

体系结构讨论-数据级并行(三)GPU

数据级并行的最后一个内容是GPU


GPU的核心是:
1.异构执行模型,CPU是host,GPU是设备。
2.GPU能够使用类C的编程语言进行开发,比如NVIDIA的cuda
3.GPU所有的并行形式是统一的,比如CUDA线程。
4.编程模型时SIMT,单指令多线程。


GPU中一个线程和每个数据元素相关,多个线程组成为一个线程块(thread block),多个线程块组成为一个网格grid。GPU的硬件处理线程管理,而不是应用或操作系统。


下面看一下NVIDIA的GPU架构
它与向量机相似的地方是:
1.对于数据级并行的问题表现良好
2.支持scatter-gather传输。
3.有屏蔽寄存器
4.有很大的寄存器文件。
不同的地方是GPU中没有标量处理器,使用多线程技术来隐藏访存延迟,有很多的功能部件,而不是像向量处理器那样实现了少量的深度流水线部件。
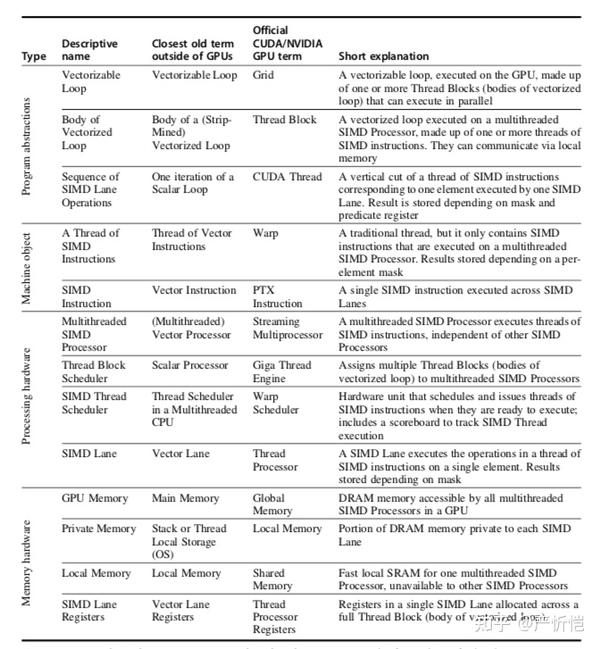
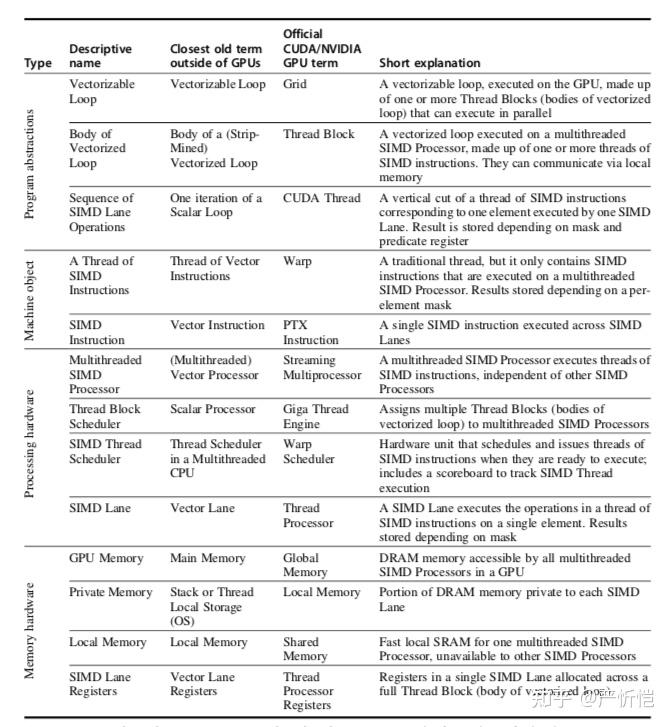
上表是GPU的一些概念和解释以及和最接近GPU之外的术语的对比。
比如最基础的概念GPU的grid,本质对应是向量化循环,Grid包含的线程块对应着向量化循环体;CUDA的线程对应的是一个SIMD lane的操作序列。
warp可以描述为一个SIMD指令线程,也对应着向量机中的向量指令线程,相比于传统线程,warp只包含了SIMD指令。GPU中的PTX指令本质是SIMD指令,也对应着向量机中的向量指令。
流多处理器(streaming multiprocessor,简称SM)本质是多线程SIMD处理器;Giga thread engine本质是线程块的调度器,也对应着向量机中的标量处理器,负责一些将线程块分配到流多处理器上执行。warp调度器本质上是SIMD线程调度器,对应多线程CPU中的线程调度器,负责调度和发射SIMD指令线程(还包括计分板)。线程处理器本质上就是SIMD lane,也对应着向量机的向量Lane。
存储方面,GPU的全局memory相当于main memory,Local memory相当于每个SIMD lane的私有memory,而GPU中的共享memory是每个多线程SIMD处理器私有的,不与其他多线程SIMD处理器共享;线程处理器寄存器对应与SIMD lane寄存器或向量lane寄存器,是一个SIMD lane拥有的。


一个Grid就是运行在GPU上的代码,它由线程块集合组成。线程块将其分解为可管理的大小,比如每个线程块包含512个线程。SIMD指令一拍执行32个元素,因此Grid的大小就是512/32=16个线程块。
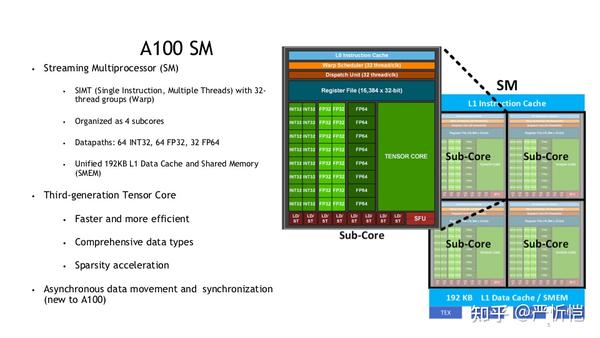
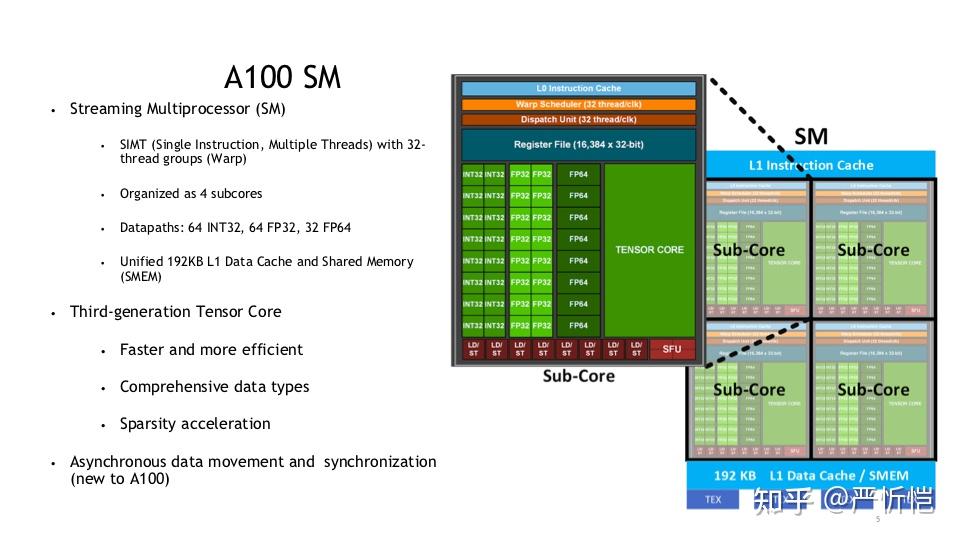
比如NVIDIA最新的A100GPU中,包含了108个SM,每个SM由四个sub-core组成,每个sub-core包含了16个cuda core(单精度浮点+INT32)、8个双精度浮点和1个tensor core,共6192个CUDA core,3456个双精度core和432个tensor core。


在进一步看GPU的术语:
每个线程的寄存器上限是64;一个warp包含了32个线程,映射到16个物理lane上执行;
一个SM上可以最多调度执行32个warp:其中每个warp都有自己的PC,warp调度器(线程调度器)使用计分板来分派warp;同时warp之间没有数据依赖;通过将warp分派到流水线处理来隐藏访存延迟。线程块调度器(giga engine)调度线程块在SM上执行。每个SM包含32条SIMD lane。


上图就是Grid-Thread block-Thread三级的数据工作分配示意图,是一个软件概念,实现了一个矩阵-向量乘。每个向量是8192个元素。每个SIMD thread(warp)执行32个元素计算,每个Thread block包含16个SIMD Thread,完成512个元素计算,Grid包含16个Thread block,完成整个8192个元素计算。Thread block调度器将16个线程块分配到不同的SM上执行,只有一个Thread block内的SIMD线程可以通过local memory进行通信。
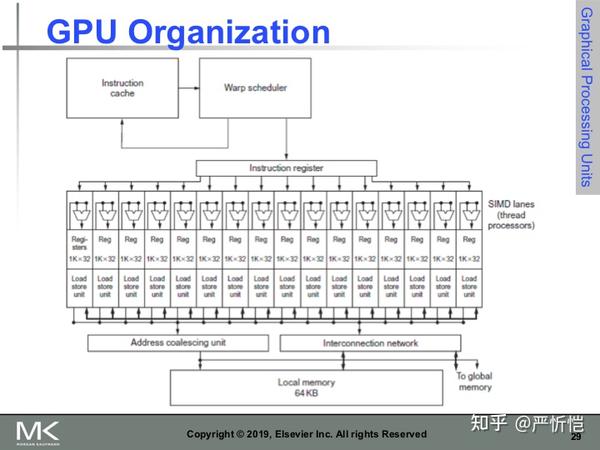
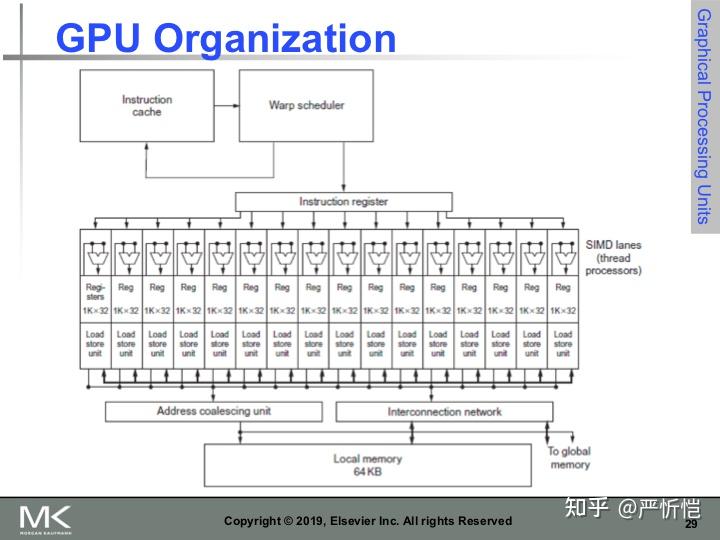
上图是GPU的SM组织形式图,可以直观看到SM中一个warp调度器将线程分配到16条SIMD lane上,一个SM中可能含有多个线程块。每个lane包含了1024个32位的寄存器,warp调度器支持32条独立的SIMD线程指令,可以记录32条PC。同一个线程块包含的warp可以通过local memory来通信。

调度程序选择一个准备好的SIMD指令线程,并向执行该SIMD线程的所有SIMD Lane同步发出指令。由于SIMD指令的线程是独立的,调度程序每次都可以选择不同的SIMD线程。


最重要的是指令集架构,NVIDIA使用的是PTX指令,指令格式如上所示,opcode.type d,a,b,c,最多支持3操作数。使用虚拟寄存器。
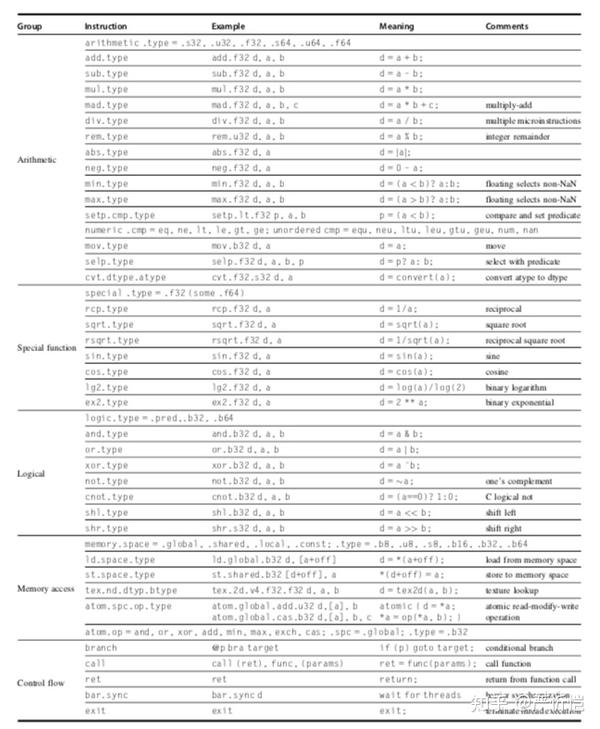
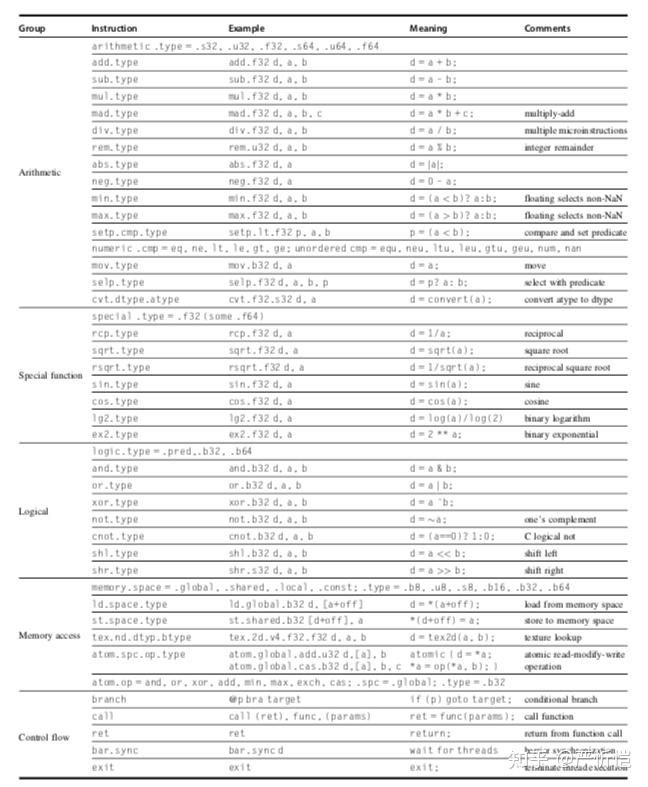
以上是PTX指令集包含的指令列表除了大部分运算和逻辑指令外,还有访存指令和控制流指令。


GPU的条件分支指令方式和向量结构类似,采用内部mask寄存器来表示。
除了显式谓词寄存器和内部mask寄存器外,GPU分支硬件还使用分支同步栈和指令标记来管理何时一个分支分叉到多个执行路径以及何时路径收敛。
在GPU硬件指令级别,控制流指令管理分支同步栈,包括分支、跳转、跳转索引、调用索引、调用索引、返回、退出,以及特殊指令。GPU硬件为每个SIMD线程提供自己的栈;栈条目包含一个标识符令牌(identifier token)、一个目标指令地址和一个目标线程有效掩码(thread-active mask)。GPU特殊指令可以为SIMD线程压栈条目,也有特殊指令和指令标记可以出栈条目或将栈展开到指定条目,并使用目标线程有效掩码转移到目标指令地址。
一个更复杂的控制流通常会导致谓词和GPU分支指令的混合,这些指令和标记使用分支同步栈来压栈,当一些lane会分支到目标地址,而另一些则失败。当这种情况发生时,分支就会出现分叉。当SIMD Lane执行同步标记或收敛时,也会使用这种混合,该标记弹出堆栈条目,并使栈条目中的线程有效掩码分支到栈条目地址。
此外GPU硬件指令也有单独的每个Lane的谓词(启用/禁用),为每个线程Lane指定一个1位谓词寄存器,具体由程序员描述。


NVIDIA 的GPU存储架构如下:每个SIMD lane都有自己的私有DRAM,包括了栈帧、溢出寄存器和私有变量;每个SM有自己的local memory,SM中的属于同一个线程块的SIMD lanes可以共享local memory。SM之间共享的memory是GPU memory,host(CPU)可以读写GPU memory,MMIO的方式。
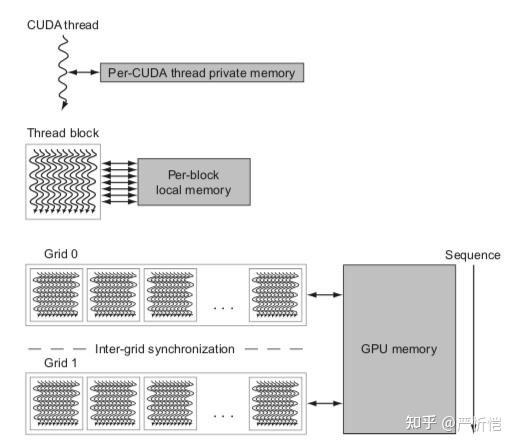
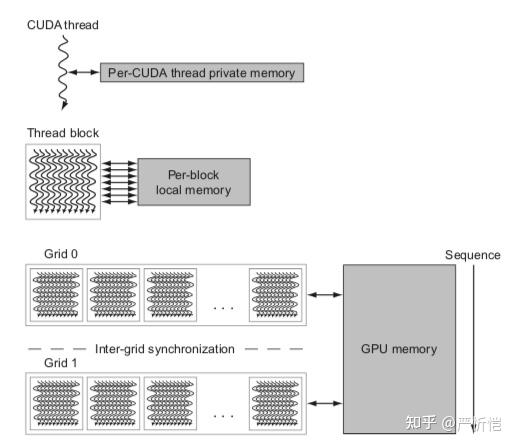
上图可以看出三级存储架构,CUDA thread的私有memory,一个线程块内线程共享的local memory,多个grid之间共享GPU memory。


教材中给出了Pascal架构的创新,虽然现在NVIDIA的GPU已经发展到最新架构,不过来看一眼当时的架构创新也很有意义。Pascal架构的每个SM包含了两个或四个线程调度器,两个指令分派部件。SM中包含了16个SIMD Lane(应该是64个),SIMD宽度为32,chime为2拍(完成一个convoy),还包含16个load-store部件和4(应该是16)个特殊函数部件。
支持快速单精度、双精度和半精度三种浮点类型。现在A100还支持专门用于深度学习的TF32、BF16等等。
Pascal还是用了HBM2和NVLink来增强访存能力;支持统一的虚拟内存和分页。




最后比较一下向量结构RV64V和GPU,首先两者结构很相似,多SM和多向量处理器都属于MIMD。
对于寄存器来说,RV64V的寄存器文件保存整个向量而GPU将它的向量放在各SIMD lane的寄存器中。
GPU的寄存器数量要远大于RV64V(8K>1024);
GPU的SM的chime要比RV64V的要短,虽然SIMD宽度都是32;
GPU的向量化循环是grid,GPU的所有load都是gather,所有store都是scatter。

上表给出了GPU和向量架构的相同概念的不同实现。
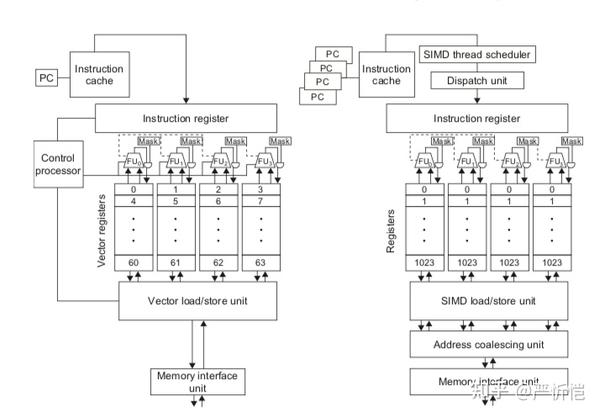
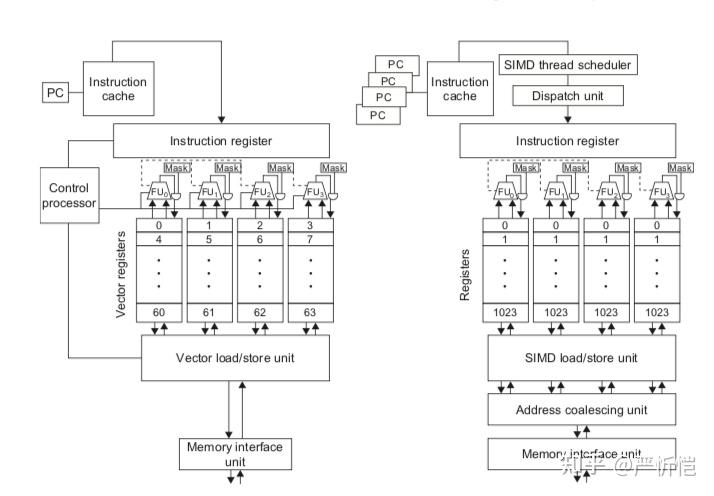
上图给出了向量lane数量为4的向量结构和SIMD lane数量为4的GPU的对比,向量架构使用控制核心而GPU使用调度器+分派模块,GPU的寄存器数量要远大于向量架构;GPU中由于是多线程,PC数量也是多份。


再比较一下SIMD架构和GPU:
GPU的SIMD lane数量更多,并且支持硬件多线程;
两者的地址都是64位的,不过GPU的memory更小;
最后SIMD不支持gather-scatter。


上表给出了SIMD多核架构和GPU的相关对比,SIMD多核架构虽然SIMD处理器数量和lane的数量少,但是cache大小和内存大小都是绝对占优,通用性更好。
