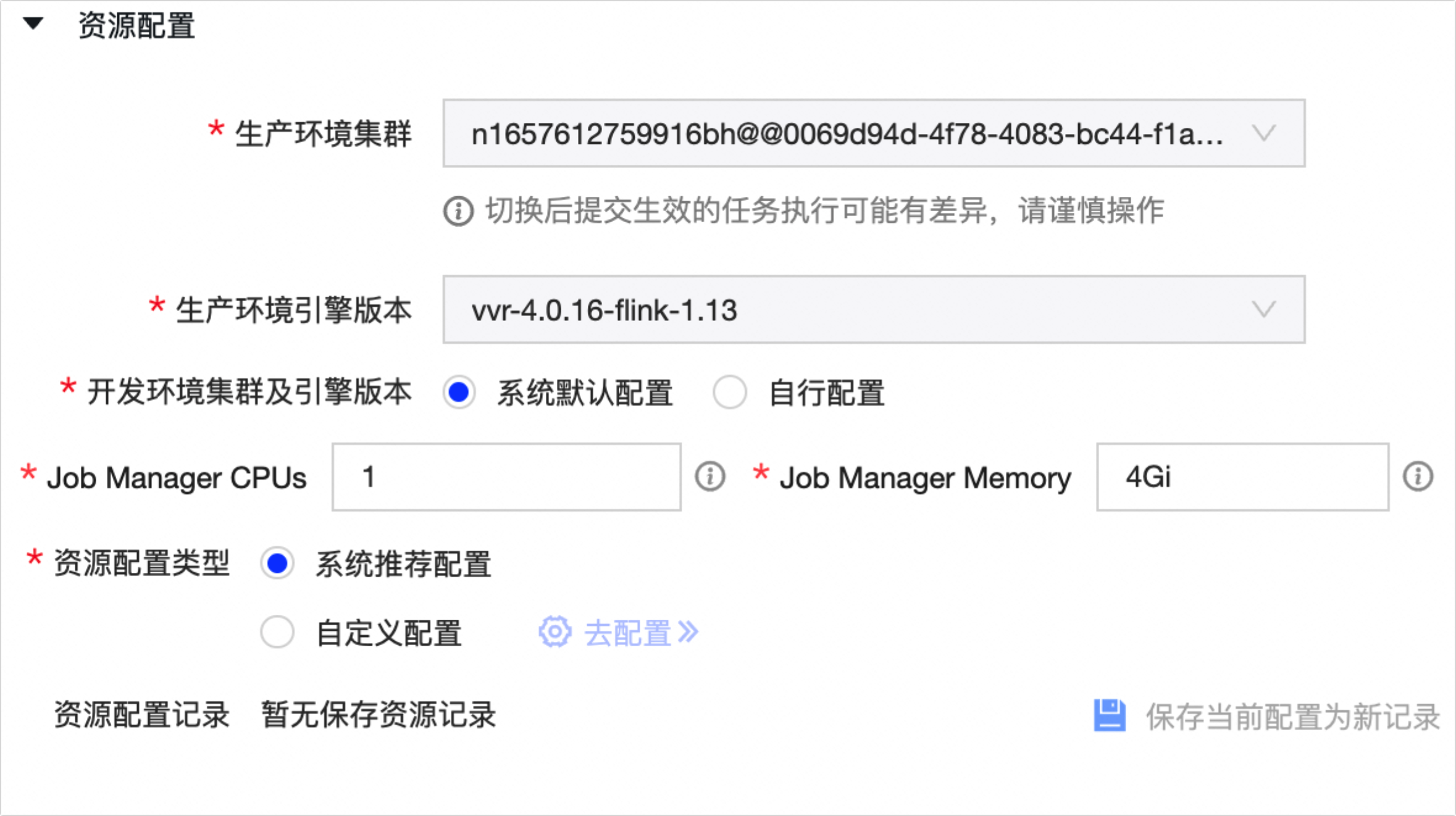
资源配置
参数
描述
生产环境集群
默认为创建Flink SQL任务时选择的生产环境集群。您可在此处切换集群。
重要集群切换后提交生效的任务执行可能有差异,请谨慎操作。
生产环境引擎版本
默认为创建Flink SQL任务时选择的生产环境引擎版本。您可在此处切换引擎版本。
开发环境集群及引擎版本
支持系统默认配置和自行配置。
-
系统默认配置 :默认选择,使用与生产环境相同的环境集群与引擎版本。
-
自行配置 :您可自行选择开发环境任务运行的环境集群及引擎版本。
 说明
说明若您的项目空间为Basic模式,则无需配置该配置项。
Job Manager CPUs
该任务在Flink集群的控制单元中所占用的CPU资源大小。默认为1,可填任意大于0的数,如1、10.5。
Job Manager CPUs
任务在Flink集群的控制单元中所占用的内存资源大小。默认为4Gi,建议使用Gi/Mi单位;可填数字(单位Byte),或填入包含以下内存单位(Gi/Mi)的数字,例如填写1024000、1024Mi、1.5Gi。
资源配置类型
-
系统推荐配置
即实时计算Flink配置细粒度资源的智能模式(BETA),智能模式为专家模式的升级版。在智能模式下,作业将启用专家模式的资源配置,同时开启AutoPilot自动调优功能。
在智能配置模式下,您无需配置相关资源,AutoPilot会自动为作业生成资源配置,并根据作业的运行情况帮您进行资源配置的调优,在确保作业处于健康的状态下,优化作业资源的使用。AutoPilot详情请参见 配置自动调优 。
-
自定义配置
即实时计算Flink配置细粒度资源的专家模式 (BETA),Flink全托管引入的全新的资源配置模式,支持对作业所使用的资源进行细粒度的资源控制,以满足作业吞吐的要求。
系统会自动根据您配置的资源需求,以Native K8s的模式运行作业,TM的规格和个数将会根据Slot的规格和作业并发度,由系统自动决定。更多关于配置细粒度资源的内容,请参见 配置细粒度资源 。
在Dataphin中自定义Flink SQL任务资源。具体操作,请参见 Ververica Flink实时任务资源自定义 。
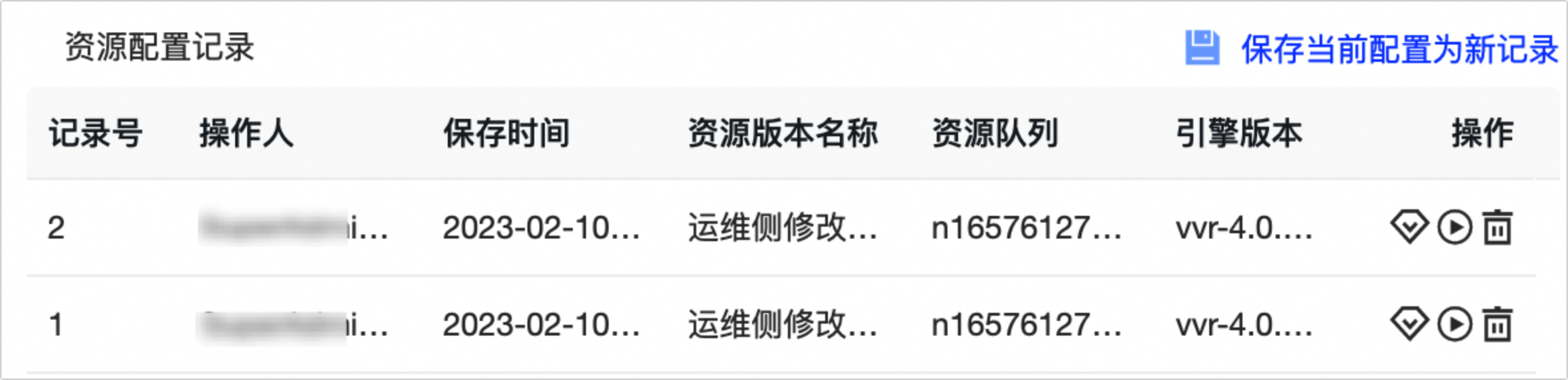
资源配置记录
资源配置 信息变更时,您可单击 保存当前配置为新纪录 。对于保存的资源配置记录信息您可进行 查看详情 、 启动 或 删 除 操作。
-
-
属性配 置

实时任务的时间参数为
stat_date,用于方式实时计算任务的运行时间的偏移,例如,您需要计算当天某个指标聚合值,为了防止时间偏移,则您需要设置state_date大于当天零点,过滤掉偏移的时间点。为了规避在 任务参数 处经常漏掉配置
stat_date,您只需要在实时任务配置的属性配置中新增stat_date的kv配置,其中Value是一个基于业务时间的表达式,同时您也可以配置多个时间参数,使用半角分号(;)分割。例如stat_date=${yyyyMMdd-1},则任务运行过程中的开始执行时间为${yyyyMMdd-1}。 -
依赖关系
实时模式下的依赖关系不实际产生调度依赖。配置依赖可帮助排查调试时快速了解数据的上下游任务。

参数
描述
自动解析
当节点的任务类型为SQL时,您可以单击 自动解析 ,系统会解析代码中的表,并查找到与该表名相同的输出名称。输出名称所在的节点作为当前节点的上游依赖。
如果代码中引用项目变量或不指定项目,则系统默认解析为生产项目名,以保证生成调度的稳定性。例如,开发项目名称为
onedata_dev:-
如果代码里指定
select * from s_order,则调度解析依赖为onedata.s_order。 -
如果代码里指定
select * from ${onedata}.s_order,则调度解析依赖为onedata.s_order。 -
如果代码里指定
select * from onedata.s_order,则调度解析依赖为onedata.s_order。 -
如果代码里指定
select * from onedata_dev.s_order,则调度解析依赖为onedata_dev.s_order。
上游依赖
通过执行如下操作,添加该节点任务调度时依赖的上游节点:
-
单击 手动添加上游 。
-
在 新建上游依赖 对话框中,您可以通过以下两种方式搜索依赖节点:
-
输入所依赖节点的输出名称的关键字进行搜索节点。
-
输入 virtual 搜索虚拟节点(每个租户或企业在初始化时都会有一个根节点)。
说明节点的输出名称是全局唯一的,且不区分大小写。
-
-
单击 确定新增 。
同时您还可以单击 操作 列下的
 图标,删除已添加的依赖节点。
图标,删除已添加的依赖节点。
当前节点
通过执行如下操作,设置当前节点的输出名称,根据需要您可以设置多个输出名称,供其他节点依赖使用:
-
单击 手动添加输出 。
-
在 新增当前节点输出 对话框中,填写输出名称。输出名称的命名规则请尽量统一,一般命名规则为
生成项目名.表名且不区分大小写,以标识本节点产出的表,同时其他节点更好地选择调度依赖关系。例如,开发项目名称为
onedata_dev,建议将输出名称设置为onedata.s_order。如果您将输出名称设置为onedata_dev.s_order,则仅限代码select * from onedata_dev.s_order能解析出上游依赖节点。 -
单击 确定新增 。
同时您还可以对当前节点已添加的输出名称执行如下操作:
-
单击 操作 列下的
图标,删除已添加的输出名称。
-
如果该节点已提交或已发布,且被任务所依赖(任务已提交),则单击 操作 列下的
 图标,查看下游节点。
图标,查看下游节点。
-
-
任务参数
 说明
说明若您项目中所有计算任务均需配置同一的任务参数,您可在新建项目时进行全局的统一配置。详情请参见创建项目。
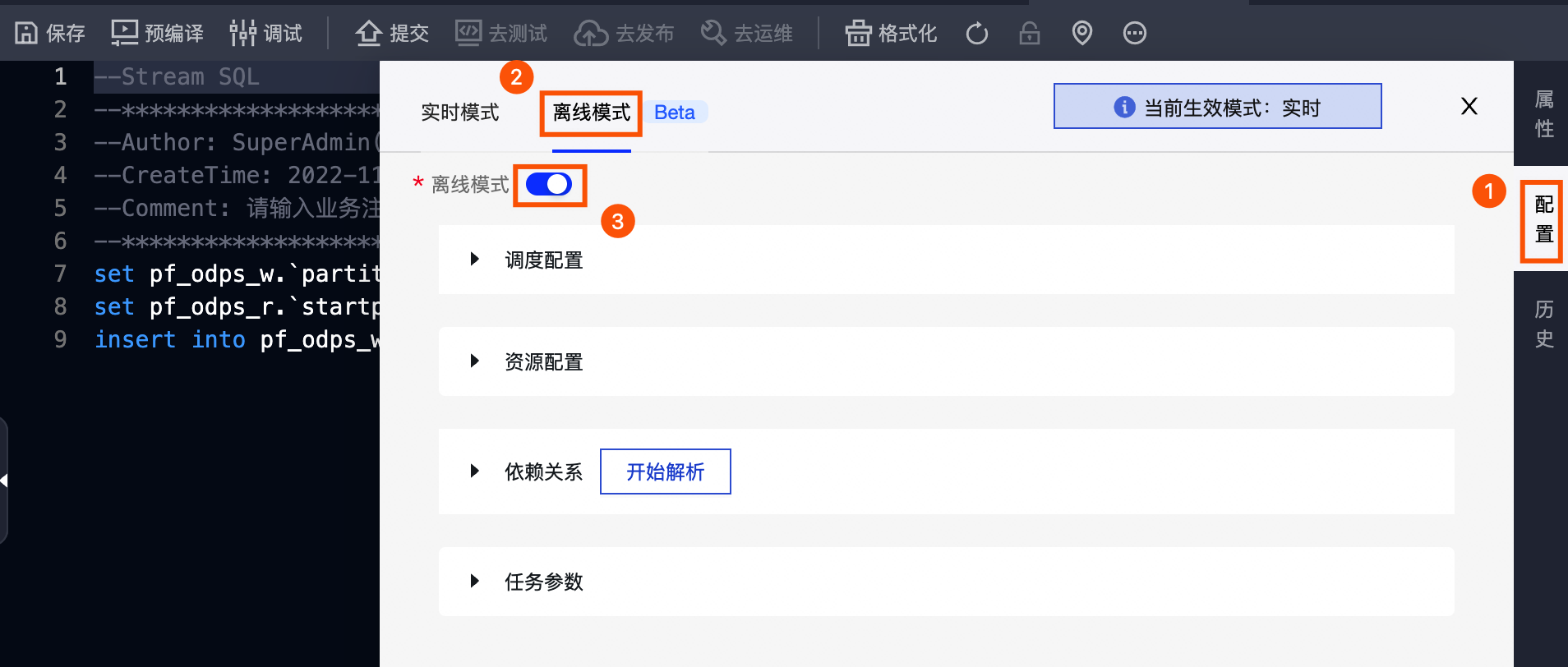
离线模式
按照下图操作指引,在 离线模式 页签下配置Flink SQL任务的离线模式参数。
-
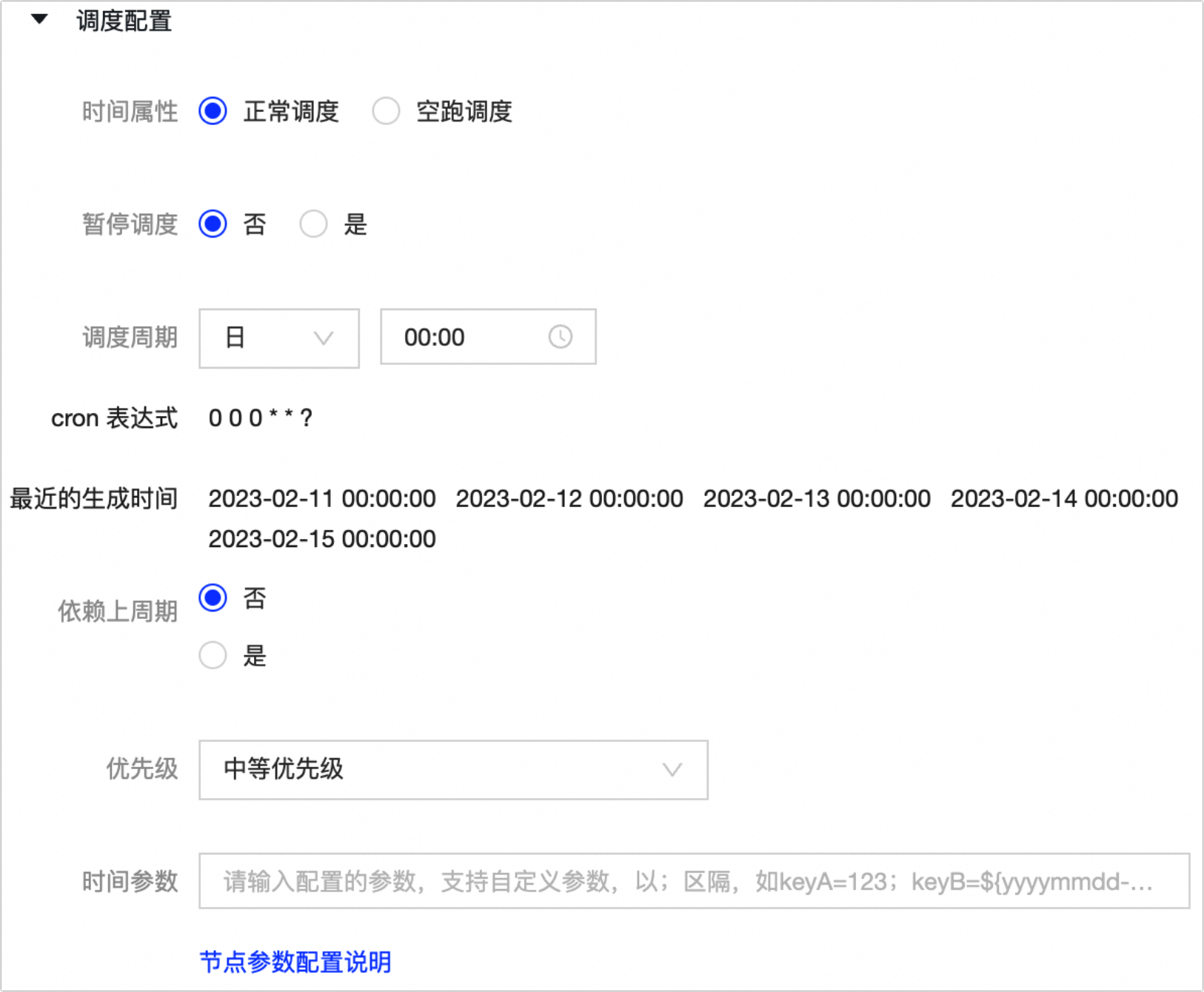
调度配 置
参数
描述
时间属性
选择 时间属性 。 时间属性 包括:
-
正常调度 :按照调度周期的时间配置调度,并正常执行,通常任务默认选中该项。
-
空跑调度 :按照调度周期的时间配置调度,但都是空跑执行,即一调度到该任务便直接返回成功,没有真正的执行任务。
暂停调度
暂停调度 选择 是 后,即可暂停该任务的调度,会按照下面的调度周期时间配置调度,但是一旦调度到该任务会直接返回失败,不会执行。通常用于某个任务暂时不用执行,但后面还会继续使用的场景。
调度周期
调度周期 可选择 日 、 周 、 月 、 小时 和 分钟 :
-
日 调度,即调度任务每天自动运行一次。新建周期任务时,系统默认的时间周期为每天0点运行一次。您可以根据需要,单击
 图标,指定运行的时间点。
图标,指定运行的时间点。
-
周 调度,即调度任务每周的特定几天,在特定时间点自动运行一次。您可以根据需要,单击
图标,指定运行的时间点。
如果您没有指定日期,为保证下游实例正常运行,系统会生成实例后直接设置为运行成功,而不会真正执行任何逻辑,也不会占用资源。
-
月 调度,即调度任务在每月的特定几天,在特定时间点自动运行一次。您可以根据需要,单击
图标,指定运行的时间点。
如果在没有被指定的日期时,为保证下游实例正常运行,系统会每天生成实例后直接设置为运行成功,而不会真正执行任何逻辑,也不会占用资源。
-
小时 调度,即每天指定的时间段内,调度任务按间隔时间数的时间间隔运行一次。或选择指定的时间点,调度系统会自动为任务生成实例并运行。您可以根据业务需求选中 时间段 或 时间点 :
-
如果您选中了 时间段 ,您可以单击 开始 或 结束 后的
图标,指定运行的开始和结束时间。同时您可以单击
间隔
后的
 图标,在下拉列表中选择间隔时间。
图标,在下拉列表中选择间隔时间。
-
如果您选中了 时间点 ,单击下拉列表框,在下拉列表中选择时间点。
例如,每天00:00~23:59的时间段内,每隔1小时会自动调度一次,因此调度系统会自动为任务生成实例并运行。
-
-
分钟 调度,即每天指定的时间段内,调度任务按间隔时间数的时间间隔运行一次。 您可以单击 开始 或 结束 后的
图标,指定运行的开始和结束时间。同时您可以单击
间隔
后的
图标,在下拉列表中选择间隔时间。
依赖上周期
根据业务场景选择本周期节点的运行,是否需要依赖上一周期本节点或其他节点的运行结果。
选择节点类型。系统支持选择 自定义 和 当前 。适用场景说明如下:
-
本周期节点是否运行取决于上一周期本节点是否正常产出数据,则需要选择 当前 。只有上一周期本节点运行成功,才会启动运行本节点。
-
代码任务没有用到某个节点的产出表,但业务上需要依赖该节点的上一周期是否正常产出数据,则需要选择依赖 自定义 节点。
优先级
优先级定义了同一时间同一批待调度任务的优先级。 优先级 包括:
-
最低优先级 。
-
低优先级 。
-
中等优先级 。
-
高优先级 。
-
最高优先级 。
时间参数
您可以对代码中所用参数的具体赋值。单击 节点参数配置说明 ,查看Dataphin调度系统的配置规则及支持配置的时间参数。
-
-
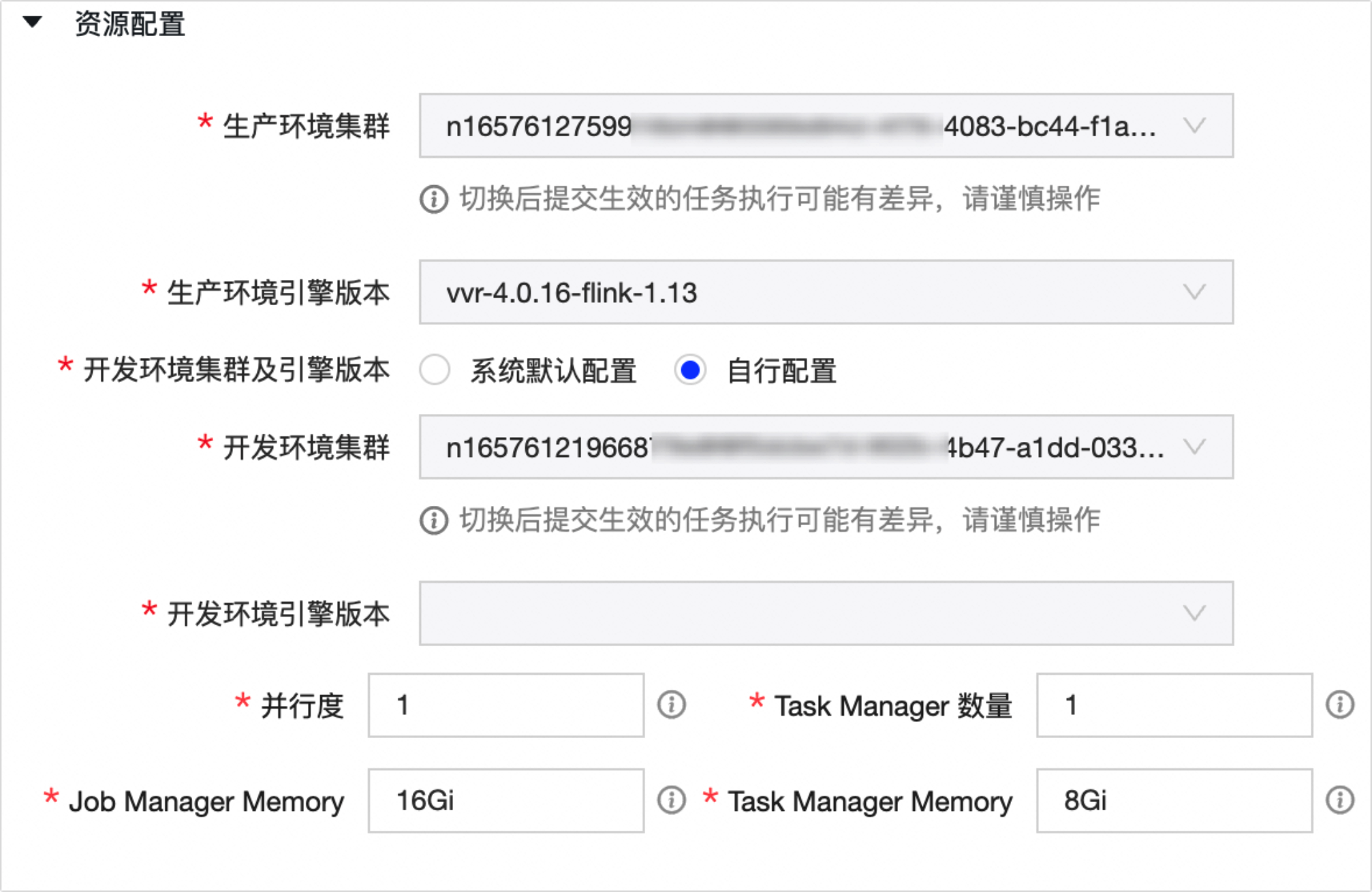
资源 配置
参数
描述
生产环境集群
默认为创建Flink SQL任务时选择的生产环境集群。您可在此处切换集群。
重要集群切换后提交生效的任务执行可能有差异,请谨慎操作。
生产环境引擎版本
默认为创建Flink SQL任务时选择的生产环境引擎版本。您可在此处切换引擎版本。
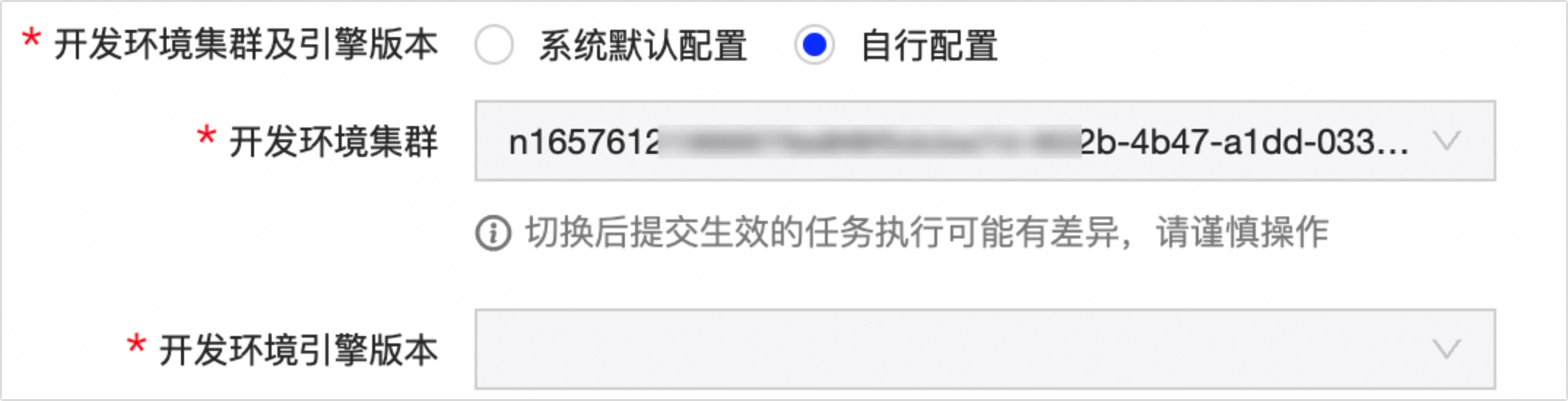
开发环境集群及引擎版本
支持系统默认配置和自行配置。
-
系统默认配置 :默认选择,使用与生产环境相同的环境集群与引擎版本。
-
自行配置 :您可自行选择开发环境任务运行的环境集群及引擎版本。
 说明
说明若您的项目空间为Basic模式,则无需配置该配置项。
并行度
配置任务运行的并行数。默认为1,可填任意大于0的整数, -1代表自动推断。
Task Manager数量
默认与并行度一致,可填任意大于0的整数。
Job Manager Memory
该任务在Flink集群的控制单元中所占用的内存资源大小。默认为1Gi,建议使用Gi/Mi/单位;可填数字(单位Byte),或填入包含以下内存单位(Gi/Mi)的数字。
Task Manager Memory
该任务在Flink集群的 Task Manager 中所占用的内存资源大小。默认为1Gi,建议使用Gi/Mi/单位;可填数字(单位Byte),或填入包含以下内存单位(Gi/Mi)的数字。
-
-
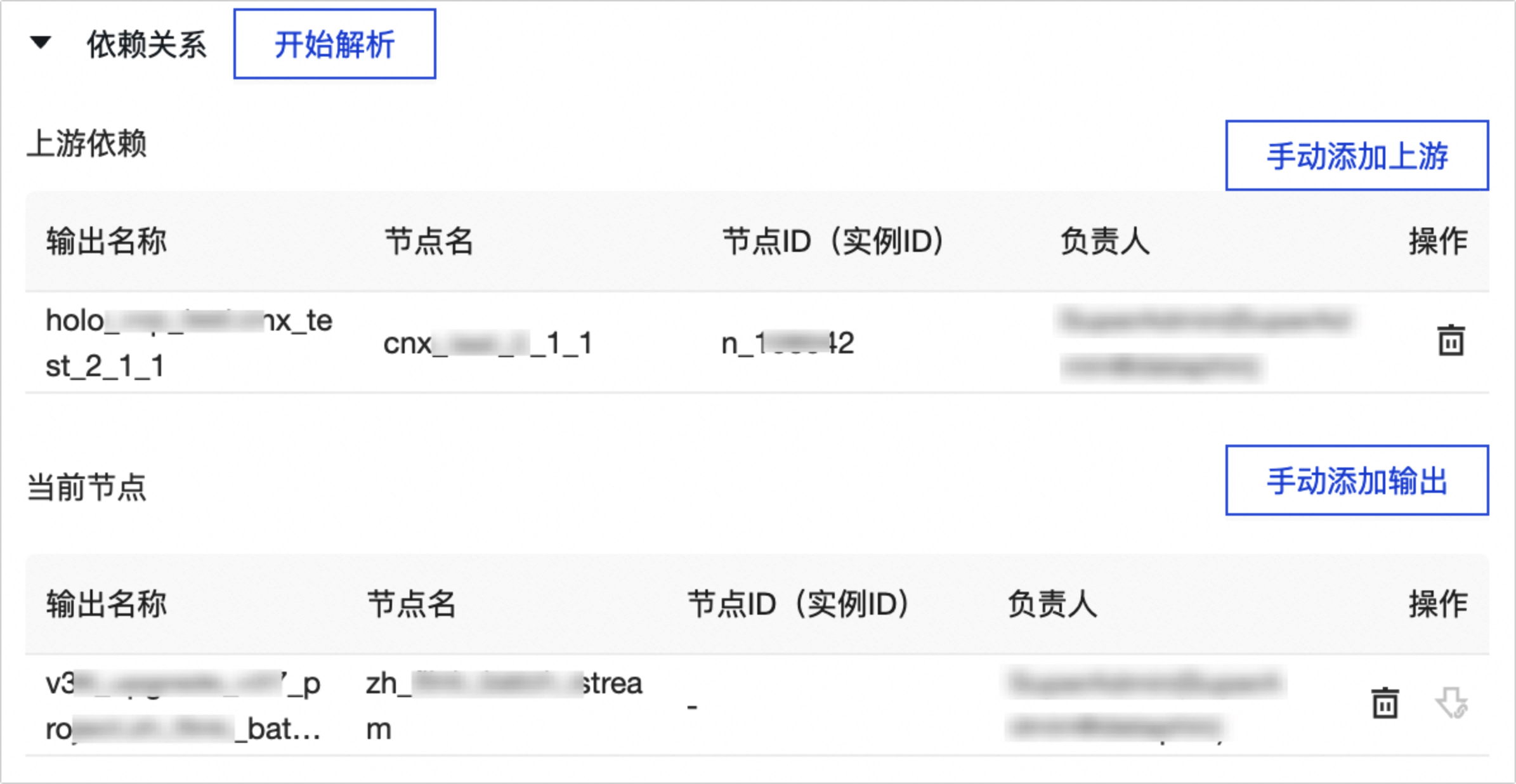
依赖 关 系
参数
描述
自动解析
当节点的任务类型为SQL时,您可以单击 自动解析 ,系统会解析代码中的表,并查找到与该表名相同的输出名称。输出名称所在的节点作为当前节点的上游依赖。
如果代码中引用项目变量或不指定项目,则系统默认解析为生产项目名,以保证生成调度的稳定性。例如,开发项目名称为
onedata_dev:-
如果代码里指定
select * from s_order,则调度解析依赖为onedata.s_order。 -
如果代码里指定
select * from ${onedata}.s_order,则调度解析依赖为onedata.s_order。 -
如果代码里指定
select * from onedata.s_order,则调度解析依赖为onedata.s_order。 -
如果代码里指定
select * from onedata_dev.s_order,则调度解析依赖为onedata_dev.s_order。
上游依赖
通过执行如下操作,添加该节点任务调度时依赖的上游节点:
-
单击 手动添加上游 。
-
在 新建上游依赖 对话框中,您可以通过以下两种方式搜索依赖节点:
-
输入所依赖节点的输出名称的关键字进行搜索节点。
-
输入 virtual 搜索虚拟节点(每个租户或企业在初始化时都会有一个根节点)。
说明节点的输出名称是全局唯一的,且不区分大小写。
-
-
单击 确定新增 。
同时您还可以单击 操作 列下的
图标,删除已添加的依赖节点。
当前节点
通过执行如下操作,设置当前节点的输出名称,根据需要您可以设置多个输出名称,供其他节点依赖使用:
-
单击 手动添加输出 。
-
在 新增当前节点输出 对话框中,填写输出名称。输出名称的命名规则请尽量统一,一般命名规则为
生成项目名.表名且不区分大小写,以标识本节点产出的表,同时其他节点更好地选择调度依赖关系。例如,开发项目名称为
onedata_dev,建议将输出名称设置为onedata.s_order。如果您将输出名称设置为onedata_dev.s_order,则仅限代码select * from onedata_dev.s_order能解析出上游依赖节点。 -
单击 确定新增 。
同时您还可以对当前节点已添加的输出名称执行如下操作:
-
单击 操作 列下的
图标,删除已添加的输出名称。
-
如果该节点已提交或已发布,且被任务所依赖(任务已提交),则单击 操作 列下的
图标,查看下游节点。
-
-
任务参数
 说明
说明若您项目中所有计算任务均需配置同一的任务参数,您可在新建项目时进行全局的统一配置。详情请参见创建项目。
步骤五:提交Flink SQL任务
按照下图操作指引,提交Flink SQL任务。
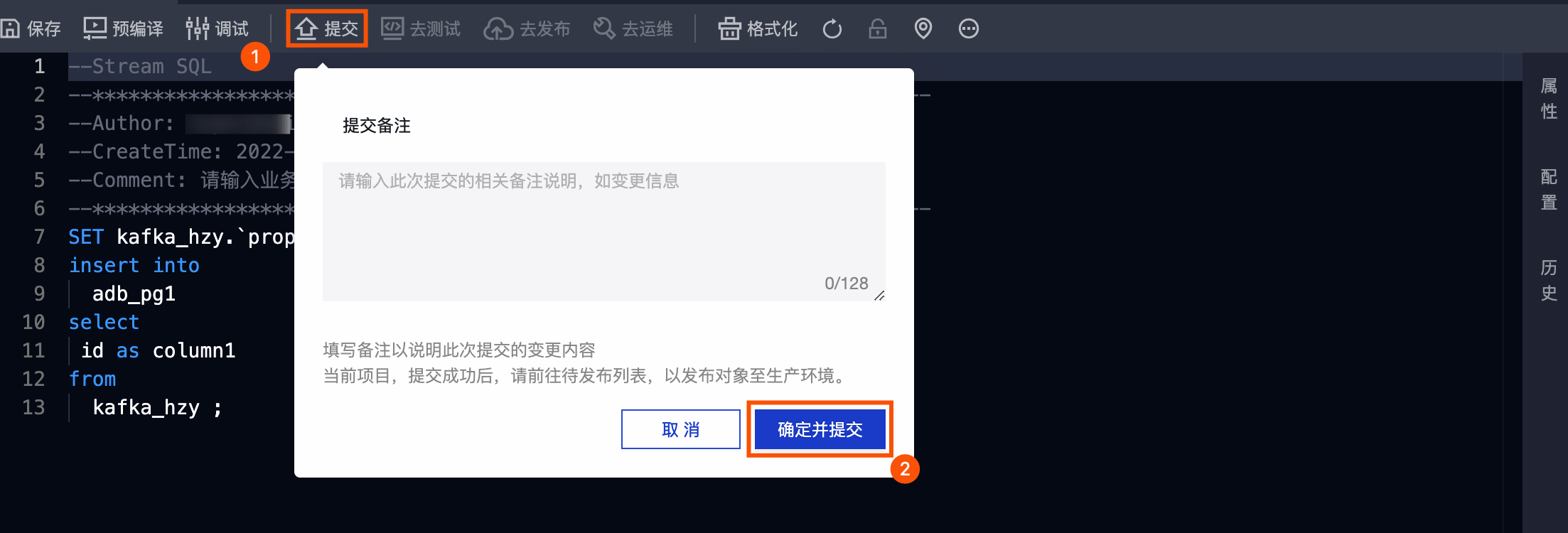
如果项目的模式为Dev-Prod,则您需要发布Flink SQL任务至生产环境。具体操作,请参见 发布任务 。
后续步骤
在运维中心查看并运维Flink SQL任务,保证任务的正常运行。具体操作,请参见 查看并管理实时任务 或 查看并管理实时实例 。