


多元线性回归方程的拟合—R语言描述

1.数据集及相关背景介绍
本数据集采用2002年和2003年数据各500条,计划通过利用2002年净资产收益率roe(Rate of Return on Common Stockholders’ Equity)和其他相关数据建立多元线性回归方程,并对2003年的ROEt进行预测。
净资产收益率Roe(Rate of Return on Common Stockholders’ Equity)是公司税后利润除以净资产得到的百分比率,该指标反映股东权益的 收益水平 ,用以衡量公司运用 自有资本 的效率。指标值越高,说明投资带来的收益越高。该指标体现了自有资本获得净收益的能力。
本次数据集因变量为当年净资产收益率ROEt,自变量为资产周转率ATO(Asset Turnover) ,利润率PM(profit margin),资产负债率LEV,主营业务增长GROWTH,市倍率PB(price to book),主营业务收入ARR(account receivable over total income),资产估计INV(inventory to asset),资产总计ASSET,净资产收益率ROE(Rate of Return on Common Stockholders’ Equity)共计9项,这些因变量都或多或少的影响了当年净资产收益率的大小,因而我们本次初步建立模型都将其纳入因变量的考察范围之内,在使其对应变量的影响情况决定是否保留该自变量。
本次报告的结构如下:
第2章主要对原始数据进行描述统计分析,通过绘制相应的图像和计算来使研究者对各数据有一定的整体认识。在对数据进行简单的描述分析后,我们将在第3章对数据进行多元回归建模,具体来说,有数据预处理、建立数学模型、回归参数估计、残差分析、显著性检验等。由于在很多情况下原始数据中都存在着众多的无关变量,因而原始模型(利用全部原始数据建模而得)需要进一步的优化,第4章我们进行对模型的优化,从而使得模型的可解释性更强。到第4章结束,对于模型的建立和优化已经完成,第5章我们将利用2003年数据对模型进行检验,判断该模型的预测精度,最后的部分,我们将对本报告进行简单的小结。
2.对数据进行描述性分析
首先,我们通过绘制数据集箱线图进行一个初步的认识,以ROEt为例,利用plotly包绘出箱线图如下:
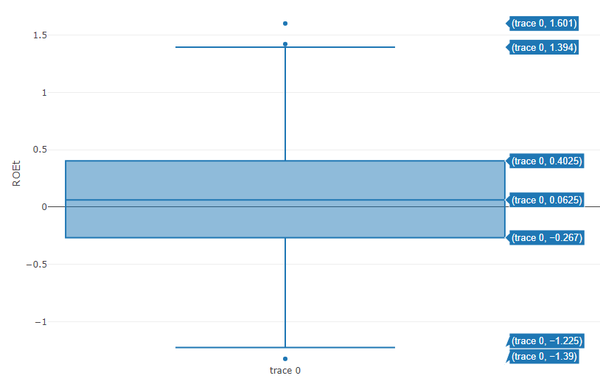
从图中我们可以看到,2002年ROEt的极大值为1.601,极小值为-1.39,中位数为0.0625,稳定性程度我们将通过其计算方差大小来进行衡量。R语言中提供了summary()函数用于描述统计度量。
#dat is the roe data which in 2002
summary(dat) #min,1st qu,median,mean,3rd Qu,max, var is not in it
matrix=var(dat)
var=diag(matrix) #var
上述描述性统计分析往往是数据的预处理的前奏环节,通过观察某一属性的波动情况,我们可以有针对性的对其作出删除,修正等其他操作。因而,在真正对数据进行预处理前,对原始数据集进行简单的描述统计这一工作是很有必要的。
3.多元线性回归建模
3.1数据集和数学模型
本次采用的数据集为2002年至2003年的净资产收益率以及相关影响变量,利用2002年数据进行建模后通过2003年数据对模型进行检验,首先将数据导入R中。
#dat is the roe data which in 2002
dat=read.table("roe2002.txt",header=T)
数据集共有11列:
•year:时间,本数据集均为2002年数据
•ROEt:当年净资产收益率 •ATO:资产周转率
•PM:利润率 •LEV:资产负债率
•GROWTH:主营业务增长 •PB:市倍率
•ARR:主营业务收入 •INV:资产估计
•ASSET:资产总计 •ROE:净资产收益率
现假设当年净资产收益率ROEt与其他9个变量存在某种线性关系,以此我们建立起以ROEt为因变量,ATO、PM、LEV等其他九种变量为自变量的多元线性回归模型,其模型表示为:
Y=a+b*x1+c*x2+d*x3+e*x4+f*x5+g*x6+h*x7+i*x8+j*x9+ε
•y:为因变量,当年净资产收益率
•a:自变量系数 •x1:为ATO,资产周转率
•x2:为PM,利润率 •x3:为LEV,资产负债率
•x4:为GROWTH,主营业务增长 •x5:为PB,市倍率
•x6:为ARR,主营业务收入 •x7:为INV,资产估计
•x8:为ASSET,资产总计 •x9:为ROE,净资产收益率
•b,c,d,e,f,g,h,I,j:为自变量系数
•ε:为残差,是其他一切不确定因素影响的总和,其值不可观测。假定ε服从正态分布N(0,σ^2)
通过对多元线性回归模型的定义,我们可以利用参数估计对自变量系数进行估计。
3.2数据预处理
本次建模数据为2002年与净资产收益率有关的属性数据,对其预处理以检查是否存在缺失值为主,而异常值处理我们将在对模型进行残差分析时进行操作。
观察本次数据,并未发现存在缺失值,因而此处从略。
3.3回归参数估计
在上式中,a,b,c,d,e,f,g,h,i,j均未知,所谓参数估计,就是利用现有数据对自变量系数进行估计,从而确定自变量与因变量的相互关系。本报告中我们使用最小二乘估计参数,所谓最小二乘法,就是通过确定一直线,使直线上每个点的Y值和实际数据的Y值之差的平方和最小,即(Y1实际-Y1预测)^2+(Y2实际-Y2预测)^2+ …… +(Yn实际-Yn预测)^2 的值最小。参数估计时,我们只考虑Y随X自变量的线性变化的部分,而残差ε是不可观测的,参数估计法并不需要考虑残差。
R语言中lm()函数可以很方便的拟合多元线性函数,下面我们将使用它进行参数估计。
#set up multiple linear regression models
lm1=lm(ROEt~ATO+PM+LEV+GROWTH+PB+ARR+INV+ASSET+ROE,data=dat)
输出结果为:
#result
Call:
lm(formula = ROEt ~ ATO + PM + LEV + GROWTH + PB + ARR + INV +
ASSET + ROE, data = dat)
Coefficients:
(Intercept) ATO PM LEV GROWTH
-1.369599 0.044638 0.163587 -0.010243 -0.007482
PB ARR INV ASSET ROE
-0.001822 0.012133 -0.052567 0.057531 0.458419
由此,自变量与因变量的关系确定为:
Y=-1.27+0.047*x1+0.163*x2-0.010*x3-0.007*x4-0.002*x5+0.012*x6-0.052*x7+0.058*x8+0.458*x9
3.4残差分析和异常点检测
在完成对模型的初步建立后,需对模型进行残差分析检验,以此来判断模型的正确性,残差必须服从正态分布N(0,σ^2)。R语言中plot()函数用于生成4种用于模型诊断的图形,以便进行直观地分析。
#Residual analysis
par(mfrow=c(2,2))
plot(lm2)
检验结果如下:
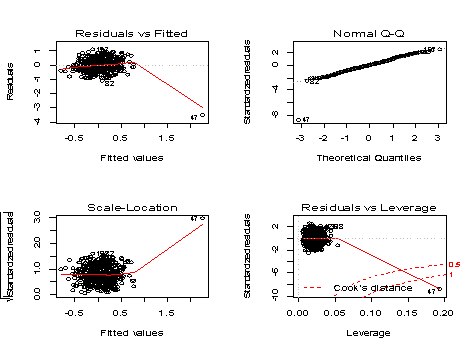
•残差和拟合值(左上),残差和拟合值之间数据点大部分均匀分布在y=0两侧,红色线呈现出先平稳后陡峭的形状特征,说明原数据集存在部分异常点如第47行数据。
•残差QQ图(右上),数据点按对角直线排列,趋于一条直线,并被对角直接穿过,直观上符合正态分布。
•标准化残差平方根和拟合值(左下),数据点大部分均匀分布在y=0两侧,呈现出随机的分布,红色线呈现出先平稳后陡峭的形状特征,说明原数据集存在部分异常点。
•标准化残差和杠杆值(右下),出现红色的等高线,则说明数据中存在特别影响回归结果的异常点。
根据上图,我们首先对数据集进行异常点的处理,由于原数据集是一组500*10的历史收盘数据,数据量较为充足,本次采用剔除异常值的处理方式,我们对原数据集剔除第47,82,197行数据,再次进行残差分析,分析结果如下:
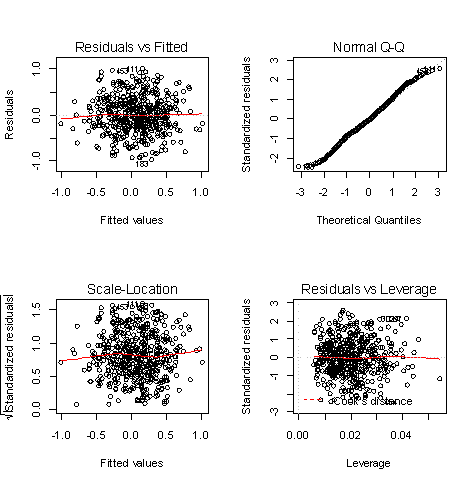
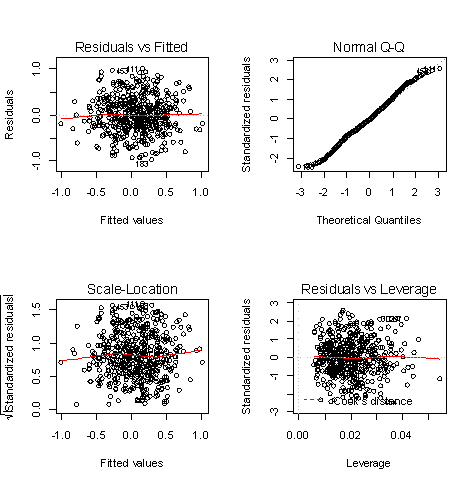
•残差和拟合值(左上),残差和拟合值之间数据点均匀分布在y=0两侧,呈现出随机的分布,红色线呈现出一条平稳的曲线并没有明显的形状特征。
•残差QQ图(右上),数据点按对角直线排列,趋于一条直线,并被对角直接穿过,直观上符合正态分布。
•标准化残差平方根和拟合值(左下),数据点均匀分布在y=0两侧,呈现出随机的分布,红色线呈现出一条平稳的曲线并没有明显的形状特征。
•标准化残差和杠杆值(右下),没有出现红色的等高线,则说明数据中没有特别影响回归结果的异常点。
在剔除一组异常点后,上述结果表明残差检验已经通过,但仔细观察残差和拟合值一图(左上)后,发现仍有部分异常值如111,453,183等,为保证模型的精度,我们决定再次剔除部分异常值,在后续的显著性检验时分别比较。
3.5回归方程的显著性检验
回归方程的显著性检验,需要通过T检验,F检验和R2检验,我们利用summary()函数对上述两组回归方程(剔除一次和剔除两次)进行检验。
#Significant test (eliminate outlier the first time)
Summary(lm1)
检验结果如下:
#the result of Significant test
Call:
lm(formula = ROEt ~ ATO + PM + LEV + GROWTH + PB + ARR + INV +
ASSET + ROE, data = dat)
Residuals:
Min 1Q Median 3Q Max
-0.97918 -0.25667 -0.02101 0.24762 1.01026
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) -1.270937 0.461511 -2.754 0.00611 **
ATO -0.015555 0.042215 -0.368 0.71268
PM 0.137449 0.116888 1.176 0.24021
LEV -0.007095 0.009422 -0.753 0.45179
GROWTH -0.007892 0.008507 -0.928 0.35402
PB -0.001315 0.003063 -0.429 0.66785
ARR 0.014458 0.021437 0.674 0.50035
INV -0.057685 0.147995 -0.390 0.69687
ASSET 0.051585 0.021778 2.369 0.01824 *
ROE 0.613313 0.038528 15.919 < 2e-16 ***
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Residual standard error: 0.4002 on 487 degrees of freedom
Multiple R-squared: 0.4028, Adjusted R-squared: 0.3917
F-statistic: 36.49 on 9 and 487 DF, p-value: < 2.2e-16
剔除一次异常值检验结果如下:
•T检验:只有自变量ASSET和ROE通过了显著性检验,其他变量均不显著
•F检验:显著,p-value: < 2.2e-16,通过F检验
•R2:修正后的R2为0.3917,较为合理
#Significant test (eliminate outlier the second time)
Summary(lm1)
检验结果如下:
#the result of Significant test
Call:
lm(formula = ROEt ~ ATO + PM + LEV + GROWTH + PB + ARR + INV +
ASSET + ROE, data = dat)
Residuals:
Min 1Q Median 3Q Max
-0.95447 -0.25217 -0.02377 0.24423 0.94037
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) -1.3111223 0.4543460 -2.886 0.00408 **
ATO -0.0036262 0.0416182 -0.087 0.93060
PM 0.1382860 0.1151989 1.200 0.23057
LEV -0.0066610 0.0093152 -0.715 0.47492
GROWTH -0.0092275 0.0083820 -1.101 0.27150
PB -0.0007362 0.0030252 -0.243 0.80784
ARR 0.0113148 0.0211193 0.536 0.59237
INV -0.1017504 0.1459435 -0.697 0.48602
ASSET 0.0531665 0.0214369 2.480 0.01347 *
ROE 0.6217375 0.0380162 16.355 < 2e-16 ***
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Residual standard error: 0.3937 on 484 degrees of freedom
Multiple R-squared: 0.4158, Adjusted R-squared: 0.405
F-statistic: 38.28 on 9 and 484 DF, p-value: < 2.2e-16
剔除两次次异常值检验结果如下:
•T检验:只有自变量ASSET和ROE通过了显著性检验,其他变量均不显著
•F检验:显著,p-value: < 2.2e-16,通过F检验
•R2:修正后的R2为0.405,较为合理
通过比较两次显著性检验结果,我们发现对于剔除两次异常值的显著性检验除修正后R2比第一次检验有稍许提升外,其余并没有变化,为保证原始数据利用最大化,我们决定采用只剔除一次异常值的数据集用于后续的分析和优化。
4.模型优化
4.1模型优化及优化后的模型显著性检验
由于上述模型t检验结果并不理想,下面将对原始模型(剔除一次异常值的数据集形成的模型)进行优化。对于模型优化的过程,如果我们手动调整测试时,一般都会基于业务知识来操作。如果是按照数据指标来计算,我们可以用R语言中提供的逐步回归的优化方法,通过AIC指标来判断是否需要参数优化。本次我们采用逐步回归进行模型的优化。
#Use stepwise regression to optimize the model
step(lm1)
优化结果如下:
#the result of optimization
Start: AIC=-900.29
ROEt ~ ATO + PM + LEV + GROWTH + PB + ARR + INV + ASSET + ROE
Df Sum of Sq RSS AIC
- ATO 1 0.022 78.037 -902.15
- INV 1 0.024 78.040 -902.13
- PB 1 0.030 78.045 -902.10
- ARR 1 0.073 78.088 -901.82
- LEV 1 0.091 78.106 -901.71
- GROWTH 1 0.138 78.153 -901.41
- PM 1 0.222 78.237 -900.88
<none> 78.015 -900.29
- ASSET 1 0.899 78.914 -896.59
- ROE 1 40.594 118.609 -694.08
.........
Step: AIC=-908.78
ROEt ~ LEV + ASSET + ROE
Df Sum of Sq RSS AIC
<none> 78.568 -908.78
- LEV 1 0.520 79.088 -907.50
- ASSET 1 1.050 79.618 -904.18
- ROE 1 41.183 119.751 -701.32
Call:
lm(formula = ROEt ~ LEV + ASSET + ROE, data = dat)
Coefficients:
(Intercept) LEV ASSET ROE
-1.29964 -0.01079 0.05379 0.61065
一般来说,衡量模型拟合度的指标有很多,常见的有AIC和BIC指标。根据上述结果,优化后模型保留的自变量为LEV,ASSET和ROE三个指标,其相应的AIC值小于初始值(初始其AIC分别为:-901.7、-896.6、-694.1)。我们对保留的指标再次进行建模并进行相应的显著性检验。
再次建模:
#Refit the regression equation again
lm2=lm(formula = ROEt ~ LEV + ASSET + ROE, data = dat)
Summary(lm2)
进行显著性检验:
#the result of Significant test after optimization
Call:
lm(formula = ROEt ~ LEV + ASSET + ROE, data = dat)
Residuals:
Min 1Q Median 3Q Max
-0.96786 -0.26724 -0.03264 0.25859 1.05364
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) -1.299636 0.441143 -2.946 0.00337 **
LEV -0.010793 0.005976 -1.806 0.07151 .
ASSET 0.053786 0.020950 2.567 0.01054 *
ROE 0.610648 0.037986 16.075 < 2e-16 ***
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Residual standard error: 0.3992 on 493 degrees of freedom
Multiple R-squared: 0.3985, Adjusted R-squared: 0.3949
F-statistic: 108.9 on 3 and 493 DF, p-value: < 2.2e-16
结果表明,除修正后的R2依旧维持在0.4左右的水平上,T检验和F检验均通过(T检验:大部分自变量p值均小于0.05,LEV变量p值为0.1,F检验的p值远小于0.05)。而在统计学中,修正后的R2并不能完全作为衡量一个模型的准则,例如在回归分析中,我们得到一个很高的R2值,但某些自变量回归系数可能并不显著或者与经验背离,在这种情况下,R检验就不是一个很好的准则来衡量模型。
最终我们得到了本次数据集的多元线性模型,其表达式如下:
Y=-1.3-0.011*x3+0.054*x8+0.61*x9
•x3:为LEV,资产负债率
•x8:为ASSET,资产总计
•x9:为ROE,净资产收益率
5.模型预测
在完成对模型的建立后,我们利用R语言的predict()函数来计算预测值y0和相应的预测区间,并把实际值和预测值一起可视化化展示。
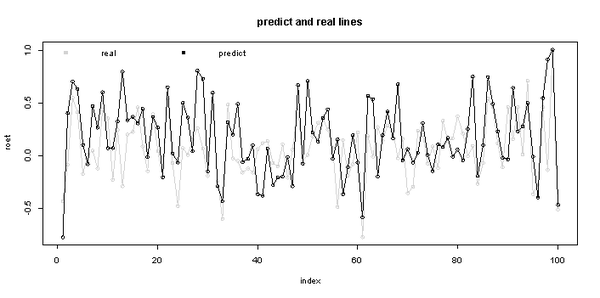
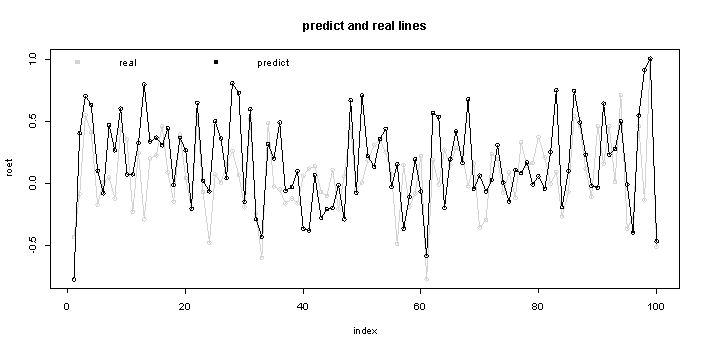
•real:为2003年实际ROEt值
•predict:为利用上述模型预测2003年ROEt值
上图展示的是2003年前100条预测数据与实际数据的折线图,图中我们看出2003年实际ROEt值与预测值整体是很贴近的,我们下面通过计算MSFE(Mean Squared Forecasting Error)和MAFE(mean absolute forecasting error )来进一步对模型的精度进行量化说明。
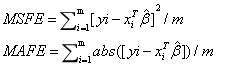
•MSFE: 均方误差(Mean Squared Forecasting Error)是指参数估计值与参数真值之差平方的期望值
•MAFE:绝对均差( Mean Absolute Forecasting Error) 是指参数估计值与参数真值绝对差值的期望
•MSFE、MAFE可以评价数据的变化程度,其值越小,说明预测模型描述实验数据具有更好的精确度。
#calculate MSFE and MAFE
msfe=sum(((dat2$ROEt-dfp)^2)/length(dfp))
mafe=sum(abs(dat2$ROEt-dfp)/length(dfp))
计算结果为MSFE=0.1394068
MAFE=0.2959807
计算结果表明,模型预期2003年ROEt值与真值的均方误差和绝对均差分别为0.14和0.30左右,整体来说并不大,说明预测模型对后一期有着较好的预测水平。
6.小结
本数据集采用2002年和2003年数据各500条,通过利用2002年净资产收益率roe(Rate of Return on Common Stockholders’ Equity)及其相关变量建立多元线性回归方程并对2003年相应数据进行预测。在建立回归方程后,发现原始数据集中只有LEV,ASSET,ROE三项指标对ROEt存在显著性影响,其模型如下:
ROEt=-1.3-0.011*LEV+0.054*ASSET+0.61*ROE
根据模型含义,通俗的讲,我们对于ROEt的未来预期在很大程度上依赖于ROE值和截距项(-1.3),这在一定程度上减轻了未来预期的工作量,对于指导实践有着一定的意义。
在模型拟合精度上,本模型通过了F检验,p值远小于0.05,修正后的R2在0.40左右,具有较强的解释能力。在模型预测水平上,本模型利用2003数据对方程进行检验,计算结果表明,模型预期2003年ROEt值与真值的均方误差和绝对均差分别为0.14和0.30左右,整体来说并不大,说明预测模型对后一期有着较好的预测水平。
参考文献:
1.粉丝日志:R语言解读多元线性回归模型
http:// blog.fens.me/r-multi-li near-regression/
2.百度文库:第01章线性回归
https:// wenku.baidu.com/view/83 39a051a98271fe910ef968.html?pn=50
3.CSDN:线性回归及预测
http:// blog.csdn.net/charie411 /article/details/72780664
4.CSDN:R语言︱异常值检验、离群点分析、异常值处理
http://blog.csdn.net/sinat_26917383/article/details/51210793
5.CSDN:R语言ggplot2包之画折线图
http:// blog.csdn.net/zx4034135 99/article/details/46854275
6.CSDN:使用R包ggplot2画箱线图(boxplot)
http:// blog.csdn.net/msw521sg/ article/details/52882000
附件:
R源代码:
dat1=read.table("roe.txt",header=T)
dat2=dat1[dat1$year==2003,-1]
write.csv(dat2,'1.csv',row.names=F)
dat=dat2[-c(47,82,197),]
write.csv(dat,'2222.csv',row.names=F)
dat3=dat[-c(111,453,183),]
write.csv(dat3,'3333.csv',row.names=F)
dat2=read.csv("1.csv",header=T)
dat=read.csv("2222.csv",header=T)
dat3=read.csv("3333.csv",header=T)
plot(dat1)
summary(dat1)#min,1st Qu,median,mean,3rd Qu,max, var is not in it
matrix=var(dat1)
var=diag(matrix) #var
a=apply(dat1,2,summary)
pairs(as.data.frame(dat1))
#箱线图
#ggplot
par(mfrow=c(2,2))
library(ggplot2)
p<-ggplot(data=dat2, aes(x=attributes,y=value))+geom_boxplot(aes(fill=attributes))
p+facet_wrap(~attributes, scales="free")+ xlab(" attributes of dataset") + ylab("values")
ggplot(data=dat2, aes(x=attributes,y=value))+geom_boxplot(aes(fill=attributes$roet))
#ployly
library(plotly)
plot_ly(dat1,y=~ROEt, type = "box")
plot_ly(dat1,y = ~ROEt, type = "box", boxpoints = "all", jitter = 0.3,
pointpos = -1.8)%>%
add_trace(x='ROEt',y = ~ROEt)%>%
#折线图
plot(dat1$ROEt[1:100],main='ROEt lines(the first one hundred data)',xlab='index',ylab='roet',axes=T,lwd=2,col='grey',type="o")
par(new=T)
#回归模型
lm1=lm(ROEt~ATO+PM+LEV+GROWTH+PB+ARR+INV+ASSET+ROE,data=dat)
#summary(lm1)
#par(mfrow=c(2,2))
#plot(lm1)
step(lm1)
lm2=lm(formula = ROEt ~ LEV + ASSET + ROE, data = dat)
#绘制预测曲线
dat2=dat1[dat1$year==2003,-1]
dat2=dat2[,c(1,4,9,10)]
dat2=data.frame(dat2)
dfp=predict(lm2,dat2,intercal="prediction")
#取前100条记录
dfp100=dfp[1:100]
dat3=dat2[1:100,]
plot(dfp100,main='predict and real lines',xlab='index',ylab='roet',axes=T,lwd=2,col='lightgrey',type="o")
par(new=T)
plot(x=rownames(dat3),y=dat2$ROEt[1:100],xlab='index',ylab='roet',axes=F,lwd=2,col='black',type="o")
txt.legend=c('predict','fit')
col2=c('lightgrey','black')
txt.legend=c('real','predict')
legend('topleft',pch=c(15,15,NA,NA),lty=c(NA,NA,1,1),legend=txt.legend,col=c(col2),ncol=2,bg="white",bty='n')
#head(dfp)
#Length(dfp)
#head(dat2)
#dim(dat2)
#计算MSFE,MAFE
msfe=sum(((dat2$ROEt-dfp)^2)/length(dfp))
mafe=sum(abs(dat2$ROEt-dfp)/length(dfp))