


机器学习中常见散度距离

[TOC]
本文对比了常见散度(KL散度,JS散度)和常见距离(尤其是现在很火的Wasserstein距离)
F-散度
散度是用来衡量两个概率密度p,q区别的函数,即:两个分布的相似程度.
D _ { f } ( p \| q ) = \int q ( x ) f \left( \frac { p ( x ) } { q ( x ) } \right) d x
这里的 f 需要满足2个条件: f 是凸函数且 f(1)=0 .
可以证明:
因为 f 是凸函数,由Jensen不等式可知 E(f(x)) >= f(E(x))
D _ { f } ( p \| q ) = \int q ( x ) f \left( \frac { p ( x ) } { q ( x ) } \right) d x \geq f \left( \int q ( x ) \frac { p ( x ) } { q ( x ) } d x \right) = f ( 1 ) = 0
KL散度
KL散度是F-散度的一个特例,当 f(x)=xlogx 的时候:
D _ { KL} ( p \| q ) = \int p(x) \log \left( \frac { p ( x ) } { q ( x ) } \right) d x
需要注意
- KL散度非对称,即 D _ { KL} ( p \| q ) \neq D _ { KL} ( q \| p ) ,所以KL散度不是一个真正的距离或者度量.
- KL散度不满足三角不等式 D _ { KL} ( p \| q ) > D _ { KL} ( p \| r ) + D _ { KL} ( r \| q )
- KL散度取值范围从 [0, \infty] , p=q的时候,两个分布完全一样取到0
为什么KL散度大于0?


p和q的影响:
- 如果想要 D_{KL} 小,
- 那么p大的地方,q一定要大
- 那么p小的地方,q对 D_{KL} 的影响不大
- 如果想要 D_{KL} 大
- 那么p大的地方,q对 D_{KL} 影响不大
- 那么p小的地方,q一定要小
KL散度 不对称导致的问题:
- 情况1.当 p\rightarrow 0 且 q\rightarrow 1 时, p(x) \log \left( \frac { p ( x ) } { q ( x ) }\ \right) \rightarrow 0 , 对 D_{KL}(p||q) 的贡献为0
- 情况2.当 p\rightarrow 1 且 q\rightarrow 0 时, p(x) \log \left( \frac { p ( x ) } { q ( x ) }\ \right) \rightarrow +\infty , 对 D_{KL}(p||q) 的贡献为 +\infty .
- 进步一这里可以解释为什么我们通常选择正态分布而不是均匀分布.
- 均匀分布:只要两个均分分布不是完全相同,必然出现 p\neq0,q=0 的情况,导致 D_{KL}(p||q)\rightarrow +\infty .
- 正态分布:所有概率密度都是非负的,所以不会出现上述情况.
换而言之, pq之间的KL散度可能导致惩罚或者梯度差距极大.
PRML 公式10.19附近 有部分介绍
JS散度
JS散度实际就是KL散度的一个扩展,被用来推导GAN.
D _ { JS} ( p \| q ) =\frac{1}{2}D _ { KL} ( p \| \frac{p+q}{2} ) +\frac{1}{2}D _ { KL} ( q \| \frac{p+q}{2} )
需要注意
- JS散度是对称的.
- JS散度有界,范围是 [0,\log2] 这个上界不同情况,见 http:// pages.stern.nyu.edu/~db ackus/BCZ/entropy/Jensen%96Shannon-divergence-Wikipedia.pdf
KL散度和JS散度度量的时候有一个问题:
如果两个分配P,Q离得很远,完全没有重叠的时候,那么KL散度值是没有意义的,而JS散度值是一个常数。这在学习算法中是比较致命的,这就意味这这一点的梯度为0。梯度消失了。
Renyi
\alpha -散度
D _ { \alpha} ( p \| q ) = \frac{1}{\alpha(\alpha-1)}\log \bigg( \int \frac { p ( x ) ^{\alpha}} { q ( x )^{\alpha-1} } d x \bigg)
当 \alpha \rightarrow 0或1 时,可以得到KL散度或者reverse KL散度.
只有当 \alpha=0.5 的时候对称.
互信息 Mutual Information
互信息, 很难计算.
I ( X ; Y ) = \int _ { Y } \int _ { X } p ( x , y ) \log \left( \frac { p ( x , y ) } { p ( x ) p ( y ) } \right) d x d y \\\
I ( X ; Y ) = \sum _ { y \in Y } \sum _ { x \in X } p ( x , y ) \log \left( \frac { p ( x , y ) } { p ( x ) p ( y ) } \right)
对比互信息和KL散度的公式,可以得到
I ( X ; Y ) = D_{KL}\bigg(p(x,y)||p(x)p(y)\bigg)
此外,令 p(x|y)=\frac{p(x,y)}{p(y)} , 则
\mathrm { I } ( X ; Y ) \\ = \sum _ { y } p ( y ) \sum _ { x } p ( x | y ) \log _ { 2 } \frac { p ( x | y ) } { p ( x ) } \\ = \sum _ { y } p ( y ) D _ { \mathrm { KL } } ( p ( x | y ) \| p ( x ) ) \\ = \mathbb { E } _ { Y } \left[ D _ { \mathrm { KL } } ( p ( x | y ) \| p ( x ) ) \right]
距离
一个真正的距离或者度量要满足3个条件:
- 正定性: 若 x \neq y , d(x,y)>0, d(x,x)=0
-
对称性:
d(x,y ) = d(y, x)
-
三角不等式:
d(x, y) \le d(x,z) + d(z, y)
欧式距离
假设从 同一分布 中采样得到两组测量分别为 \mathbf{x}=\left(x_{1}, x_{2}, x_{3}, \dots, x_{p}\right)^{T} 和 \mathbf{y}=\left(y_{1}, y_{2}, y_{3}, \dots, y_{p}\right)^{T} ,那么他们之间的欧式距离为
D_{E}(x, y)=\sqrt{(x_i-y_i)^{2} +....+(x_p-y_p)^{2}} \\ =\sqrt{(x-y)^{T} \mathbf{I}(x-y)}
这里, \mathbf{I} 是单位对角矩阵。可以看出: 欧氏距离假设测量的不同维度之间是独立的。
这在很多情况都是不合理,例如 x_1代表身高,x_2代表体重,实际这两个 不同维度的特性是有关联的 ,同时他们的 尺度也不相同 (身高变化10cm和体重变化10kg的意义完全不同)。
为了克服上述的两个问题,就有了马氏距离 Mahalanobis Distance。
马氏距离 Mahalanobis Distance
与欧氏距离不同的是,马氏距离考虑到各种特性之间的联系(例如:一条关于身高的信息会带来一条关于体重的信息,因为两者是有关联的)并且是尺度无关的(scale-invariant),即独立于测量尺度。
D_{M}(x, y)=\sqrt{(x-y)^{T} \Sigma^{-1}(x-y)}
其中, \Sigma 是多维随机变量的协方差矩阵。
更多解释见 https://www. ph0en1x.space/2018/04/1 8/Mahalanobis/
https:// blog.csdn.net/qq_280382 07/article/details/81006453
TV距离
里还证明了 EBGAN 的 loss 是在 minimize TV 距离,而 TV 距离与 JS 是等价的(事实上 KL > TV = JS > EM )
Wasserstein距离
定义为
W _ { p } ( \mu , \nu ) : = \left( \begin{array} { c } { \inf } \\ { \gamma \in \Gamma ( \mu , \nu ) } \end{array} \int _ { M \times M } d ( x , y ) ^ { p } \mathrm { d } \gamma ( x , y ) \right)^{1/p}
W _ { p } ( \mu , \nu ) ^ { p } = \inf \mathbf { E } \left[ d ( X , Y ) ^ { p } \right]
这里 \Gamma ( \mu , \nu ) 是 \mu , \nu 分布组合起来的 所有的可能的联合分布 的集合, (x,y) 代表从 \gamma 中进行采样出一对样本. 针对这对样本,从x搬移到y处所需要的距离就是 d(x,y) . 加上期望就代表,把所有 \mu 搬移到 \nu 所需要的距离.
Wasserstein距离满足距离的三个要求.
可以证明其满足三角不等式
W _ { p } ( \mu , \nu ) \leq \left( \int | x - z | ^ { p } d \gamma \right) ^ { 1 / p } = \left( \int | x - z | ^ { p } d \sigma \right) ^ { 1 / p } = \| x - z \| _ { L ^ { p } ( \sigma ) } \\\ \leq \| x - y \| _ { L ^ { p } ( \sigma ) } + \| y - z \| _ { L ^ { p } ( \sigma ) } = \left( \int | x - z | ^ { p } d \sigma \right) ^ { 1 / p } + \left( \int | x - z | ^ { p } d \sigma \right) ^ { 1 / p } \\\ = \left( \int | x - z | ^ { p } d \gamma ^ { + } \right) ^ { 1 / p } + \left( \int | x - z | ^ { p } d \gamma ^ { - } \right) ^ { 1 / p } = W _ { p } ( \mu , \rho ) + W _ { p } ( \rho , \nu )
Wessertein距离相比KL散度和JS散度的 优势 在于:即使两个分布的支撑集没有重叠或者重叠非常少,仍然能反映两个分布的远近。而JS散度在此情况下是常量,KL散度可能无意义. (6)中的 W _ { p } ( \mu , \nu ) ^ { p } 又叫 W_p 距离, 这样就会有 W_1 距离和 W_2 距离
W_1 距离(EMD距离)
TODO
W_2 距离
W_p 距离的求解是非常麻烦的,但是在某种情况下求解很方便.
针对 两个高斯分布 , W_2 距离有 闭式解 (线性时间求解):
d i s t = W _ { 2 } \left( \mathcal { N } \left( \mu _ { 1 } , \Sigma _ { 1 } \right) , \mathcal { N } \left( \mu _ { 2 } , \Sigma _ { 2 } \right) \right) \\\ d i s t ^ { 2 } = \left\| \mu _ { 1 } - \mu _ { 2 } \right\| _ { 2 } ^ { 2 } + \operatorname { Tr } \left( \Sigma _ { 1 } + \Sigma _ { 2 } - 2 \left( \Sigma _ { 1 } ^ { 1 / 2 } \Sigma _ { 2 } \Sigma _ { 1 } ^ { 1 / 2 } \right) ^ { 1 / 2 } \right)
如果这两个高斯分布的方差矩阵为对角矩阵,即 \Sigma _ { 1 } \Sigma _ { 2 } = \Sigma _ { 2 } \Sigma _ { 1 } ,上式可以进一步简化.
W _ { 2 } \left( \mathcal { N } \left( \mu _ { 1 } , \Sigma _ { 1 } \right) ; \boldsymbol { N } \left( m _ { 2 } , \Sigma _ { 2 } \right) \right) ^ { 2 } = \left\| \mu _ { 1 } - \mu _ { 2 } \right\| _ { 2 } ^ { 2 } + \left\| \Sigma _ { 1 } ^ { 1 / 2 } - \Sigma _ { 2 } ^ { 1 / 2 } \right\| _ { F } ^ { 2 }
JS散度,KL散度,Wessertein距离对比
举例如下:
考虑如下二维空间中的两个分布pq,p在线段AB上均匀分布,q在线段CD上均匀分布,通过控制参数 \theta 可以控制着两个分布的距离远近。
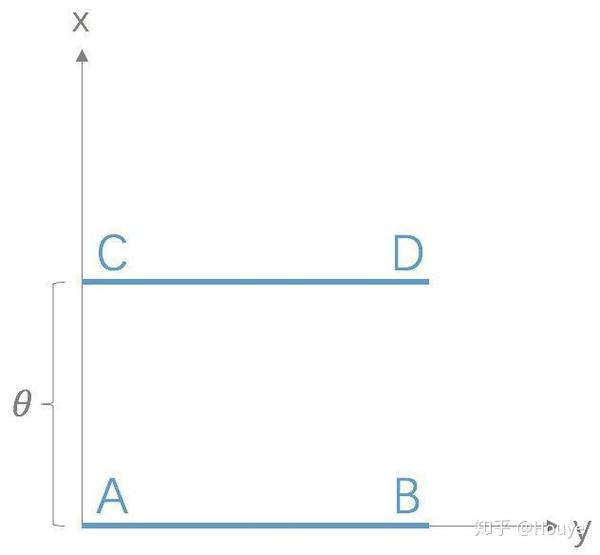

D_{KL}(p||q)=D_{KL}(q||p)= \left\{ \begin{array} { l l } { + \infty } & { \text { if } \theta \neq 0 } \\ { 0 } & { \text { if } \theta = 0 } \end{array} \right.
D_{JS}(p||q)= \left\{ \begin{array} { l l } { \log 2 } & { \text { if } \theta \neq 0 } \\ { 0 } & { \text { if } \theta = 0 } \end{array} \right.
W(p,q)=|\theta|
可以看出JS和KL都出现了突变,而W距离保持平滑
Reference
- https:// blog.csdn.net/uestc_c2_ 403/article/details/75208644
- https://www. zhihu.com/question/3987 2326/answer/83688277
- https:// zhuanlan.zhihu.com/p/25 071913
- http:// pages.stern.nyu.edu/~db ackus/BCZ/entropy/Jensen%96Shannon-divergence-Wikipedia.pdf
- The Wasserstein distances
- Optimal Transport for Applied Mathematicians
- http://www. geometry.caltech.edu/pu bs/dGBOD12.pdf
