


python与统计学之:正态分布

微信公众号: Computational Biology
关注生物信息学和计算表观遗传学。问题或建议,请公众号留言。
本系列文章是分享和总结各种统计学知识,以及在Python中如何实现各种统计学分布和假设检验。正态分布是很常用的一种分布,这篇文章给大家 总结如何用python实现各种正态分布相关的统计学过程 。
1.生成正态分布随机数
from scipy import stats
import matplotlib.pylab as plt
import numpy as np
%matplotlib inline
#生成均值为0,标准差为1:N(μ,σ2) = N(0,1)的正态分布的20个随机变量
x = stats.norm.rvs(loc=0, scale=1, size=20)
print(x)
[ 0.7407143 -0.52992724 -0.04358298 -1.04828081 1.67040104 0.09387087
0.67453957 1.03977423 -0.04200286 1.22136893 -1.41947777 0.32254304
-1.47136 -0.25273308 -0.09072196 0.55442038 -0.51334943 -0.75311927
-0.43853489 0.01555674]2.正态分布概率密度函数(pdf: probability density function)
f(x)=\frac{1}{\sqrt{2\pi}\sigma}e^\frac{(x-\mu)^2}{2\sigma^2}\text{, $\mu$是平均值, $\sigma$是标准差}
\text{当$\mu$=0, $\sigma$=1时} f(x)=\frac{1}{\sqrt{2\pi}}e^\frac{x^2}{2}
#创建标准正太分布N(0,1)
norm = stats.norm(loc=0,scale=1)
x=np.arange(-10, 10, 0.01)
#对于每个x,生成标准正态分布的概率密度y
y=norm.pdf(x)
plt.figure(facecolor='lightblue')
plt.plot(x,y,color='orangered')
ax=plt.gca()
ax.set_facecolor("yellowgreen")
ax.set_title("PDF")
plt.show()
3.累积分布函数(Cumulative distribution function)
累积分布函数cdf是 概率密度函数曲线 中 左边的面积 ,比如:上图标准正态分布中,当x=0时,左边区域的面积为0.5,也就是x=0对应的累积分布函数的y值应该是0.5;当x接近无穷小时,y接近0,当x接近无穷大时,y接近1(如下图所示)。
print(stats.norm.cdf(x=0, loc=0, scale=1)) #新生成一个标准正态分布并打印出x=0时的累积分布函数y的值
# 0.5
#创建标准正太分布N(0,1)
norm = stats.norm(loc=0,scale=1)
x=np.arange(-10, 10, 0.01)
#对于每个x,生成标准正态分布的概率密度y
y=norm.cdf(x)
plt.figure(facecolor='gold')
plt.plot(x,y,color='orangered')
ax=plt.gca()
ax.set_facecolor("yellowgreen")
ax.set_title("CDF")
plt.show()
0.5
4.百分点函数(Percent point function)
PPF = inverse of cdf —> percentiles; 也就是累积分布函数的 逆函数 ; 例如,当累计分布函数y=0时,x应该是无穷小,当累计分布函数y=1时,x应该是无穷小;当y=0.5时,x应该是0。
a = stats.norm.ppf(q=0, loc=0, scale=1) # = -inf
b = stats.norm.ppf(q=1, loc=0, scale=1) # = +inf
c = stats.norm.ppf(q=0.5, loc=0, scale=1) # = 0
print(a,b,c)
-inf inf 0.05.正态分布检验
检验一组数据是否服从正态分布
#先构造一组随机数据
df = pd.DataFrame(np.random.randn(1000)+10,columns=['A'])
print(df)
fig, ax = plt.subplots(1, 1,facecolor='yellowgreen')
df.A.hist(bins=30,ax=ax,alpha=0.5,color='red')
df.A.plot(kind='kde',ax=ax,secondary_y=True,color='red')
ax.set_facecolor("wheat")
plt.grid()
plt.show()
0 9.893950
1 11.486991
2 10.895578
3 10.012024
4 11.286171
.. ...
995 10.717863
996 11.282250
997 11.133652
998 10.995692
999 8.228661
[1000 rows x 1 columns]
接下来检验我们构造的数据df.A是否是正态分布
5.1.KS检验

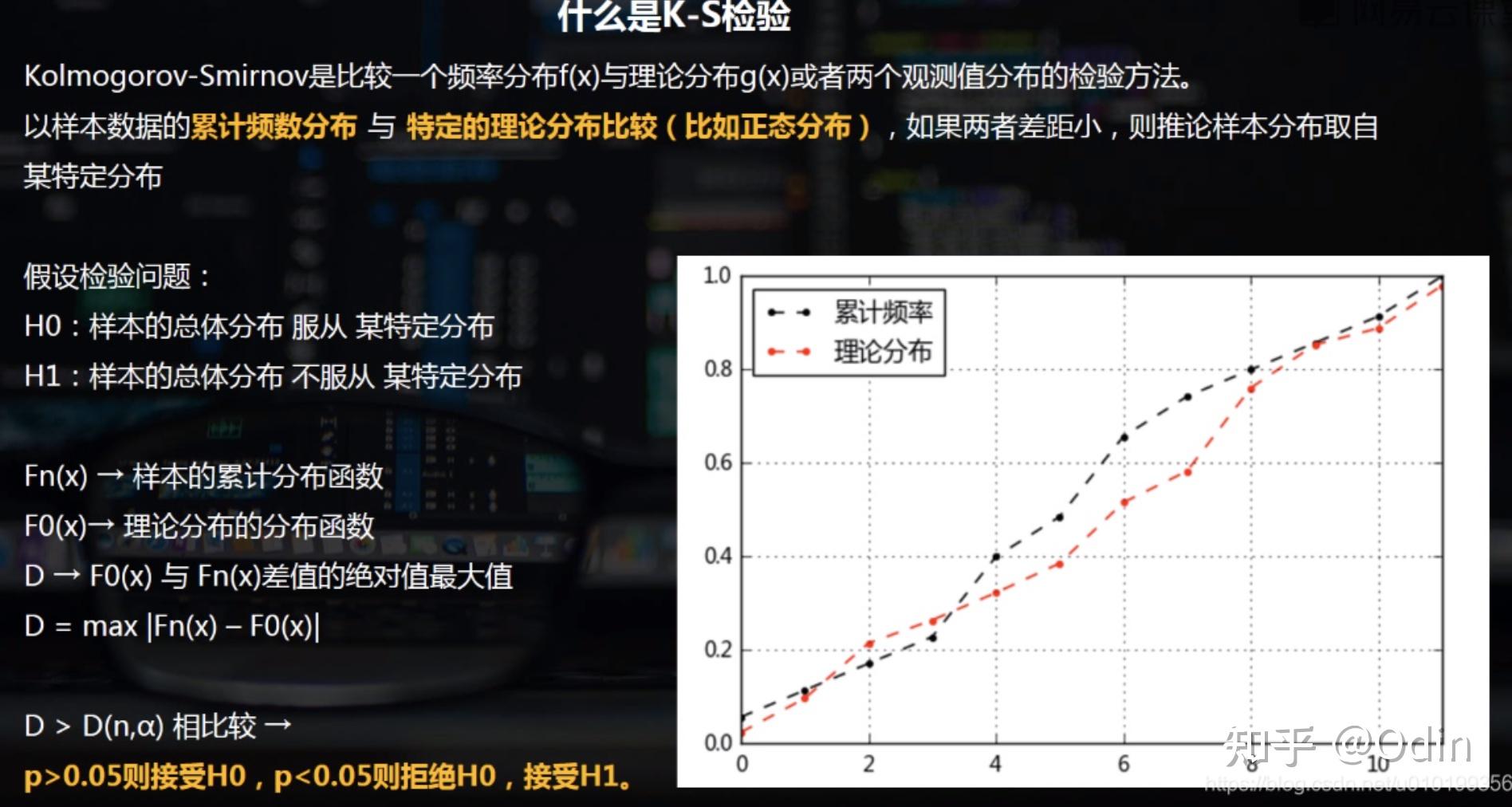
scipy.stats.kstest是一个很强大的检验模块,除了正态性检验,还能检验 scipy.stats 中的其他数据分布类型。
#运行kstest
u = df.A.mean()
std = df.A.std()
stats.kstest(df.A.values,'norm',(u,std))
KstestResult(statistic=0.016551409722181387, pvalue=0.942705289846548)kstest检验的参数是: 待检验的数据、检验方法(scipy.stats下面的函数),均值与标准差 返回值:统计量(statistic)和p-value, 如果p-value > 0.05,则待检验数据服从正态分布 ; 如果p-value <= 0.05 ,则备择假设,也就是H1为真,即 待检验数据不服从正态分布
5.2.normaltest
检验待检验数据是否 与正态分布不同 如果pvalue是>0.05,则代表是正态分布.
stats.normaltest(df.A.values)
NormaltestResult(statistic=0.005399426688700719, pvalue=0.9973039276044774)5.3 Shapiro-Wilk test
stats.shapiro(df.A.values) #输出(统计量W的值,P值)
#W的值越接近1就越表明数据和正态分布拟合得越好,P值>指定水平, 不拒绝原假设,可以认为样本数据服从正态分布
ShapiroResult(statistic=0.9980495572090149, pvalue=0.3040010631084442)更多正态分布检验的方法请参考: https://www. biaodianfu.com/python-n ormal-distribution-test.html
6.正态分布拟合(估算正态分布的参数)
如果通过上述的正态分布检验,发现df.A这组数据确实服从正态分布(p > 0.05),那么接下来,我们需要将这组数据与正态分布进行 拟合 , 估算出这组数据的均值和标准差( \mu 和 \sigma )
stats.norm.fit(df.A.values) #拟合正太分布并获取参数(mu, sigma)
(10.008189531447574, 0.9873357025164029)从结果来看,拟合得到的均值是10.02,标准差是1.012,这与我们构造df.A时使用的参数是吻合的。 构造df.A时,np.random.randn(1000)+10,randn是标准正态分布(均值为0,标准差为1),然后再加上10,均值就变成了10,标准差不变。 也就是说真实的 \mu 和 \sigma 应该分别是10和1,我们拟合的结果是10.02和1.01 ,稍微有一点点偏差,也是很正常的。
7.正态分布的假设检验(相关的p-value计算)
例如,假设某个人群的身高服从正态分布( \mu=172cm, \sigma=10 ),那么我们随机找到一个样本(人),得到的身高是195cm,那么这个人是不是属于这个群体呢?我们的零假设H0是这个人确实是来自这个群体,备择假设H1是这个样本不属于这个群体。下面来计算p-value:
# 对于,正态分布N($\mu=172, \sigma=10$),身高大于195的概率密度之和(也就是1减去195的累积分布函数)如下:
print(1-stats.norm.cdf(x=195,loc=172,scale=10)) #cdf 是累积分布函数,就是概率密度函数曲线中,x=195右侧部分的面积。
#也可以直接用残存函数(stats.norm.sf)来计算: stats.norm.sf = 1 - stats.norm.cdf
print(stats.norm.sf(x=195,loc=172,scale=10))