本文主要介绍一下 Pandas 数据清洗,处理缺失值。更多 Python 进阶系列文章,请参考
Python 进阶学习 玩转数据系列
内容提要:
-
数据缺失的现实场景
-
Python 中表示缺失值的对象
● None
● NaN
● NA
● 正负无穷 inf and -inf
-
处理缺失值
● 了解数据
● 定位缺失数据
● 处理缺失数据
-
数据应用类别
比如,患者生日,对女性来说是这个数据比较有参考意义,没有值提供的被认为是男性患者。
-
数据来源缺失
比如用户调查数据,有部分用户拒绝提供数据,数据录入系统时由于数据转换被删除一部分数据。
-
数据无效
输入格式不正确,或错误的数据(如,年龄 250 或 -5), 对这类数据就要处理成缺失数据
|
对象
|
描述
|
|
NA
|
Not Available
|
|
NaN
|
Not a Number
|
|
None
|
Pythonic missing data, a Python object that can be used in arrays with data type object
|
|
inf
|
positive infinity
|
|
-inf
|
negative infinity
|
-
None 一个 Python 对象
-
不可以用在任意的 NumPy 或 Pandas 数组里,只用于列表且数据类型是 Object。
-
默认 Pandas 会将 None 转换成 NAN
-
对包含 None 元素的数组进行计算(如: sum, min, max)会抛出 TypeError 异常。
-
NaN 是一个特殊的浮点型值
-
带有 NaN 的值进行算术运算的结果是 NaN
-
可以用特殊的函数忽略 NaN: 如 np.nansum()

注意:NaN 是浮点型类型,如果用其它类型去访问它会抛出异常。

-
Pandas 遇到缺失对象会视为 NaN
-
NumPy数组不能处理缺失对象,但能处理 NaN 值
import pandas as pd
import io
data_pd_na = '''Gender|Age|Weight
M | 22 | 72.0
F | 29 | 55.0
M | 24 |
F || 57.0
df_na = pd.read_table (io.StringIO(data_pd_na), sep = '|')
d2 = '''M 22 72.0
F 29
M 24 78.0
F 25 57.0
data_np_na = io.StringIO(d2)
np.loadtxt(data_np_na,
dtype={'names': ('Gender', 'Age', 'Color'),
'formats': ('S1', 'i4', 'f4')})

NumPy能处理 NaN的值
d3 = '''M 22 72.0
F 29 NaN
M 24 78.0
F 25 57.0
data_np_nan = io.StringIO(d3)
np_array_nan = np.loadtxt(data_np_nan,
dtype={'names': ('Gender', 'Age', 'Color'),
'formats': ('S1', 'i4', 'f4')})
np.reshape (np.array (np_array_nan), (4,1))
d3 = '''1 22 1
1 29 NaN
1 24 1
1 25 1
data_np_nan = io.StringIO(d3)
np_array_nan = np.loadtxt(data_np_nan, dtype=np.float)
print (np_array_nan)
print (np_array_nan.shape)

NaN 必须是浮点型类型,不然会抛错
# should fail if try to treat nan as int:
d4 = '''1 22 1
1 29 NaN
1 24 1
1 25 1
data_np_nan = io.StringIO(d4)
np_array_nan_int = np.loadtxt(data_np_nan, dtype=np.int)
- 正负无穷的表示:
● float(“inf”) or float(“-inf”)
● np.inf, np.PINF, -np.inf, np.NINF - 判断数字是否是正负无穷
● math 包的 math.isinf() 函数
● numpy 包的 np.isinf(), np.isposinf(), np.isneginf(), np.isfinite() 函数
import numpy as np
p_inf = float("inf")
np_posinf = np.inf
np_posinf_1 = np.PINF
n_inf = float("-inf")
np_neginf = -np.inf
np_neginf_1 = np.NINF
print("p_inf:{}".format(p_inf))
print("np_posinf:{}".format(np_posinf))
print("np_posinf_1:{}".format(np_posinf_1))
print("n_inf:{}".format(n_inf))
print("np_neginf:{}".format(np_neginf))
print("np_neginf_1:{}".format(np_neginf_1))
p_inf:inf
np_posinf:inf
np_posinf_1:inf
n_inf:-inf
np_neginf:-inf
np_neginf_1:-inf
import numpy as np
import pandas as pd
import io
x = np.array([-np.inf, 0., np.inf])
print("x:\n{}".format(np.isinf (x)))
data_pd_na = '''Gender|Age|Weight
M | 22 | 72.0
F || 55.0
M | 24 |-inf
F |inf| 57.0
df = pd.read_table (io.StringIO(data_pd_na), sep = '|')
inf_df = df.isin ([np.inf, -np.inf])
no_inf_df = df[ ~df.isin([np.inf, -np.inf]).any(1) ]
print("inf_df:\n{}".format(inf_df))
print("no_inf_df:\n{}".format(no_inf_df))
通过 pd.set_option (‘mode.use_inf_as_na’, True) 将 inf 和 -inf 用 NaN 代替
import pandas as pd
import io
pd.set_option ('mode.use_inf_as_na', False)
pd_option = pd.get_option ('mode.use_inf_as_na')
data_pd_inf = '''Gender|Age|Weight
M | 22 | 72.0
F || 55.0
M | 24 |-inf
F |inf| 57.0
df_inf = pd.read_table (io.StringIO(data_pd_inf), sep = '|')
print("options mode.use_inf_as_na:{}".format(pd_option))
print("df_inf:\n{}".format(df_inf))
pd.set_option ('mode.use_inf_as_na', True)
pd_option = pd.get_option ('mode.use_inf_as_na')
print("options mode.use_inf_as_na:{}".format(pd_option))
print("df_inf:\n{}".format(df_inf))
- 了解数据
- 定位缺失数据
- 处理缺失数据
下面通过一个例子来实战一把。
通过 shape,columns,head() 等大概了解一下数据


describe() 了解一下统计信息,只支持数字类的统计,但是没有缺失数据的报告。

df.isin([np.nan, np.inf, -np.inf]) 判断数据是否缺失
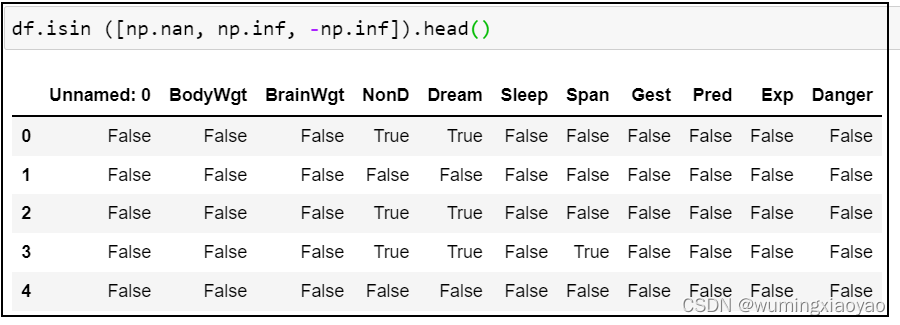
df.info() 用来了解非缺失数据的数量

还可以通过下面几种方式更直观的了解缺失数据的数量。
df.isnull().sum() 和 len(df.index) - df.count()
df.isnull().sum().sum() 和 *df.isnull().sum()/len(df)100

● 用 df.isin([np.nan, np.inf, -np.inf]) 方法
● 用 df.any() 方法只要包含任意一个缺失的值
● 最后,用 布尔数组来进行切分
df [ ~df.isin([np.nan, np.inf, -np.inf]).any(1) ].head(5)

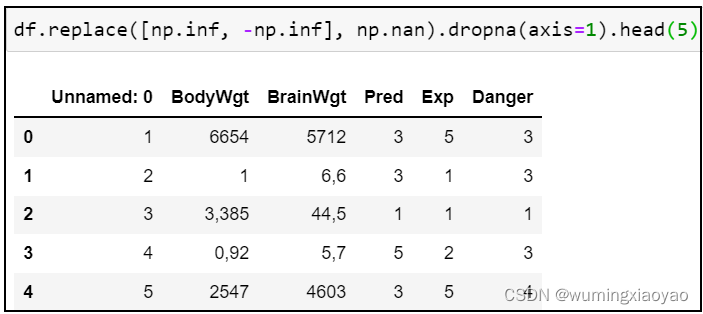
df [ df.replace([np.inf, -np.inf], np.nan).notnull().all(axis=1) ].head(5)

df.replace([np.inf, -np.inf], np.nan).dropna(axis=1).head(5)
values = {“NonD”:111, “Dream”:222, “Span”:333}
df.fillna(value = values).head()
df.fillna(555).head()

方法一:用一个样本统计量的值代替缺失值,通常用样本平均值和中位数。
方法二:用一个统计模型计算的值代替缺失值,通常用回归模型、判别模型等。
方法三:将有缺失值的记录删除。
这里仅展示方法一的Python实...
np.nan是一个float类型的数据 None是一个NoneType类型
1、在ndarray中显示时 np.nan会显示nan,如果进行计算 结果会显示为NAN.
None显示为None 并且对象为object类型,如果进行计算 结果会报错
2在pandas中, 如果其他的数据都是数值类型, pandas会把None自动替换成NaN, 甚至能将s[s.isnull()]= ...
我们获取的数据往往会存在一些重复数据,重复数据会对统计结果产生影响,也会误导决策人员的决策。
那么对DataFrame的重复项判断及删除重复项是对数据整理的基本要求。
判断数据是否有重复项 df.duplicated()
df.duplicated(self,subset=None,keep='first')
可通过 drop_duplicates() 移除重复项
df.drop_duplicates(subset=['A','B'],keep='fir...
df.isnull().sum(): 查看具体每个字段的缺失值个数
df.loc[df[col].isnull().values==True,:]:查看col字段存在缺失的数据
df.columns[df.isnull().any()].tolist():输出缺失字段的列表
2.删除缺失值
dropna...
顾名思义,any()一个序列中满足一个True,则返回True;all()一个序列中所有值为True时,返回True,否则为False。这点可从Series的any()和all()的例子中看出。
>>>pd.Series([False, False]).any()
False
>>>pd.Series([True, False]).any()
>>>pd.Series([]).any()
False
>>>pd...
一个机器的运行周期内,内部有两个内机(不会同时运行),判断这个运行周期内,单独只运行某一个内机的情况下,该周期保留,如果该周期内,出现两个内机都有运行的阶段时,或者都没有运行的阶段时,该周期剔除。
构造一组数据说明情况,0表示关机,1表示开机
import pandas as pd
df = pd.DataFrame({
'内机1': [0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0],
'内机2': [1, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1]
INF:Infinity,代表的是无穷大的意思,也是属于浮点类型。np.inf表示正无穷大,-np.inf表示负无穷大,一般在出现除数为0的时候为无穷大。比如2/0。
NAN一些特点:
NAN和NAN不

