|
|
|



618 个回答

get新技能,学习写爬虫?!


1、为啥学爬虫?
看到一个帖子,有人用python爬虫在京东抢口罩,实现实时监测、实时抢购。
可以说很调皮了~
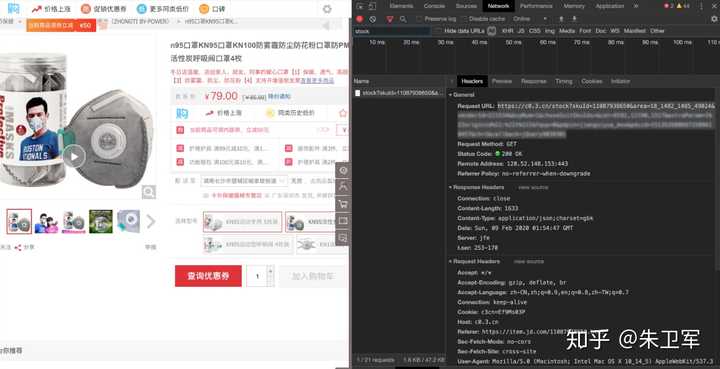


这是爬虫在电商领域的一个小应用,除此之外你还能使用爬虫进行: 商品抓取、价格监控、评论抓取、竞品分析、动态定价 等等。
其他领域,你可以使用爬虫做: 房源监控分析、网络舆情监测、精准客户获取、新闻资讯筛选、地信数据抓取、金融股票分析 等等。
这些对于从事相关行业的分析人员还是很有学习意义的。
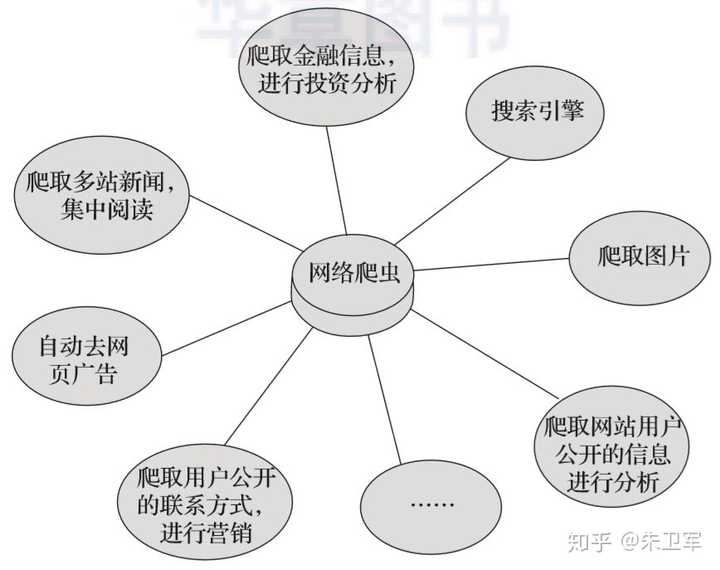

当然你还可以用爬虫搞一下骚操作: 知乎妹子高清图片、言情小说、b站学习视频、豆瓣电影书籍、抖音美女视频...... 这些都可以爬下来收藏。[逃


之前一直很火的用python登录12306抢票,也是爬虫的杰作,不过现在越来越难了,各种反爬设置。大家有兴趣可以去github上看一下这个项目开源代码,。
知乎上有个回答,我觉得还是用爬虫做了很多有意义的实事:
学爬虫当然离不开python,所以这10天你还能get python编程,当今最火的AI编程语言。
当然你也可以用集成好的第三方软件来爬,像八爪鱼、后羿之类的,但我还是建议用python来写爬虫,能学到更多东西。
2、什么是爬虫?
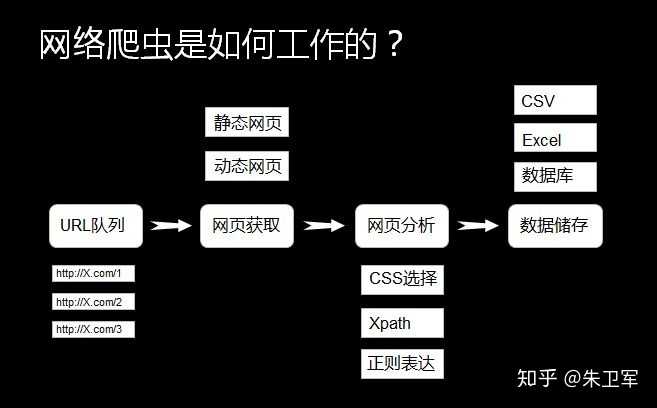
爬虫是一个形象的叫法,网络爬虫其实是网络数据采集,针对性地用代码实现网络上各种数据(文字、图片、视频)的抓取。我们熟知的谷歌、百度等搜索引擎,也是使用的爬虫技术。
通俗点说,爬虫就像是一个穿梭于网络世界的智能蜘蛛,你给它一个网址(url),然后设定规则,它就能突破重重险阻,把你想要的数据抓取下来,然后保存。

能实现爬虫的语言有很多,像Java、PHP、Python、C#...都可以用各种方式达到你的要求,那为什么要用python呢?
人生苦短,python当歌!
python是一门高级编程语言,语法简介,十分适合初学者。因此拥有了超级强大的开发社区,捣鼓出各种神奇的第三方库,比如requests、beautifulsoup、scrapy、xpath、selenium等,都是爬虫界的利器。
当然网络爬虫有利有弊,你可以爬人家的数据,但也要承担可能存在的法律风险。慎重!
我的专栏有一些爬虫介绍和python学习教程:
3、python爬虫有些学习资源?
本来想先简单介绍一下如何学习python爬虫,但还是先把学习资源讲一讲,毕竟好多资源控 ̄□ ̄
对于小白来说,首先是学习python语法。
python学习家族有三个派别:视频派、教程派、书籍派。
当然作为编程语言,一定逃不过学与练的结合,给大家推荐一个免费的在线编程网站,python的内容从入门到进阶都包含,感兴趣的可以尝试下

喜欢看视频的就去b站吧,python视频教学相当丰富,选择播放量前几名的系统学习下,听说小甲鱼的就还不错。

当然有钱的你,可以选择一些网上课程,像腾讯课堂、网易云课堂里面的课。
不要问为什么,花钱买心安。比如我猜大方的你,会打赏这篇回答[hah
教程派的选择很多了,像菜鸟教程、w3cschool、廖雪峰、python官档...
推荐大家先看菜鸟教程、再看廖雪峰,官档随时查询。


如果想少走弯路,不妨看看一些视频课程。自制力比较差的小伙伴,跟着老师把python基础走一遍,效率非常高。
现在市面上好多新出现的python课程,甚至原来做英语的也开始出python产品了,比如百词斩的夜曲编程。我觉得这其实是件好事,说 明学 Python的人越来越多,大家的选择更多元了。
夜曲编程更多面向纯小白,通过图文的形式将编程语法形象化,增加了很多互动学习的机制,比如卡片、闯关、隐喻、奖励等,你在手机、电脑、 Pad端 都可以学习,不受设备限制。

而且夜曲里面的课程设置,基本是以实操训练为主,有基础语法、数据分析、爬虫、自动办公等等,还比较符合实用的需求。这有点类似国外的 datacamp ,实践性很强。
我仔细看了里面一个Python入门课Pro,好像是有30天基础语法课,加上编程案例实战,同时还有百题斩最擅长的100题闯关。在学习过程中,还可以通过社群提问进行问题答疑,有专门的老师在群里。

如果你是纯小白,那可以试试夜曲的Python基础体验课程,总共6节,还有7天社群共学+助教答疑服务,和13道百题斩练习(代码实操练习题),学习完一般可以入门了。
现在都流行非IDE编程,夜曲的网站和app内嵌了代码编辑器,可以直接在网页或手机上敲代码并运行,对小白很友好,当然我还是建议大家有能力自己装IDE写代码。
大家可以去试试看,对照的语法书来学,应该很快可以入门。
再推荐几个可能会用到的python学习资源:
- Python简明教程(Python3)
- Python3.7.4官方中文文档
- Python标准库中文版
- 廖雪峰 Python 3 中文教程
- Python 3.3 官方教程中文版
- Python3 Cookbook 中文版
- 笨办法学 Python ( PDF EPUB )
- 《Think Python 2e》最新版中文
- Python 核心编程 第二版 中文
- 菜鸟教程 Python3基础
- W3cschool Python3基础
- Python最佳实践指南
- Python 精要教程
- Python进阶 中文版
- 中文 Python 笔记
- 莫烦python教程
- The Hitchhiker's Guide to Python
- 草根学 Python
- Kaggle Python基础学习(英文)
- 李笑来-自学是门手艺-python教程
对于书籍派来说,买一本扎实的python语法书,确实是必须的。
我之前用过的像《python编程 从入门到实践》、《笨方法学python3》,都是适合初学者看的。


爬虫的学习资源也非常多。
像崔庆才大佬的网站、b站视频、官方文档、爬虫教材等,下面给大家参考:
- awesome-spider 爬虫集合
- python模拟登陆&爬虫
- Python爬虫代理IP池(proxy pool)
- Python入门网络爬虫之精华版
- Python3网络爬虫实战
- 有趣的Python爬虫和Python数据分析小项目
- Python入门爬虫
- Requests 英文文档
- Requests 中文文档
- Scrapy 英文文档
- Scrapy 中文文档
- Pyspider 英文文档
- BeautifulSoup中文文档
- BeautifulSoup英文文档
- Xpath教程
- 崔庆才网站
还有一本python爬虫书也是很不错的,适合入门。

4、如何入门python爬虫?
终于讲到入门实操了,之前我写过一个爬虫入门回答,这里搬运过来。
以下正文:
本文针对初学者,我会用最简单的案例告诉你如何入门python爬虫!
想要 入门Python 爬虫 首先需要解决四个问题
- 熟悉python编程
- 了解HTML
- 了解网络爬虫的基本原理
- 学习使用python爬虫库
一、你应该知道什么是爬虫?
网络爬虫,其实叫作 网络数据采集 更容易理解。
就是 通过编程向网络服务器请求数据(HTML表单),然后解析HTML,提取出自己想要的数据。
归纳为四大步:
- 根据url获取HTML数据
- 解析HTML,获取目标信息
- 存储数据
- 重复第一步
这会涉及到数据库、网络服务器、HTTP协议、HTML、数据科学、网络安全、图像处理等非常多的内容。但对于初学者而言,并不需要掌握这么多。
二、python要学习到什么程度
如果你不懂python,那么需要先学习python这门非常easy的语言(相对其它语言而言)。
编程语言基础语法无非是数据类型、数据结构、运算符、逻辑结构、函数、文件IO、错误处理这些,学起来会显枯燥但并不难。
刚开始入门爬虫,你甚至不需要去学习python的类、多线程、模块之类的略难内容。找一个面向初学者的教材或者网络教程,花个十几天功夫,就能对python基础有个三四分的认识了,这时候你可以玩玩爬虫喽!
当然,前提是你必须在这十几天里认真敲代码,反复咀嚼语法逻辑,比如列表、字典、字符串、if语句、for循环等最核心的东西都得捻熟于心、于手。
教材方面比较多选择,我个人是比较推荐 python官方文档 以及 python简明教程 ,前者比较系统丰富、后者会更简练。
三、为什么要懂HTML
前面说到过爬虫要爬取的数据藏在网页里面的HTML里面的数据,有点绕哈!
维基百科是这样解释HTML的
超文本标记语言 (英语: H yper T ext M arkup L anguage,简称: HTML )是一种用于创建 网页 的标准 标记语言 。HTML是一种基础技术,常与 CSS 、 JavaScript 一起被众多网站用于设计网页、网页应用程序以及移动应用程序的用户界面 [3] 。 网页浏览器 可以读取HTML文件,并将其渲染成可视化网页。HTML描述了一个网站的结构语义随着线索的呈现,使之成为一种标记语言而非 编程语言 。
总结一下,HTML是一种用于创建网页的标记语言,里面嵌入了文本、图像等数据,可以被浏览器读取,并渲染成我们看到的网页样子。
所以我们才会从先爬取HTML,再 解析数据,因为数据藏在HTML里。
学习HTML并不难,它并不是编程语言,你只需要熟悉它的标记规则,这里大致讲一下。
HTML标记包含标签(及其属性)、基于字符的数据类型、字符引用和实体引用等几个关键部分。
HTML标签是最常见的,通常成对出现,比如
<
h1
>
与
</
h1
>
。
这些成对出现的标签中,第一个标签是开始标签,第二个标签是结束标签。两个标签之间为元素的内容(文本、图像等),有些标签没有内容,为空元素,如
<
img
>
。
以下是一个经典的 Hello World 程序的例子:
<!DOCTYPE html>
<title>This is a title</title>
</head>
<p>Hello world!</p>
</body>
</html>
HTML文档由嵌套的HTML元素构成。它们用HTML标签表示,包含于尖括号中,如
<
p
>
[56]
在一般情况下,一个元素由一对标签表示:“开始标签”
<
p
>
与“结束标签”
</
p
>
。元素如果含有文本内容,就被放置在这些标签之间。
四、了解python网络爬虫的基本原理
在编写python爬虫程序时,只需要做以下两件事:
- 发送GET请求,获取HTML
- 解析HTML,获取数据
这两件事,python都有相应的库帮你去做,你只需要知道如何去用它们就可以了。
五、用python库爬取百度首页标题和图片
首先,发送HTML数据请求可以使用python内置库urllib,该库有一个urlopen函数,可以根据url获取HTML文件,这里尝试获取百度首页“ https://www. baidu.com/ ”的HTML内容
# 导入urllib库的urlopen函数
from urllib.request import urlopen
# 发出请求,获取html
html = urlopen("https://www.baidu.com/")
# 获取的html内容是字节,将其转化为字符串
html_text = bytes.decode(html.read())
# 打印html内容
print(html_text)看看效果:
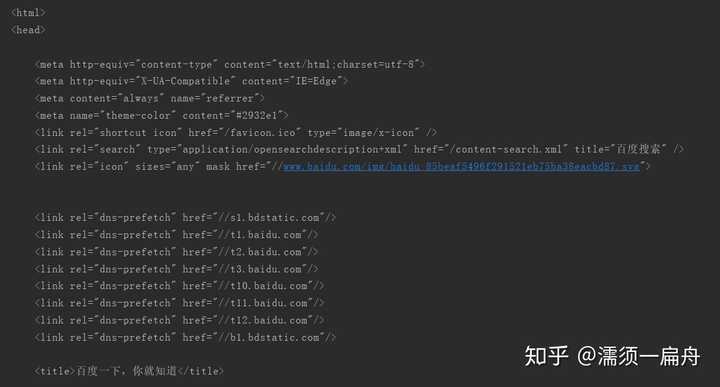

我们看一下真正百度首页html是什么样的,如果你用的是谷歌浏览器,在百度主页打开设置>更多工具>开发者工具,点击element,就可以看到了:
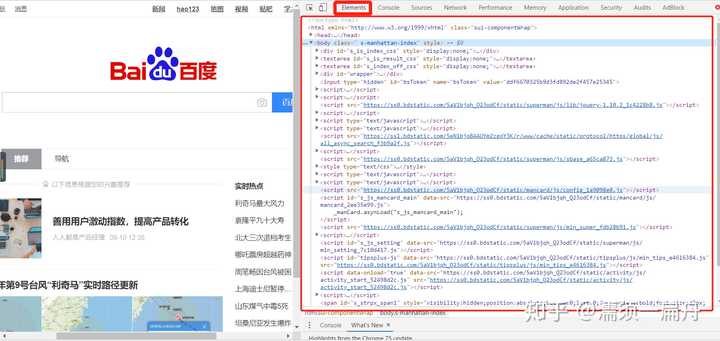

对比一下你就会知道,刚才通过python程序获取到的HTML和网页中的一样!
获取了HTML之后,接下就要解析HTML了,因为你想要的文本、图片、视频都藏在HTML里,你需要通过某种手段提取需要的数据。
python同样提供了非常多且强大的库来帮助你解析HTML,这里以著名的python库 BeautifulSoup 为工具来解析上面已经获取的HTML。
BeautifulSoup是第三方库,需要安装使用。在命令行用pip安装就可以了:
pip install bs4BeautifulSoup会将HTML内容转换成结构化内容,你只要从结构化标签里面提取数据就OK了:


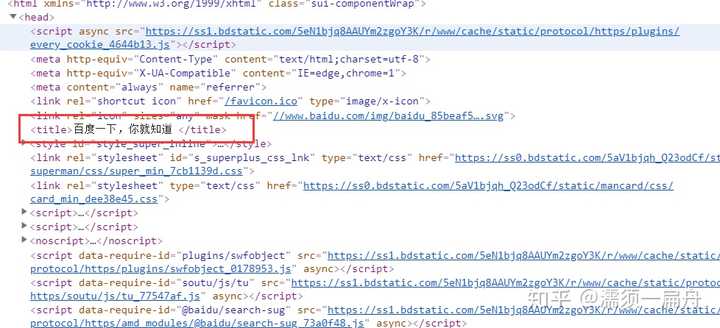
比如,我想获取百度首页的标题“百度一下,我就知道”,怎么办呢?
这个标题是被两个标签套住的,一个是一级标签<head><head>,另一个是二级标签<title><title>,所以只要从标签中取出信息就可以了

# 导入urlopen函数
from urllib.request import urlopen
# 导入BeautifulSoup
from bs4 import BeautifulSoup as bf
# 请求获取HTML
html = urlopen("https://www.baidu.com/")
# 用BeautifulSoup解析html
obj = bf(html.read(),'html.parser')
# 从标签head、title里提取标题
title = obj.head.title
# 打印标题
print(title)看看结果:


这样就搞定了,成功提取出百度首页的标题。
如果我想要下载百度首页logo图片呢?
第一步先获取该网页所有图片标签和url,这个可以使用BeautifulSoup的findAll方法,它可以提取包含在标签里的信息。
一般来说,HTML里所有图片信息会在“img”标签里,所以我们通过findAll("img")就可以获取到所有图片的信息了。
# 导入urlopen
from urllib.request import urlopen
# 导入BeautifulSoup
from bs4 import BeautifulSoup as bf
# 请求获取HTML
html = urlopen("https://www.baidu.com/")
# 用BeautifulSoup解析html
obj = bf(html.read(),'html.parser')
# 从标签head、title里提取标题
title = obj.head.title
# 使用find_all函数获取所有图片的信息
pic_info = obj.find_all('img')
# 分别打印每个图片的信息
for i in pic_info:
print(i)看看结果:
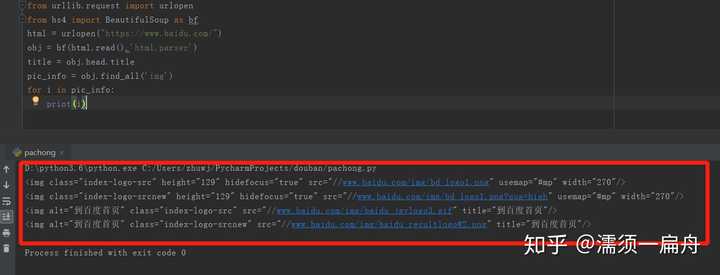

打印出了所有图片的属性,包括class(元素类名)、src(链接地址)、长宽高等。
其中有百度首页logo的图片,该图片的class(元素类名)是index-logo-src。


[<img class="index-logo-src" height="129" hidefocus="true" src="//www.baidu.com/img/bd_logo1.png" usemap="#mp" width="270"/>, <img alt="到百度首页" class="index-logo-src" src="//www.baidu.com/img/baidu_jgylogo3.gif" title="到百度首页"/>]可以看到图片的链接地址在src这个属性里,我们要获取图片链接地址:
# 导入urlopen
from urllib.request import urlopen
# 导入BeautifulSoup
from bs4 import BeautifulSoup as bf
# 请求获取HTML
html = urlopen("https://www.baidu.com/")
# 用BeautifulSoup解析html
obj = bf(html.read(),'html.parser')
# 从标签head、title里提取标题
title = obj.head.title
# 只提取logo图片的信息
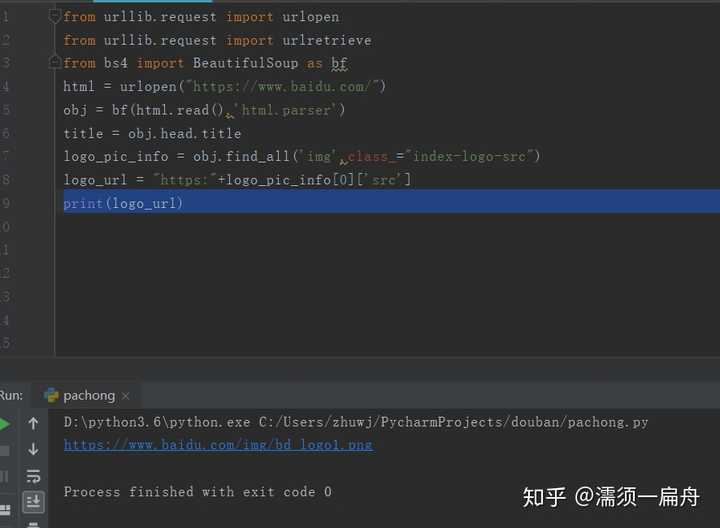
logo_pic_info = obj.find_all('img',class_="index-logo-src")
# 提取logo图片的链接
logo_url = "https:"+logo_pic_info[0]['src']
# 打印链接
print(logo_url)结果:

获取地址后,就可以用urllib.urlretrieve函数下载logo图片了
# 导入urlopen
from urllib.request import urlopen
# 导入BeautifulSoup
from bs4 import BeautifulSoup as bf
# 导入urlretrieve函数,用于下载图片
from urllib.request import urlretrieve
# 请求获取HTML
html = urlopen("https://www.baidu.com/")
# 用BeautifulSoup解析html
obj = bf(html.read(),'html.parser')
# 从标签head、title里提取标题
title = obj.head.title