


python解析SQL的使用踩坑

以前用java的时候解析SQL用的是antlr,最近使用python,查了网上的资料大致有四种方法可以解析SQL。简单罗列一下。
1、sqlparse
2、正则匹配
3、sql_metadata
4、moz_sql_parser
我的需求是检查SQL中是否有分区表,且分区键是否有使用。
我们都知道一个分区表如果不使用分区键会全表扫描,对于数量千万乃至上亿的表而言,查询缓慢浪费查询资源,在生产中是不能容忍的。所以对于SQL是不专业人写的而言,容易出现此种情况,所以需要加上此种检查。
首先2就不说了,正则匹配的魔力虽然很强大,但是使用不太友好,极容易翻车。
1的代码我看了一眼过于复杂,我想要解析的是表名和带有表名的别名。然后看到3恰好有两个方法满足了我的需求。
import sql_metadata
# 获取用到的全部的表
sql_metadata.get_query_tables(sql)
# 得到所有用到别名的表名与对应的别名
sql_metadata.get_query_table_aliases(sql)本以为就此告一段落,然而找了几个sql测试发现获取别名问题很多。
很明显的,对于“select * from tableA a”这种就无法获取到别名a,只能是as加上才可以。这有点僵化。
那只剩4了,4的使用也很简单。一行代码就将sql拆解为了json对象。
from moz_sql_parser import parse
import json
tree = parse(sql)
print(json.dumps(tree))以sql 为例
select * from aTable a join bTable b on a.id = b.id where a.x = 1输出结果为
{"select": "*", "from": [{"value": "aTable", "name": "a"}, {"join": {"name": "b", "value": "bTable"}, "on": {"eq": [" a.id ", " b.id "]}}], "where": {"eq": ["a.x", 1]}}
可以看到
parse后的结果很准确,通过解析json可以获取到我们想要的结果,不过有点麻烦的是,这里join可能是inner join,left join等,所以要写很多if else判断。
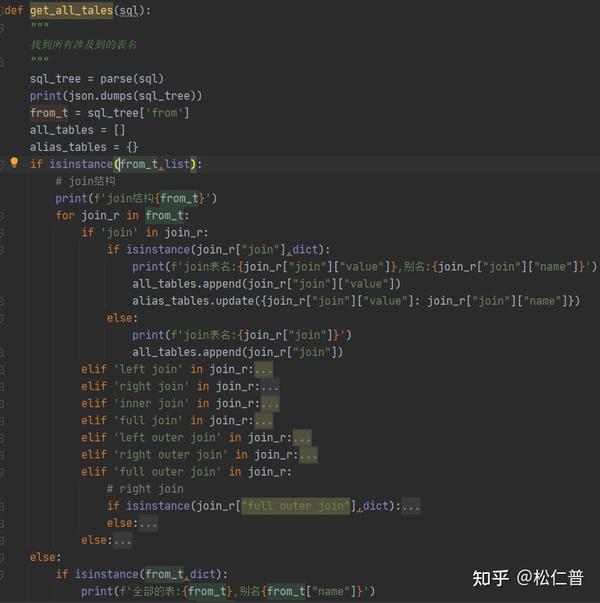

虽然麻烦了点,但是比起结果的正确性来说,这点还是值得的。
在sql进行解析前,还需要对sql进行注释的清理,否则各个parse模块都会报错。由于它们都没有提供清理注释的方法,所以只能自己通过正则写一个。
def clean_comment(sql):
# 删除多行注释
sql = re.sub(r"/\*[^*]*\*+(?:[^*/][^*]*\*+)*/", "", sql)