

elasticsearch 权重及排序

一.权重是什么意思?
想要查询关于 “full-text search(全文搜索)” 的文档,但我们希望为提及 “Elasticsearch” 或 “Lucene” 的文档给予更高的
权重
,这里
更高权重
是指如果文档中出现 “Elasticsearch” 或 “Lucene” ,它们会比没有的出现这些词的文档获得更高的相关度评分
_score
,也就是说,它们会出现在结果集的更上面。

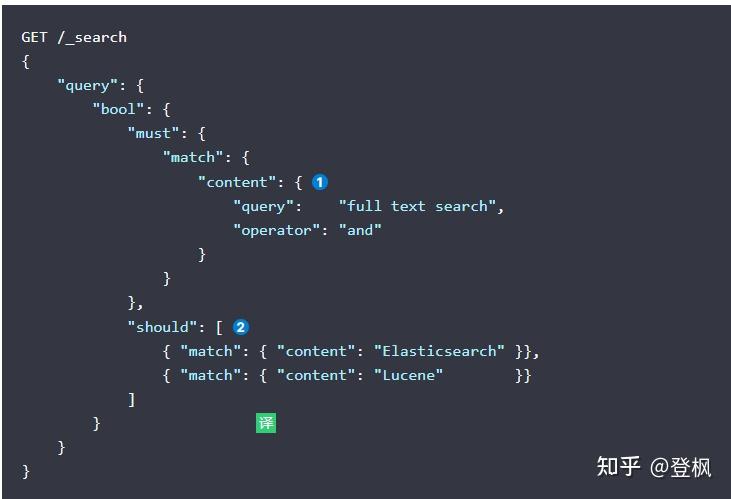
should
语句匹配得越多表示文档的相关度越高。目前为止还挺好。
但是如果我们想让包含
Lucene
的有更高的权重,并且包含
Elasticsearch
的语句比
Lucene
的权重更高,该如何处理?
我们可以通过指定
boost
来控制任何查询语句的相对的权重,
boost
的默认值为
1
,大于
1
会提升一个语句的相对权重。所以下面重写之前的查询:


注意:
boost
参数被用来提升一个语句的相对权重(
boost
值大于
1
)或降低相对权重(
boost
值处于
0
到
1
之间),但是这种提升或降低并不是线性的,换句话说,如果一个
boost
值为
2
,并不能获得两倍的评分
_score
针对索引进行权重配置
在进行多个索引组合查询时,可以针对其中的某个或者某几个设置权重,让查询结果更倾向于这几个索引里的值。
优先级问题
Lucene支持给不同的查询词设置不同的权重。设置权重使用“^”符号,将“^”放于查询词的尾部,同时跟上权重值,权重因子越大,该词越重要。
设置权重允许你通过给不同的查询词设置不同的权重来影响文档的相关性,假如你在搜索:jakarta apache 如果你认为“jakarta”在查询时中更加重要,你可以使用如下语法:jakarta^4 apache 这将使含有Jakarta的文档具有更高的相关性,同样你也可以给短语设置权重如下:"jakarta apache"^4 "jakarta lucene"
二.排序
排序与相关性有关。了解排序之前,先说下什么是相关性。
每个文档都有相关性评分,用一个正浮点数字段
_score
来表示 。
_score
的评分越高,相关性越高。
查询语句会为每个文档生成一个
_score
字段。评分的计算方式取决于查询类型 不同的查询语句用于不同的目的:
fuzzy
查询会计算与关键词的拼写相似程度,
terms
查询会计算 找到的内容与关键词组成部分匹配的百分比,但是通常我们说的
relevance
是我们用来计算全文本字段的值相对于全文本检索词相似程度的算法。
注意:使用filter(过滤)查询,只会匹配到我们希望的文档,文档也是随机返回的。每个文档的评分为零。
按照字段的值排序

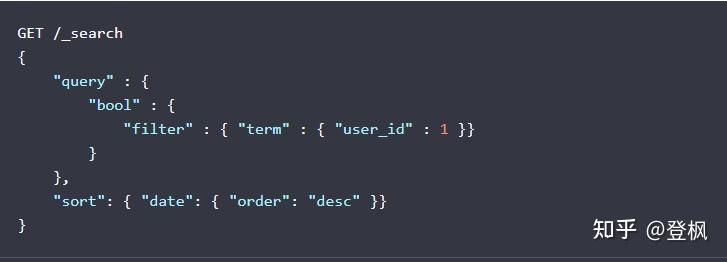

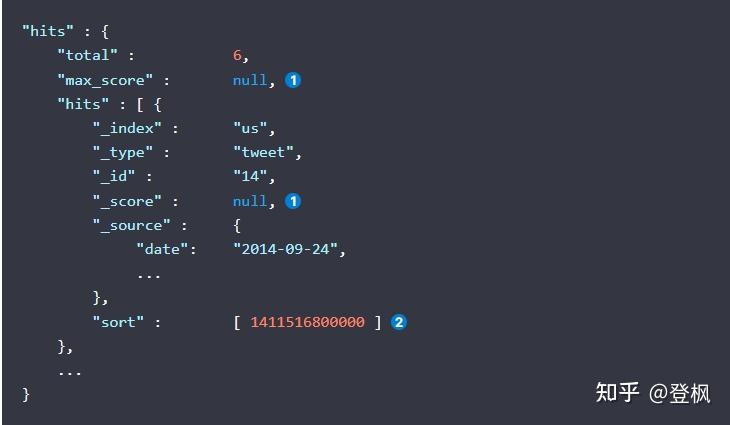
如图1对时间进行排序,
_score
不被计算, 因为它并没有用于排序,图2返回值中有个sort 它的值为
date
字段的值表示为自 epoch (January 1, 1970 00:00:00 UTC)以来的毫秒数;我们根据这个值进行排序。 按照字段的值排序将会默认升序排序,而按照
_score
的值进行降序排序。
多字段排序
对于多个排序,排序条件的顺序很重要。查询返回的结果首先按照第一个条件排序,当结果集的第一个sort值完全相同时才会按照第二个条件进行排序。
多值字段排序
注意:在这种情况中,多个值是没有固定的顺序。
对于数字或日期,你可以将多值字段减为单值,这可以通过使用
min
、
max
、
avg
或是
sum
排序模式
。 例如你可以按照每个
date
字段中的最早日期进行排序,通过以下方法
