encode encode 红色数字的变量名, gen(新产生的变量名)
- 自己尝试用这个代码之后,发现对应变量不是红色了,但变成了蓝色。我开始以为问题已经解决了,但是从实证回归的结果看,实证结果明显和既有的大部分研究不一致。而且实证结果随着控制变量的增减而变化很大,核心解释变量不仅数值变化较大,而且连方向也变了。
- 于是,一开始我怀疑是我才找的新数据可能有问题,换回以前得出预期结果的数据再跑了一遍代码,发现结果竟然和之前不一样。
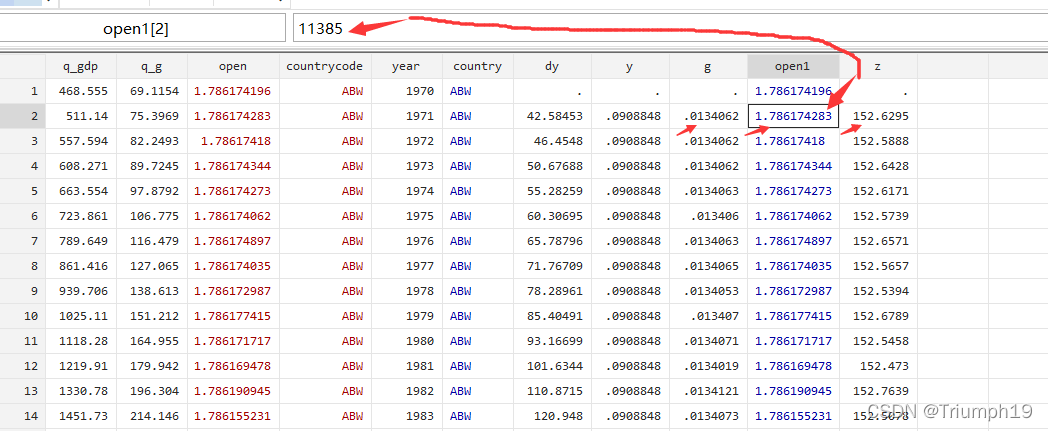
- 这时,我在看了stata数据编辑器中的数据,发现了异样,如下图所示:
- 其中z=g*open1,很明显stata计算的z值有问题;再看两个大的红色箭头,实际上是一个数据,但是在这里却变成两个不同数据。
- 我尝试这种方法之后,发现问题还是没有解决,于是我怀疑对应变量数据中有非数字。
- 结果确实如此

Sub RemoveNotNum()
'Updateby Extendoffice
Dim Rng As Range
Dim WorkRng As Range
On Error Resume Next
xTitleId = "KutoolsforExcel"
Set WorkRng = Application.Selection
Set WorkRng = Application.InputBox("Range", xTitleId, WorkRng.Address, Type:=8)
For Each Rng In WorkRng
xOut = ""
For i = 1 To Len(Rng.Value)
xTemp = Mid(Rng.Value, i, 1)
If xTemp Like "[0-9.]" Then
xStr = xTemp
xStr = ""
End If
xOut = xOut & xStr
Next i
Rng.Value = xOut
End Sub
目标:解决open变量变红的问题网上说可以通过以下代码解决(实际上是缘木求鱼)encode encode 红色数字的变量名, gen(新产生的变量名)自己尝试用这个代码之后,发现对应变量不是红色了,但变成了蓝色。我开始以为问题已经解决了,但是从实证回归的结果看,实证结果明显和既有的大部分研究不一致。而且实证结果随着控制变量的增减而变化很大,核心解释变量不仅数值变化较大,而且连方向也变了。于是,一开始我怀疑是我才找的新数据可能有问题,换回以前得出预期结果的数据再跑了一遍代码,发现结果竟然和
原始数据处理过程:
1. 剔除Tenure、Duality、Board、Insider、Manager有缺失值的样本;
2. 将Tenure、Duality、Board、Insider、Manager在1%和99%水平上进行缩尾;
3. 整体样本区间定义在1999-2018年间;
指标计算依据:
参考文献:[1]刘剑民,张莉莉,杨晓璇.政府补助、管理层权力与国有企业高管超额薪酬[J].会计研究,2019(08):64-70.
指标计算过程:
1. 选择总经理任职年限Tenure(取值为总经理在该职位上的任职年限)、两职合一Duality(是取1,否则取2)、董事会规模Board(取值为每届董事会人数)、内部董事比例Insider、管理层持股比例Manager来衡量管理层权力的来源和公司治理对管理层权力的监督约束;
2. 借鉴Fan等(2009)、卢锐等(2008) 对管理层权力的间接度量方法,按照主成分分析方法将五个指标合成管理层权力综合指标;
3. pca因子分析;
4. KMO和SMC检验
数据范围:
1999-2018年;所有原始数据来自CSMAR数据库
将数据从excel复制或导入stata中经常会遇到字体红色的情况,一般是因为数据非字符。运行destring,replace经常看到
“contains nonnumeric characters; no replace”警告
这种情况最好不要贸然运用destring加force等选项,这样可能带来数值扭曲。原本仅仅格式有问题的观测值可能被软件处理成缺失值等。
最稳妥的方法是,检验到底那些数据是nonnumeric以及其特征。
命令:tab var if regexm(var,"[^0-9.]"
1.控制变量、中介变量与调节变量
调节变量是与控制变量都是自变量。调节变量是外来的变量,非模型的一部分,只有在证明存在干扰效果的时候才会代入。控制变量是模型的一部分,主要目的是为了得到更为精确的估计。调节变量不是研究者关注的核心自变量,而是为了澄清核心自变量与因变量的关系,即:在调节变量取不同值的情况下,核心自变量与因变量的关系有何变化。 比较一下,控制变量也是为了澄清上述关系,但控制变量的终极目标是分离出核心自变量对因变量的纯影响 ...
控制变量是模型中除了自变.
使用Stata读取Excel文件中的变量数据有多种方法,其中一种简单的方法是使用`import excel`命令。下面是一个基本示例。
首先,打开Stata软件并输入以下命令:
import excel "filename.xlsx", sheet("sheetname") firstrow clear
这里,“filename.xlsx”是要读取的Excel文件的文件名,sheetname是要读取的工作表的名称。如果工作表是第一个工作表,则可以省略sheet()选项。`firstrow`选项指定第一行是否包含变量名称。
然后,Stata将读取指定的Excel文件和工作表,并将其作为新数据集导入。可以使用`describe`命令查看数据集中的变量。
例如,如果要查看数据集中的变量名称和类型,请输入以下命令:
describe
这将显示数据集中所有变量的信息。如果要查看特定变量的数据,请使用`list`或`tabulate`命令。
例如,如果要查看名为“variable1”的变量的值,请输入以下命令:
list variable1
这将显示数据集中“variable1”变量的所有值。

