


Python自动化办公:批量提取 Word中表格内容,一键写入Excel!

今天文章介绍一个实战案例,与自动化办公相关;案例思想是源于前两天帮读者做了一个 demo ,需求大致将一上百个 word 中表格内容提取出来(所有word 中表格样式一样),把提取到的内容自动存入 Excel 中
word 中表格形式如下


目前含有数个上面形式的 word 文档需要整理,目标是利用 python 自动生成下面形式 excel 表格


正式案例讲解之前,先看一下转换效果,脚本先把指定文件夹下的 doc 文件转化为 docx ,随后自动生成一个 excel 表格,表格内中即为所有 word 中的内容
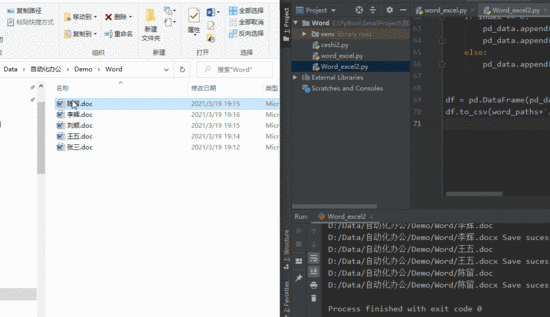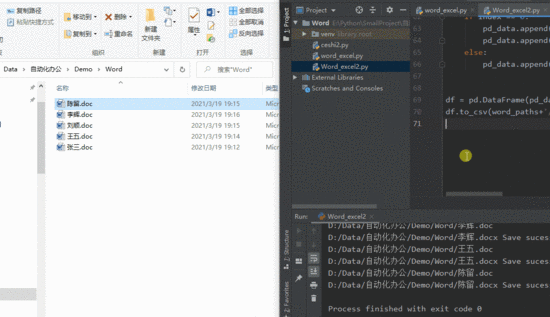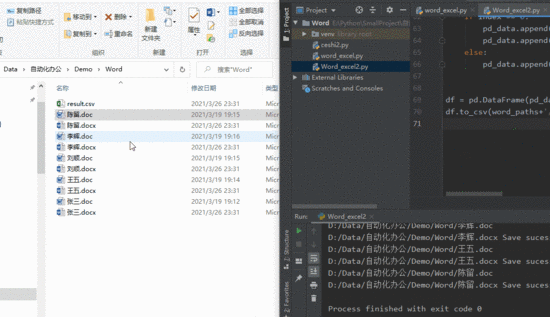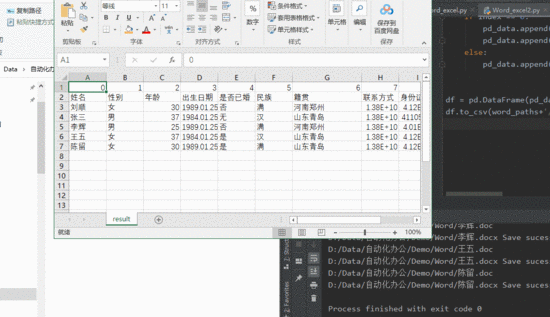

涉及的库
本案例中用到的 Python 库有以下几个
python-docx
pandas
pywin32doc 转化为 docx
本案例中 word 中表格内容的提取用到的是 python-docx 库
word 文档有时是以 doc 类型保存的, python-docx 只能处理 docx 文件类型,在提取表格内容之前,需进行一次文件类型格式转换: 把 doc 批量转化为 docx ;
doc 转 docx 最简单的方式 通过Office 中 word 组件打开 doc 文件,然后手动保存为 docx 文件,对于单个文档这个方法还行,文档数量达到上百个的话还用这种方法就有点烦了,
这里介绍一个 python 库 pywin32 来帮助我们解决这个问题,pywin32 作为扩展模块, 里面封装了大量 Windows API 函数,例如调用 Office 等应用组件、删除指定文件、获取鼠标坐标等等
利用 pywin32 控制Office 中 Word 组件自动完成 打开、保存 操作,把所有 doc 文件类型转化为 docx 文件类型,步骤分为以下三步:
1,建立一个 word 组件
from win32com import client as wc
word = wc.Dispatch('Word.Application')2,打开 word 文件
doc = word.Documents.Open(path)3,保存关闭
doc.SaveAs(save_path,12, False, "", True, "", False, False, False, False)
doc.Close()完整代码
path_list = os.listdir(path)
doc_list = [os.path.join(path,str(i)) for i in path_list if str(i).endswith('doc')]
word = wc.Dispatch('Word.Application')
print(doc_list)
for path in doc_list:
print(path)
save_path = str(path).replace('doc','docx')
doc = word.Documents.Open(path)
doc.SaveAs(save_path,12, False, "", True, "", False, False, False, False)
doc.Close()
print('{} Save sucessfully '.format(save_path))
word.Quit()docx 库提取单个表格内容
在批量操作之前,首先需要搞定单个表格中的内容,只要我们搞定了单个 word,剩下的加一个递归即可
用 docx 库对 word 中表格内容提取,主要用到 Table、rows、cells 等对象


Table 表示表格,rows 表示表格中行列表,以迭代器形式存在;cells 表示单元格列表,也是以迭代器形式
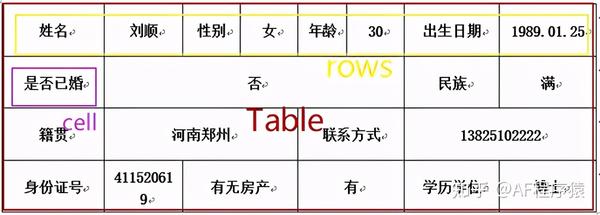

操作之前,需了解下面几个基础函数
- 通过 Document 函数读取文件路径,返回一个 Document 对象
- Document.tables 可返回 word 中的表格列表;
- table.rows 返回表格中的行列表;
- row.cells 返回该行中含有的单元格列表;
- cell.text 返回该单元格中文本信息
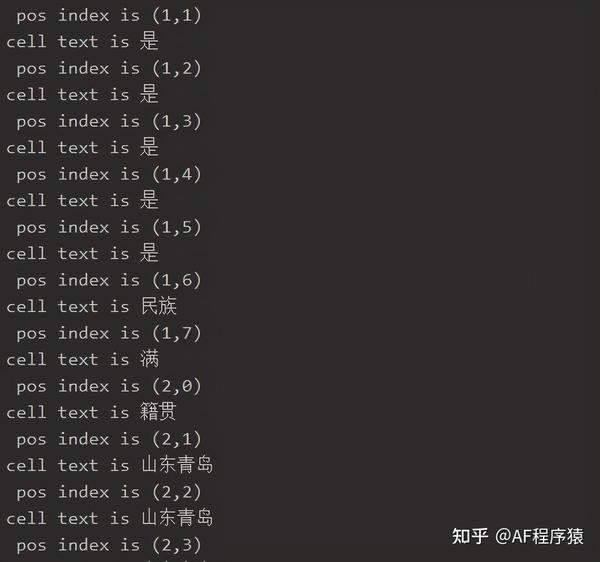
了解了上面内容之后,接下来的操作思路就比较清晰了;word 表格中文本信息可以通过两个 for 循环来完成:第一个 for 循环获取表格中所有行对象,第二个 for 循环定位每一行的单元格,借助 cell.text 获取单元格文本内容;
用代码试一下这个思路是否可行
document = docx.Document(doc_path)
for table in document.tables:
for row_index,row in enumerate(table.rows):
for col_index,cell in enumerate(row.cells):
print(' pos index is ({},{})'.format(row_index,col_index))
print('cell text is {}'.format(cell.text))会发现,最终提取到的内容是有重复的,,,

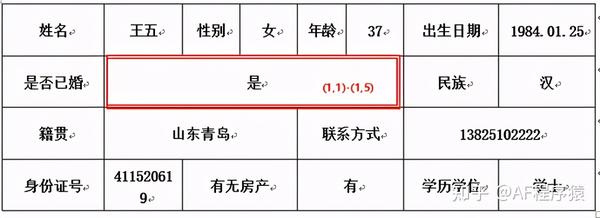
出现上面原因,是由于单元格合并问题,例如下面表格的单元格 是 合并了 (1,1)->(1,5) ,docx 库在处理这类 合并单元格 时并没有当成一个,而是以单个形式进行处理,因此 for 迭代时 (1,1)->(1,5) 单元格返回了五个,每一个单元格文本信息都返回 是

面对以上文本重复问题,需要添加一个去重机制, 姓名、性别、年龄...学历学位 等字段作为列名 col_keys,后面 王五、女、37、... 学士 等作为col_values,提取时设定一个索引,偶数为 col_keys, 奇数为 col_vaues ;
代码重构后如下:
document = docx.Document(doc_path)
col_keys = [] # 获取列名
col_values = [] # 获取列值
index_num = 0
# 添加一个去重机制
fore_str = ''
for table in document.tables:
for row_index,row in enumerate(table.rows):
for col_index,cell in enumerate(row.cells):
if fore_str != cell.text:
if index_num % 2==0:
col_keys.append(cell.text)
else:
col_values.append(cell.text)
fore_str = cell.text
index_num +=1
print(f'col keys is {col_keys}')
print(f'col values is {col_values}')最终提取后的效果如下


批量 word 提取,保存至 csv 文件中
能够处理单个 word 文件之后,一个递归即可提取到所有 word 文本表格内容,最后利用 pandas 把获取到的数据写入到 csv 文件即可!
def GetData_frompath(doc_path):
document = docx.Document(doc_path)
col_keys = [] # 获取列名
col_values = [] # 获取列值
index_num = 0
# 添加一个去重机制
fore_str = ''
for table in document.tables:
for row_index,row in enumerate(table.rows):
for col_index,cell in enumerate(row.cells):
if fore_str != cell.text:
if index_num % 2==0:
col_keys.append(cell.text)
else:
col_values.append(cell.text)
fore_str = cell.text
index_num +=1
return col_keys,col_values
pd_data = []
for index,single_path in enumerate(wordlist_path):
col_names,col_values = GetData_frompath(single_path)
if index == 0:
pd_data.append(col_names)
pd_data.append(col_values)