

1. Pandas作用
用于 数据分析 、 数据处理 和 数据可视化 。
2. Pandas数据读取

使用pandas首先要导入包:
2.1 读取csv文件
加载以
逗号
为分隔符的CSV(Comma-Separated Values)文件
-
pd.read_csv()
,参数如下:
-
sep: 指定分隔符
-
names: list类型,指定columns名称
-
engine: 使用的分析引擎。可以选择C或者是python。C引擎快但是Python引擎功能更加完备。
-
header: 用作列名的行号,以及数据。
-
默认是
infer
,会将文件第一行
数据
作为列名,等同于header=0。
-
None,会默认生成数字
0,1,2,3...
作为列名。
-
数字n,会将数据的第n行作为列名。
CSV文件的第一行指定列的数据头
如果CSV文件第一行没有数据头,read_csv参数中需要指定:
header=None
2.2 读取excel文件
-
pd.read_excel(), 读取excel文件,参数如下:
-
skiprows: 忽略行数,pandas处理的时候会忽略前n行
-
df.to_execl(): 将df数据存入到excel文件,参数如下:
-
index: False,存文件时不会把索引名称 存进去;为True则会连索引一并存储。
2.3 读取json文件
2.4 读取数据库
2.4.1 读取Sqlite数据库
2.4.2 读取MySQL数据库
2.5 查看数据
3. pandas数据结构
3.1 DataFrame
DataFrame是二维数据。既有行索引index,也有列索引columns。
类型: <class 'pandas.core.frame.DataFrame'>
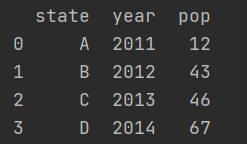
3.1.1 根据多个字典序列创建DataFrame
运行结果:
3.1.2 多维数组创建DataFrame
运行结果:
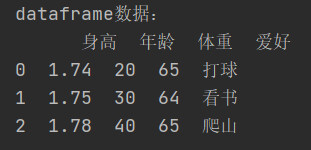
3.1.3 查询DataFrame数据
3.2 Series
Series: 一维数据,一行或一列。
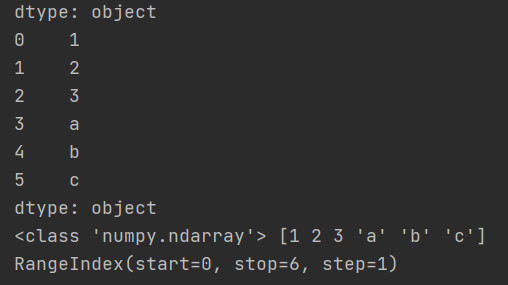
3.2.1 使用list列表创建Series
运行结果:
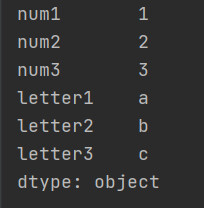
也可以指定索引名称,替换掉自动生成的数字索引
运行结果:
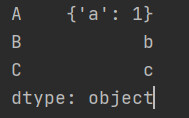
3.2.2 使用字典创建Series
使用字典生成的Series,索引为字典的key值
运行结果:
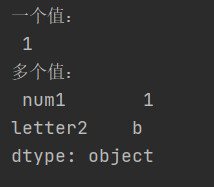
3.2.3 根据标签索引查询数据
4. Pandas查询数据
4.1 loc方法
根据行、列的标签值查询。
4.1.1 使用单个label值查询数据
得到单个值:
得到一个Series:
4.1.2 使用值列表批量查询
获取行索引为1和2,列索引为‘身高’数据,返回类型为Series
获取行索引为1和2,列索引为‘身高’和'体重'的数据,返回类型为DataFrame
4.1.3 使用数值区间进行范围查询
行索引按区间查询:
列索引按区间查询:
行和列都按区间查询:
4.1.4 使用条件表达式查询
查询身高大于等于1.75的所有行记录:
当有多个条件时,可以像下面这些写,
&符号不要切换成and
4.1.5 调用函数查询
1)使用匿名表达式查询
2)自定义函数查询
查找出爱好为看书的记录
4.2 iloc方法
根据行、列的数字位置查询
4.3 where方法
待补充...
4.4 query方法
待补充...
5. 数据新增与更新
5.1 直接赋值
例1:让所有记录的体重列增加1kg
例2:
新增
列'身高/体重',计算所有记录的该比值
或者写为如下形式
5.2 df.apply方法
对某一列统一做函数处理,注意axis=1表示的是列索引,axis=0表示的是行索引。
5.3 df.assign方法
assign方法不会修改原有的dataframe
例1:将所有记录的体重翻倍,并赋给新列
5.4 按条件选择分组分别赋值
条件判断里写的时候需要注意,在python中1<a<10这种写法是可以的,但是在.loc方法里这样写会报错,所以遇到这种情况,需要使用
&
符号连接多个条件来写。
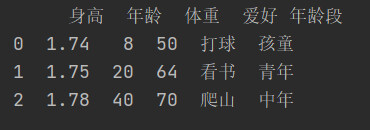
查看dataframe:
6. Pandas数据统计函数
6.1 汇总类统计
-
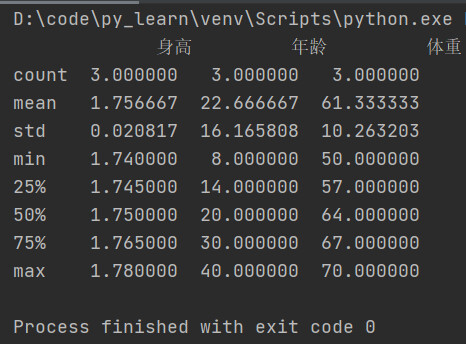
提取所有数字列统计结果
-
获取身高列的最小值
-
获取年龄列的平均值
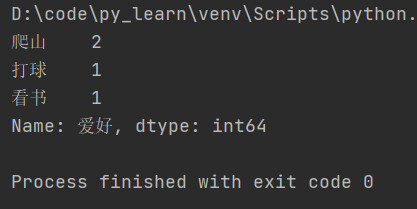
6.2 唯一去重和按值计数
-
唯一性去重
-
按值计数
6.3 相关系数和协方差
6.3.1 概念
对于两个变量X、Y:
-
协方差: 衡量同向反向程度,如果协方差为正,说明X,Y通向变化,协方差越大说明同向程度越高;如果协方差为负,说明X,Y反向运动,协方差越小说明反向程度越高。
-
相关系数:衡量相似度程度,当他们的相关系数为1时,说明两个变量变化时的正向相似度最大,当相关系数为-1时,说明两个变量变化的反向相似度最大。
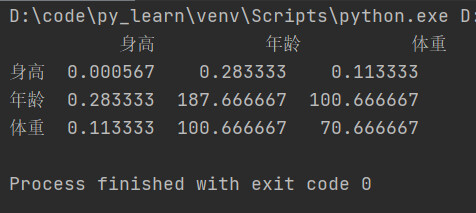
6.3.2 相关方法
-
协方差矩阵
-
相关系数矩阵
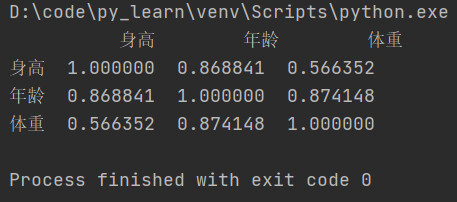
-
单独计算相关系数
计算年龄和体重的相关系数
7. Pandas对缺失值的处理
7.1 监测缺失值
-
isnull(): 判断df每个元素是否为null,是null为True,不是null为False。
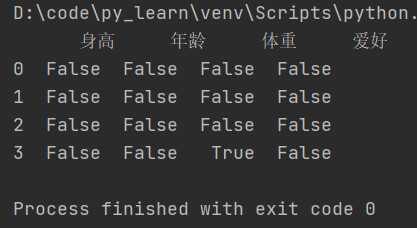
单个列判断是否都为空:
-
notnull():和isnull()相反,判断df各个元素是否不为null,不是null为True,是null为False。
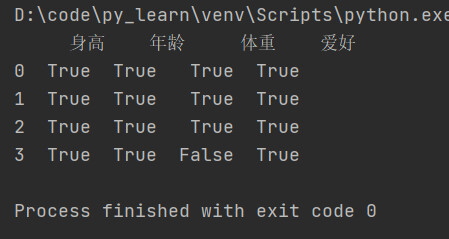
筛选体重已登记的行:
7.2 丢弃缺失值
-
dropna:丢弃、删除缺失值,以下是该函数的三个参数:
-
aixs:删除行还是列,{0 or 'index', 1 or 'columns'}, default 0。
-
how:如果等于any则任何值为空都删除,如果等于all则所有值都为空才删除。
-
inplace:如果为true则修改当前df,否则返回新的df。
删除全是空值的列
7.3 填充缺失值
-
fillna:填充空值,参数如下:
-
value: 用于填充的值,可以是单个值,或者字典(key是列明,value是值)。
-
method: 等于ffile使用前一个不为空的值填充forword fill;等于bfill使用后一个不为空的值填充 backword fill。
-
axis: 按行还是列填充,{0 or 'index', 1 or 'columns'}
-
inplace: 如果为true则修改当前df,否则返回新的df。
将体重为空的元素填充为100,默认是生成新的df,如果想在原有df上修改,需要添加参数inplace=True
等同于
8. Pandas的SettingWithCopyWarning告警
pandas不允许先筛选子dataframe,再进行修改写入。
两种解决方案:
-
使用.loc实现一个步骤直接修改源dataframe。
-
先复制一个dataframe再一个步骤执行修改。
9. Pandas数据排序
9.1 Series排序
-
Series.sort_values(): 对Series进行排序,参数如下:
-
ascending: 默认为True升序排序,为False降序排序
-
inplace: 是否修改原始Series
例子1:对体重列进行升序排序
例子2: 对体重列进行降序排列
9.2 DataFrame排序
-
DataFrame.sort_values(): 对DataFrame进行排序,参数说明如下:
-
by: 字符串或者list<字符串>,单列排序或者队列排序
-
ascending: bool或者list,升序还是降序,如果是list对应by的多列
-
inplace: 是否修改原始DataFrame
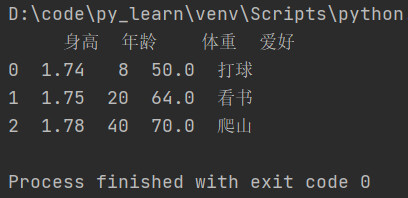
例子1:
单列排序
按照体重进行排序,默认升序
如果想要降序排列,只需要添加参数
ascending=False
即可。
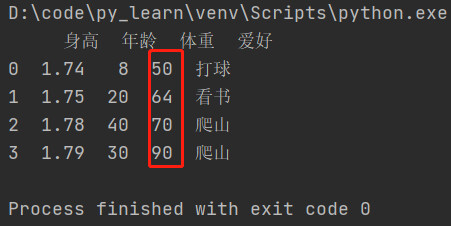
例子2:
多列排序
按照年龄和体重排序
按照年龄和体重排序,但是年龄按升序排,体重按降序排:
10. Pandas字符串处理
处理过程如下:
1)先获取Series的str属性,然后在属性上调用函数;
2)只能在字符串列上使用,不能数字列上使用;
3)DataFrame上没有str属性和处理方法;
4)Series.str并不是Python原生字符串,而是自己的一套方法,大部分和原生str很相似。
-
字符串替换:
replace
将
看
替换为
阅读
也可以写为如下形式,Series.str默认开启了正则表达式模式,也可以通过参数
regex=False
进行关闭。
-
判断是不是数字:
isnumeric
-
计算字符串长度:
len
-
以特定字符/字符串开头:
startswith
-
包含特定字符/字符串:
contains
11. Pandas的axis参数
-
axis=0或者"index"
-
如果是单行操作,就指的某一行
-
如果是聚合操作,指的是
跨行
cross rows
-
axis=1或者"columns"
-
如果是单列操作,就指的某一列
-
如果是聚合操作,指的是
跨列
cross columns
例子1: 删除一行数据
例子2: 删除一列数据
例子3: 验证
axis=0,如果是聚合操作,指的是跨行cross rows
下方代码是跨行求平均值
先看下运行结果,发现计算的是每一列的平均值。
跨行指的就是列不动,从行的方向上依次计算每列的聚合操作结果
。
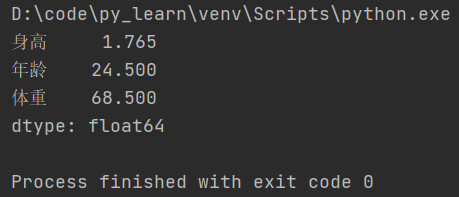
例子4: 验证
axis=1, 如果是聚合操作,指的是跨列cross columns
下方代码是跨列求平均值
从结果看出,计算的确实是每一行的平均值。
跨列指的就是行不动,从列的方向上依次计算每行的聚合操作结果
。
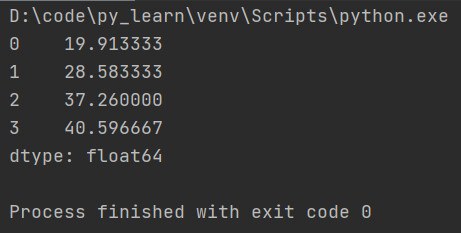
12. Pandas的索引index用途
用途:
-
方便数据查询
-
获得性能提升
-
自动数据对齐功能
-
更多数据结构支持
索引上的一些方法:
-
索引是否单调递增,是返回True,否返回False
-
索引是否唯一,是返回True,否返回False
12.1 使用index查询数据
将索引修改为user_id列,
drop=False
会让user_id保留在column
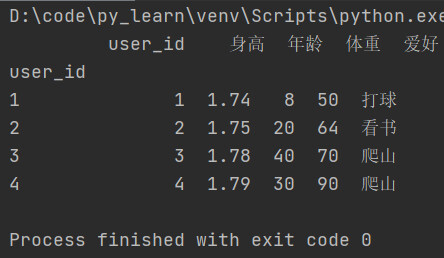
drop=True
之后,发现列user_id不见了。
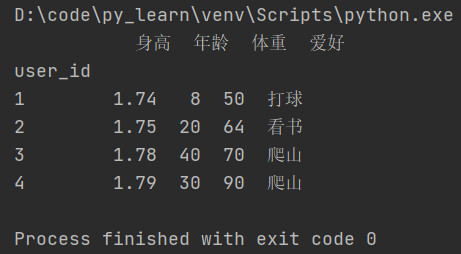
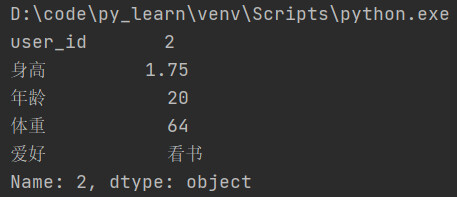
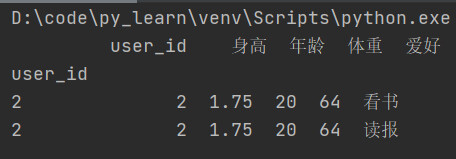
根据索引,查询id为2的数据
查询结果:如果查询结果只有一条记录,会以键值对的形式展示出来.
如果查询结果有多条记录,会以表格形式展示出来。
12.2 使用index提升查询性能
-
如果index是唯一的,Pandas会使用哈希表优化,查询性能为O(1);
-
如果index不是唯一的,但是有序,Pandas会使用二分查找算法,查询性能为O(logN);
-
如果index是完全随机的,那么每次查询都要扫描全表,查询性能为O(N)。
12.3 使用index自动对齐数据
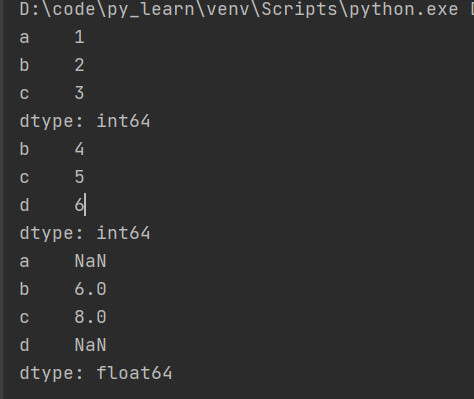
参考下方代码,当两个Series相加时,相等的index对应的列会被对应相加,但是各自独有的index,相加后变为了NaN。
12.4 使用index更多更强大的数据结构支持
-
CategoricalIndex,基于分类数据的Index,提升性能;
-
MultiIndex,多维索引,用于groupby多维聚合后结果等;
-
DatetimeIndex,时间类型索引,强大的日期和时间的方法支持。
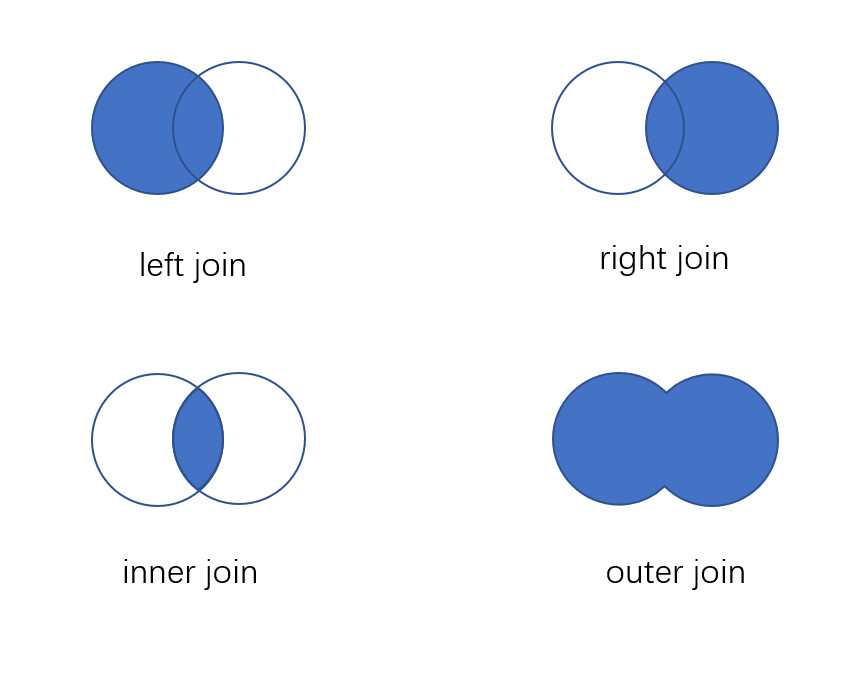
13. Pandas的Merge语法
-
left, right: 要merge的dataframe或者有name的Series。
-
how: join类型, left, right, outer, inner
-
on: join的key,left和right都需要有这个key
-
left_on: left的df或者series的key
-
right_on: right的df或者series的key
-
left_index, right_index: 使用index而不是普通的column做join
-
suffixes: 两个元素的后缀,如果列有重名,自动添加后缀,默认是('_x', '_y')
左连接、右连接、内连接、外连接区别
14. Pandas的Concat合并
语法:
pd.concat(objs, axis=0, join='outer', ignore_index=False)
-
objs: 一个列表,可以是DataFrame或者Series,也可以是DataFrame和Series的混合列表。
-
axis: 默认是0,按行合并,如果等于1代表按列合并。
-
join: 合并的时候索引的对齐方式,默认是outer join,也可以是inner join。
-
ignore_index: 是否忽略掉原来的数据索引。
15. Pandas拆分
拆分:
df.iloc[]
例子:
16. Pandas分组统计groupby
groupby: 先对数据分组,然后在每个分组上应用聚合函数、转换函数。
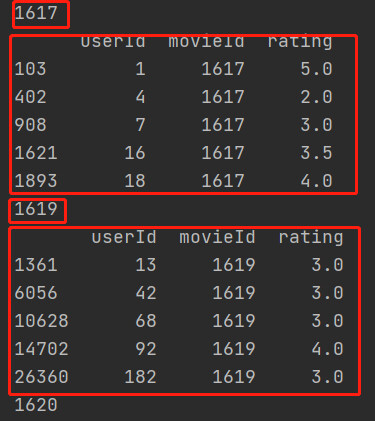
16.1 groupby相关操作
-
遍历groupby结果
-
获取单个分组的数据
16.2 groupby实例
-
单个列groupby,查询所有数据列的统计
求电影的平均分
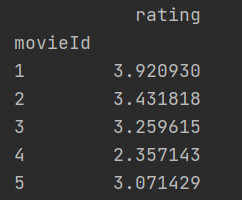
-
多个列groupby,查询所有数据列的统计
下方代码会先对userId分组,然后再对movieId分组,然后再求分组后的其他列的平均值。此时的userId和movieId变成了
二级索引
。
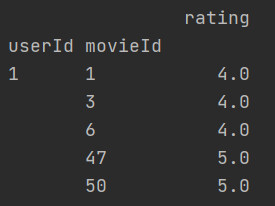
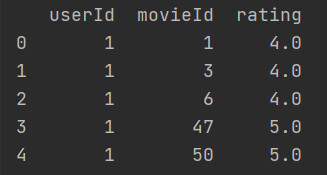
下方代码比上面的代码多了参数
as_index=False
,A和B不再是索引,而是结果中的一部分。
-
同时查看多种数据统计
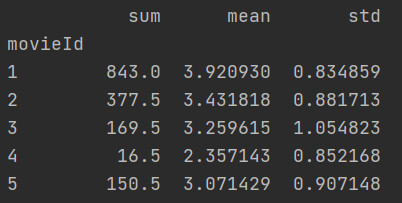
求每部电影的评分总和、评分平均值、评分标准差
从结果可以看出列分出了二级索引。
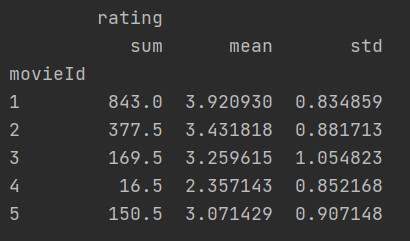
-
查看单列的结果数据统计
分组之后获取某一列的总和、平均值和标准差
发现二级索引没了,这里提前对分组后的列做了过滤,性能会更好。
-
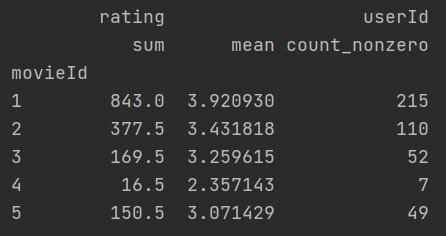
不同列使用不同的聚合函数
按电影id分组后,对评分求平均值和总和,对userId求个数。
17. Pandas分层索引
17.1 常用操作
-
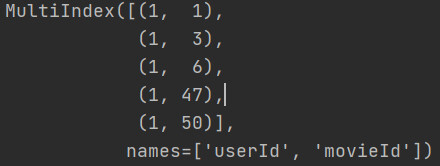
查看索引
以下会生成一个二级索引
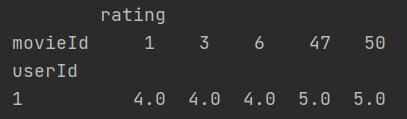
-
把二级索引变成列
-
把所有索引都变成列
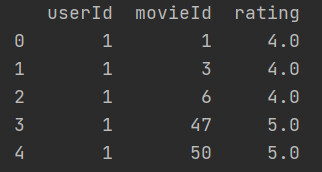
-
设置索引
将元数据的userId和movieId设置为索引。
-
对索引排序
18. 数据转换函数map、apply、applymap
18.1 map
map只用于Series,实现每个值-》值的映射。
使用方法:
-
Series.map(dict)
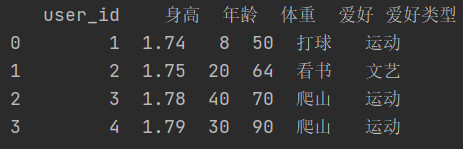
-
Series.map(function)
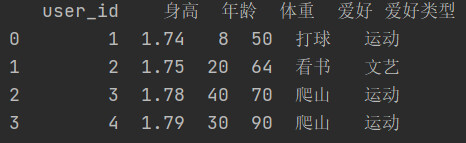
18.2 apply
apply用于Series实现每个值的处理,用于Dataframe实现某个轴的Series的处理。
-
Series.apply(function)
-
DataFrame.apply(function)
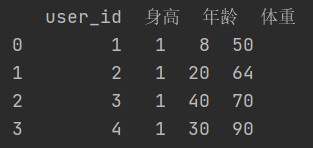
18.3 applymap
只能用于DataFrame,用于处理该DataFrame的
每个
元素。
例子:
19. Pandas的stack和pivot实现数据透视
将列式数据变成二维交叉数据,便于分析,叫做重塑或透视。
透视的方法:
19.1 使用unstack实现数据二维透视
stack: DataFrame.stack(level=-1, dropna=True),将column变成index
level=-1代表多层索引的最内层,可以通过==0、1、2指定多层索引的对应层。
unstack: DataFrame.unstack(level=-1, fill_value=None),将index变成column。
例子:
原始数据如下:
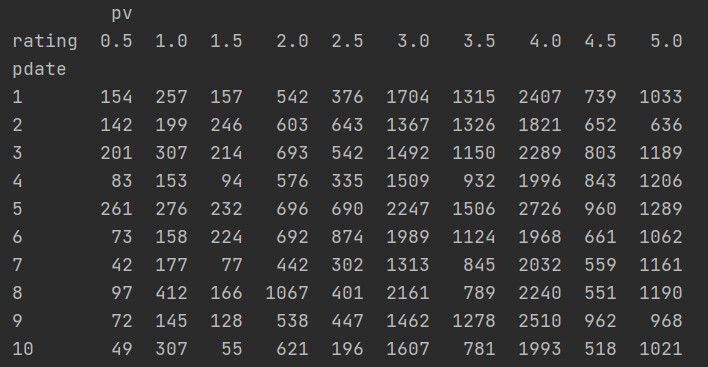
unstack之后的数据如下:
stack之后的数据如下:

参考代码:
透视之后效果:
19.2 使用pivot简化透视
pivot: DataFrame.pivot(index=None, columns=None, values=None)
指定index、columns、values实现二维透视。
原始数据:
参考代码:
透视效果:
pivot方法相当于对df使用set_index创建分层索引,然后调用unstack。
20. 参考资料
-
Pandas官方中文文档: https://www.pypandas.cn/docs/getting_started/
-
电影数据集: https://grouplens.org/datasets/movielens/









































