

比较几种条件求和的方法——推荐PowerBI

比较几种条件求和的方法:
1) Excel鼠标框选,配合使用筛选功能,界面右下角显示求和结果。
优点:可以快速、直观地满足一次简单的业务需求。
缺点:只能快速地满足一次比较简单的查询需求,且求和结果无法被记录。
2) Excel公式:sum、sumif、subtotal(9,)等。
优点:可以记录求和结果;能够进行复杂一点的条件求和;在原始表上操作,比较直观。
缺点:在原始表上操作,可能在统计的过程中手误改动原始数据。
3) Excel智能表格的汇总行,配合使用筛选功能。
优点:可以同时汇总多个字段,同时因为是在原始表上操作的,也比较直观。
缺点:需将整个原始数据表设置为智能表格,数据量巨大,数据处理效率低。

4) Excel插入数据透视表。
优点:能够进行更复杂一点的条件汇总,且不改动原始数据表,插入一个数据透视表单独进行操作,筛选条件、汇总计算等。
缺点:尽管能够叠加不同的筛选条件,但如果涉及到并表关联查询的需求,或是数据不规范的情况,处理能力有限。

5) 在Power BI Desktop里建立关系型数据库,使用DAX语言编写查询。 Power BI跟Excel一样,都是微软的产品,与Excel有诸多相似之处,又能实现更复杂一些的功能。
优点:可以得到 有迹可循 的、能根据上下文 动态计算 的统计结果;可以并表查询;在数据不规范的情况下可以通过一些方法来进行模糊匹配。
缺点:需要在Excel以外的另一个软件进行操作;直观性不如Excel;仍然是以一个个分散的度量值来构建统计模型的,代码的可读性相对SQL可能较弱。

6) 在SQL Server Management Studio里建立关系型数据库,使用SQL语言编写查询。 这个也是微软的产品。
优点:跟Power BI一样是通过建立关系型数据库、或通过关联表来实现统计分析的,而非多次人工应用筛选器后再进行汇总。
SQL的独特优势是,能够以一段代码作为实现某个需求的完整过程,而不是将该需求划分为多个子任务,通过一个个分散的度量值实现需求。
这里的某个需求为“统计10月的销售情况”,子任务为“统计10月销售额”、“统计1-10月本年累计销售额”、“统计渠道A的销售额”等。在PowerBI中,这些子任务是通过一个个度量值来计算的,最终将多个度量值放到面板中,以实现完整的统计需求。而在SQL中,这些子任务可以作为一段代码中的章节,共同构成这篇代码,以实现完整的统计需求。
从这点上看,用SQL语言编写查询的一大优势是代码的 完整性和可读性 。
缺点:需要在Excel以外的另一个软件进行操作;直观性不如Excel,且比Power BI更加抽象了。
推荐Power BI进行条件求和 。它的使用门槛较SQL更低,又能实现比Excel更复杂一点的功能;跟Excel有诸多相似之处,又比Excel有着更规范的操作路径,即通过建立数据库模型来进行统计。
1、业务需求:
按各字段进行【条件筛选】,并对某一指标进行【求和运算】。
希望可以满足:
(1)统计过程有迹可循。
目前,在用的系统可以满足筛选、求和、显示结果的需求。但一个个查询没有操作行为的记录,难以核对统计过程是否存在失误。
考虑将销售情况明细表整体导出,这样至少有一份原始数据表作为统计依据。同时,尽量减少在筛选器中人工勾选部分条件的动作,因为这也是难以被记录的。另外,最好能将统计结果集中显示,而不是经过多次筛选、求和的操作后,再人工汇总结果。
(2)筛选条件能较复杂。
除了简单地按照项目或按日期统计以外,还能区分不同产品业态类别、来访渠道等;按业务进度,区分意向认购、正式签约和实际回款;按不同阶段的时间,区分本期销售本期回款、往期销售往期回款;等等。另外,同一字段内,可能因为文本格式不规范,多个值可能代表一类统计单位,因而需要分组汇总后再进行相应的统计。
之所以要分得这么细,是因为业务模式比较复杂,同一笔成交,涉及到多方、多层面的参与,为此需要统计不同筛选条件下的成交额。尽管筛选条件复杂,这类统计分析业务的本质是 条件求和 ,根据不同的筛选条件,对某一指标或某些指标进行求和运算。
另外,在条件求和的基础上还可以有更复杂和深入的统计分析操作,例如比较同期增长率、价格的稳定性和波动性、产品与客户的相关性或匹配程度等。
(3)尽量不动原数据表。
尊重原始数据结果,不人工改动原始数据,并防止操作过程中不小心改动原始数据。为此,不在原始数据表上进行操作,而是将原始数据表作为 查询链接 ,只提取需要的字段/内容进行操作。
另外,原始数据表的格式须比较规范,符合数据库的三范式(列的原子性、主键的唯一性且不存在传递依赖)。关于什么是“一张格式规范的表”,可以参考一些词条“关系型数据库”、“数据库三范式”等。一个基本的特点是没有合并单元格。通常合并单元格用于阅读型表格,优点是表格的统计结果能够更加直观地呈现,界面简洁便于查阅,但它不便于数据统计的操作。
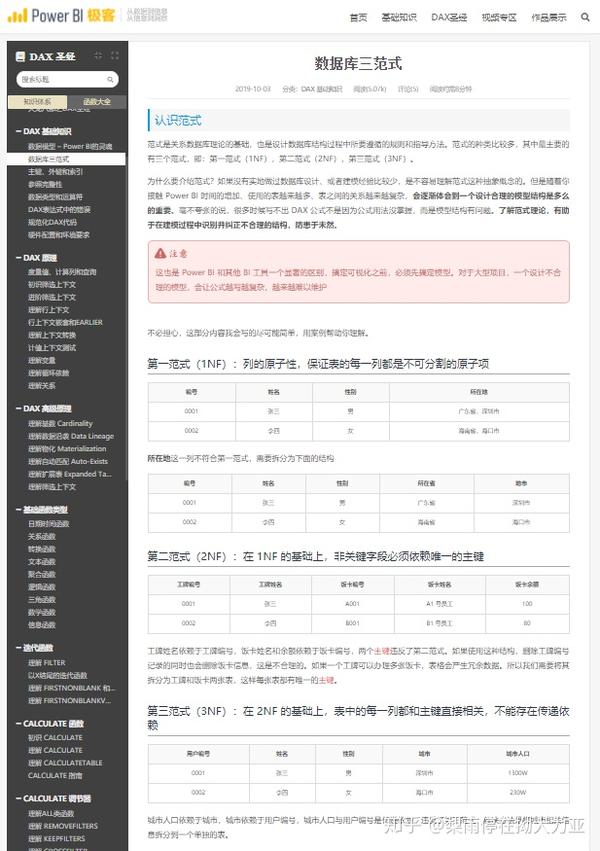

2、操作方法:
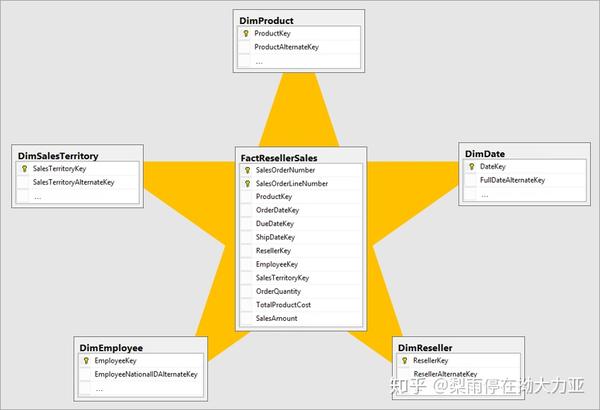
(1)建立关系型数据库: 在PowerBI中导入原始数据表,以及各维度表,通过唯一的主键将各表联系起来。
首先, 导入数据 Excel表。数据导入PowerBI之前可以选择先在 PowerQuery 中进行基本的数据处理。这是非常重要的,因为这个操作可以帮助减少数据处理量。数据处理操作包括选择需要用到的列、插入合并列、删除头几行、删除重复行等,还可以通过合并查询、追加查询来关联其他表,类似Excel中的Vlookup查询。
现在数据已经导入PowerBI中了。然后,可以在 关系模型 中先检查各表是否已经自动建立了主键之间的关系。这个也是非常重要的,否则设计的度量值将无法实现想要的统计。比较好用的关系模型有星型模型。

(2)建立度量值: 根据统计需求建立度量值,使用DAX语言编写度量值公式。这类似在Excel中插入某个计算列或者某个求和公式,但有本质的区别。
引用Power BI极客对度量值的解释:
度量值(Measure) 使用的表达式通常利用 聚合函数 (如 SUM、MIN、MAX、AVERAGE 等)生成 标量结果 ,并且结果永远不会存储在模型中。 度量值的使用非常广泛,从简单的列聚合到更复杂的公式(覆盖筛选上下文和/或关系传播的公式)应有尽有。
度量值是PowerBI进行条件求和、数据统计的重要工具,也是PowerBI中的独特的概念。它不占数据内存,只有在需要的时候、被拖到面板里的时候才进行计算,且是根据不同的条件(这里有个概念是“上下文”Context,即不同的条件)进行 动态计算 。
虽然这个概念比较抽象,但编写度量值公式所用到的DAX语言,跟编写Excel公式是类似的,像SUM求和等。还有很多Excel中不涉及到的函数,它们使PowerBI能在数据统计中实现强大的功能。

(3)在面板中呈现统计结果
将需要统计的各度量值/字段/列拖动到面板中,应用不同的筛选器,呈现整体的统计结果。这样,条件求和的统计结果就可以集中显示在面板上,也可以选择导出数据结果。

参考文献:
1、Power BI极客的DAX圣经。
2、微软的DAX Reference。
3、SQLBI的DAX Guide。
4、网易云课堂的“用Excel学习PowerBI”。
5、最后是PowerBI的官网,可前往下载免费的Power BI Desktop。