|
|
|


为什么像 Nginx、uwsgi、hbase、gunicorn等工具实现多个子进程监听同一个端口的?
关注者
19
被浏览
4,089
登录后你可以
不限量看优质回答
私信答主深度交流
精彩内容一键收藏

这个问题咋看有点基础,但是作者最后又提到了一些内核最新的细节。我来简短回答一下。
“一个进程 占用 了端口之后,其他进程就不能再使用这个端口了呀“ 这里“占用”有些模糊。socket的api里面对socket的接口和生命周期定义的很清楚,而没有一个用的是“占用”。来看看socket-

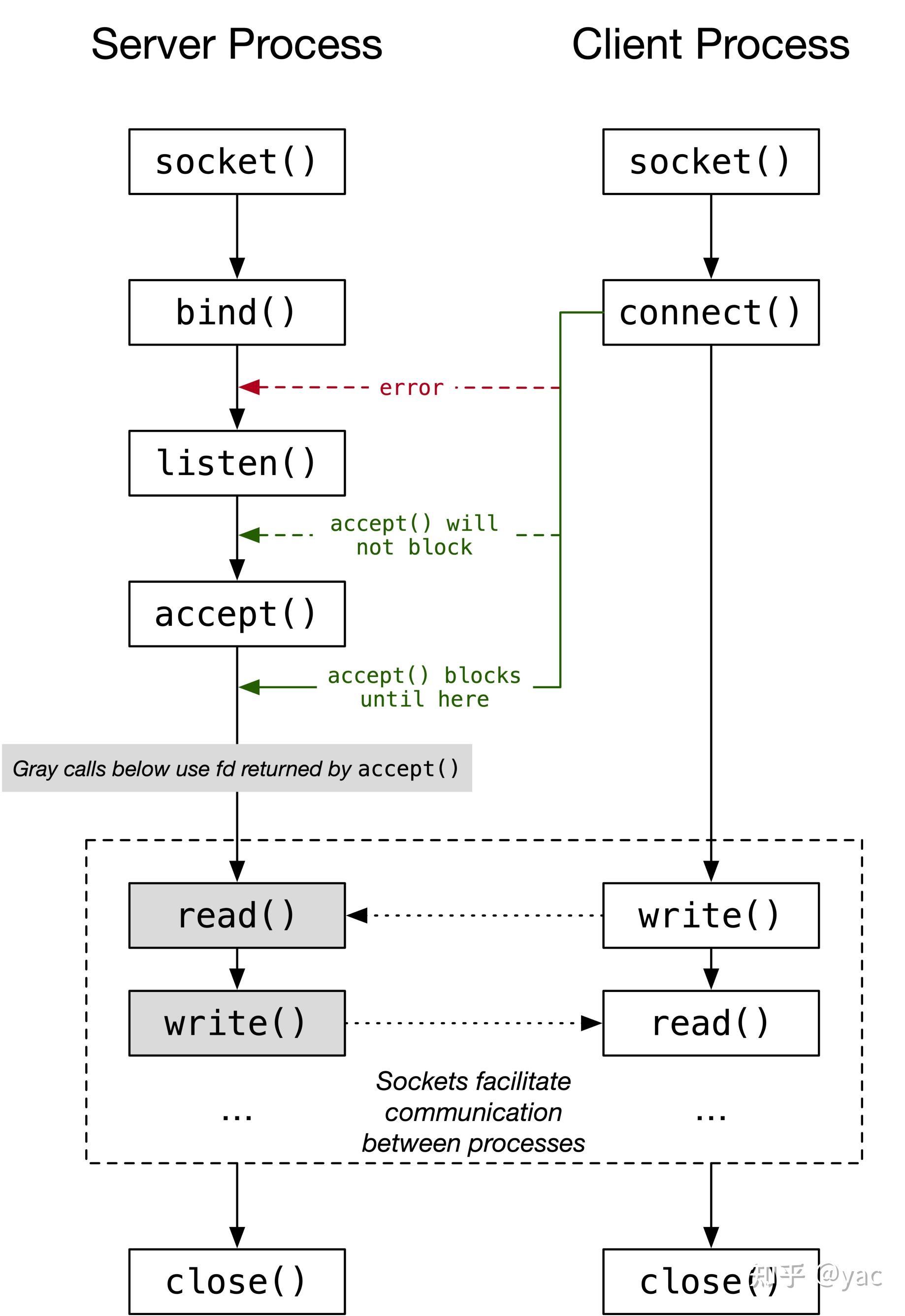
我们来看看server端。问题中还用到了“监听”这个词,所以我就假设题主的“占用”指的是bind+listen,这样一个socket就可以对外提供服务。
bind没什么好说的,就是绑定地址和端口二元组。那么直接来看看listen的api-
int listen(int sockfd, int backlog);当调用listen后这个socket就开始等待请求了。
当请求来了会发生什么:
int new_socket= accept(int sockfd, struct sockaddr *addr, socklen_t *addrlen);请求来了以后,之前的socket会创建一个新的 已连接 的socket,并返回新的句柄。而这个新的socket就是实际处理请求的工作socket。
到这里就明白了——
1)首先会有一个监听的socket等待请求;
2)当请求来了以后,会创建一个新的socket来处理请求,而这个新的socket可以在同一个进程/线程里,也可以在不同的进程/线程。
如果用netstat来观察,就会发现一般会有两个socket,一个状态是listen,一个状态是established。
所以答案是:并不是多个进程监听同一个端口,而是当有established socket的时候,会创建一个新的socket句柄(fd)来处理这个请求。这其实也是unix的设计哲学, 所有皆文件 ,通过文件句柄的创建和传递达到处理所有(包括socket)的目的。
----------------------
下面来说说fork和SO_REUSEPORT。
fork就是上面所说的方案,目前大部分服务端都是用的这种方案,当然为了资源使用和效率,一般不会用fork来创建新的进程,而是使用线程。监听的socket会分发请求给不同的工作线程,只有一个线程能处理请求。
这样的问题是什么呢?显而易见,监听socket会成为瓶颈,哪怕用各种无锁队列来优化,架构上的瓶颈始终不变。同时这种模式下请求的分配并不是公平的(其实这并不是一个bug而是个feature,是有意而为之以适应计算机架构),所以当用这种模式作为负载均衡的时候会产生不公平的问题,流量分布不均。
然后就有了SO_REUSEPORT,SO_REUSEPORT的理念就是在内核中多个进程/线程可以监听同一个端口,当socket调用recv()的时候,内核会公平的分配请求到不同的执行socket。当然SO_REUSEPORT也会有其问题,1)因为多个连接socket可以监听一个端口,那么会有端口劫持问题 2)当有端口变化时,可能会有连接丢失的问题。目前这个问题还没有得到解决,社区还在进行改进。
最后总结一下:
1)工作进程/线程是目前的主流做法,几乎所有web服务器都这么实现。fork只是其中一种实现,一般都用线程,本质上还是socket的accept。
2)SO_REUSEPORT比较新,不是所有的系统版本都支持,同时本身还在迭代中,自身还有一些问题;但是针对一些特定场景,比如DNS或者负载均衡,确实会有性能提升。
有哪些框架实现了呢?别的不知道,nginx1.9.1以后在特定的系统版本下可以开启SO_REUSEPORT。其他的就看看最新的文档喽。
以上。