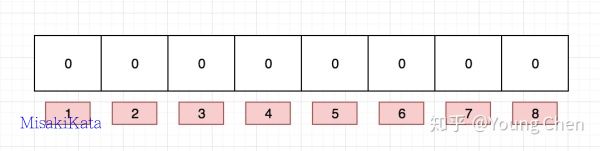
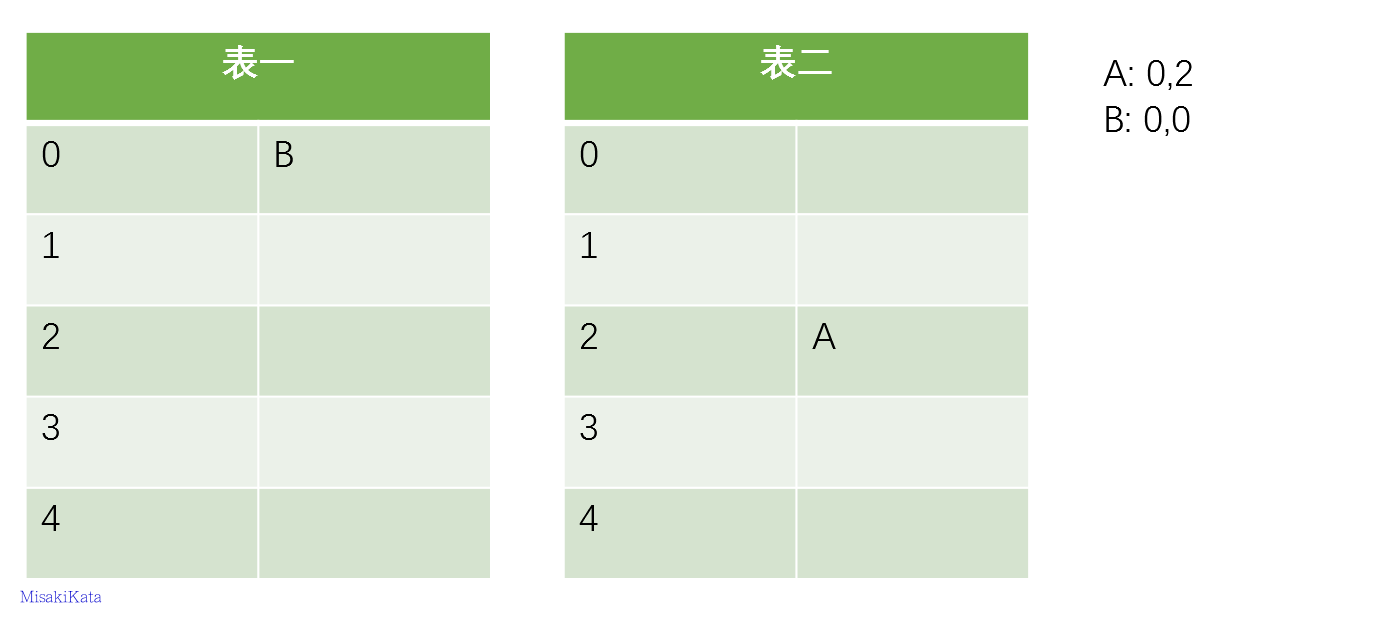
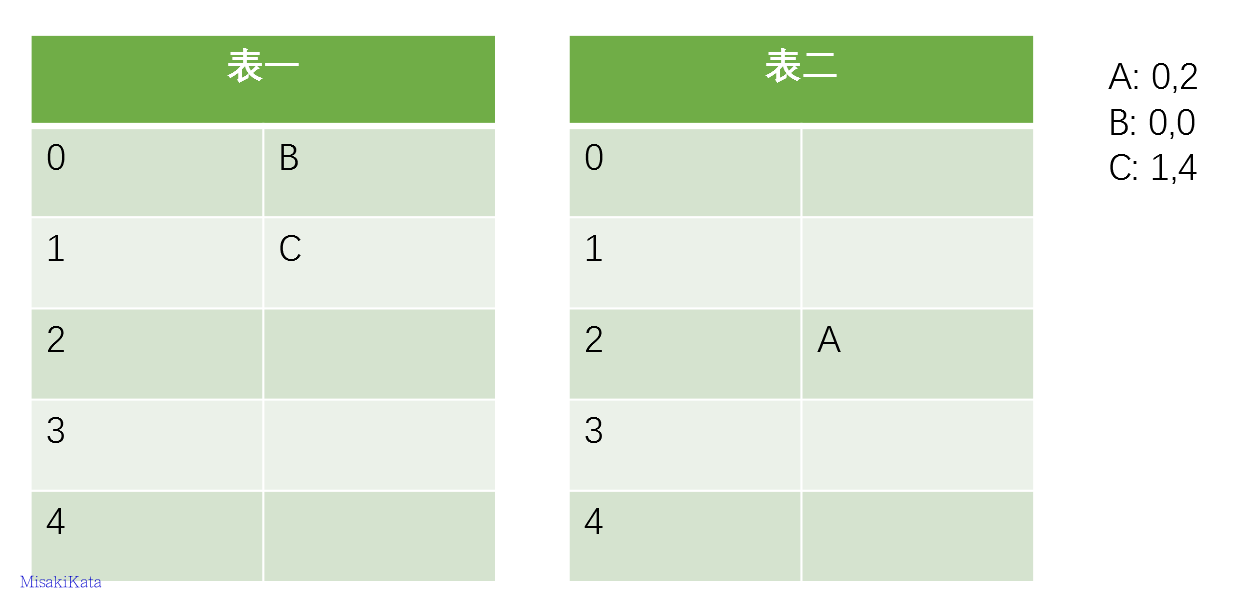
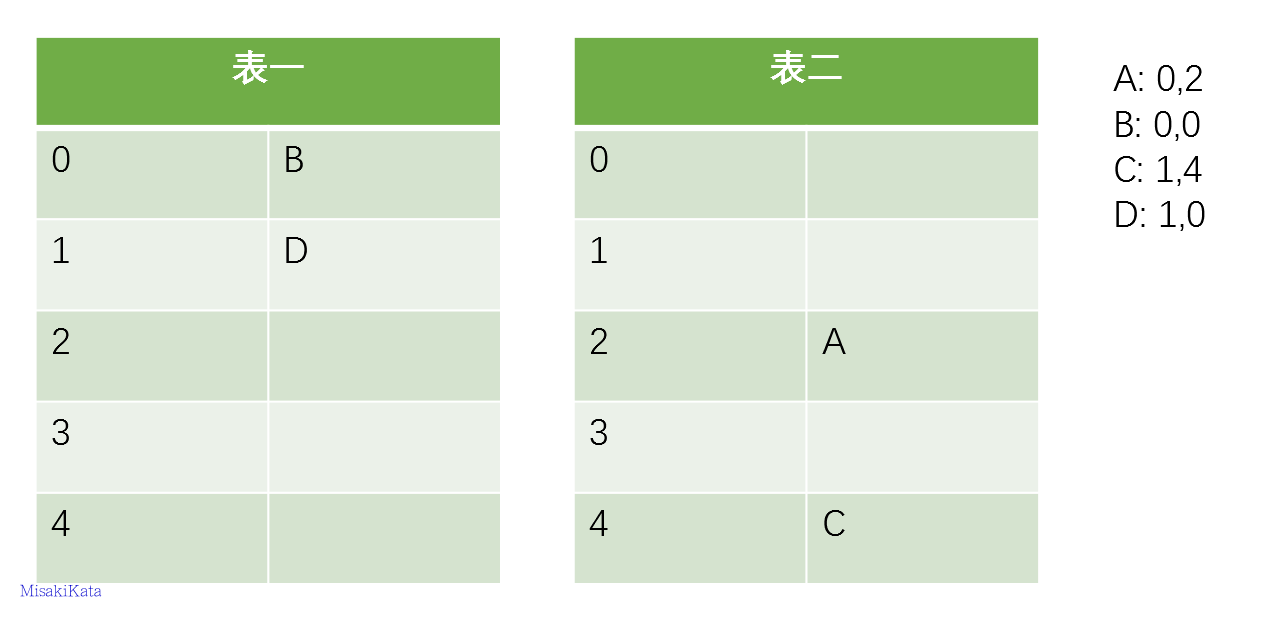
from redisbloom.client import Client
class _redis_bloom(object):
def __init__(self, size, error=0.001, key='name'):
self.size = size
self.error = error
self.key = key
self.rb = Client(host='106.54.181.x', port=6379)
self.rb.bfCreate(self.size, self.error, self.key)
self.rb.delete(key)
def insert(self, name):
if self.rb.bfExists(self.key, name) == 0:
self.rb.bfAdd(self.key, name)
return True
else:
return False
rd = _redis_bloom(size=10000)
for i in range(0, 5000):
rd.insert(i)
https://github.com/titan-web/rate-limit/blob/master/token_bucket/__init__.py
import time
from threading import RLock
__all__ = ("TokenBucket", )
class TokenBucket(object):
def __init__(self, capacity, fill_rate, is_lock=False):
:param capacity: The total tokens in the bucket.
:param fill_rate: The rate in tokens/second that the bucket will be refilled
self._capacity = float(capacity)
self._tokens = float(capacity)
self._fill_rate = float(fill_rate)
self._last_time = time.time()
self._is_lock = is_lock
self._lock = RLock()
def _get_cur_tokens(self):
if self._tokens < self._capacity:
now = time.time()
delta = self._fill_rate * (now - self._last_time) # 计算从上次发送到这次发送,新发放的令牌数量
self._tokens = min(self._capacity, self._tokens + delta) # 令牌数量不能超过桶的容量
self._last_time = now
return self._tokens
def get_cur_tokens(self):
if self._is_lock:
with self._lock:
return self._get_cur_tokens()
else:
return self._get_cur_tokens()
def _consume(self, tokens):
if tokens <= self.get_cur_tokens(): # 如果没有足够的令牌,则不能发送数据
self._tokens -= tokens
return True
return False
def consume(self, tokens): #发送数据需要的令牌
if self._is_lock:
with self._lock:
return self._consume(tokens)
else:
return self._consume(tokens)
调用的方式是传入需要的令牌数,比如
tk = TokenBucket(capacity=10, fill_rate=10) #容量10,每秒10个令牌
while True:
if tk.consume(1):
print('1111')
else:
print('2222')
time.sleep(1)
会显示如下:
当桶内令牌又新增的时候会继续发送。
https://github.com/titan-web/rate-limit/blob/master/leaky_bucket/__init__.py
from time import time, sleep
from threading import RLock
__all__ = ("LeakyBucket", )
class LeakyBucket(object):
def __init__(self, capacity, leak_rate, is_lock=False):
:param capacity: The total tokens in the bucket.
:param leak_rate: The rate in tokens/second that the bucket leaks
self._capacity = float(capacity)
self._used_tokens = 0
self._leak_rate = float(leak_rate)
self._last_time = time()
self._lock = RLock() if is_lock else None
def get_used_tokens(self):
if self._lock:
with self._lock:
return self._get_used_tokens()
else:
return self._get_used_tokens()
def _get_used_tokens(self):
now = time()
delta = self._leak_rate * (now - self._last_time) #间隔时间新泄露的漏桶令牌数
self._used_tokens = max(0, self._used_tokens - delta) #获取数不超过漏桶最大容量
return self._used_tokens
def _consume(self, tokens):
if tokens + self._get_used_tokens() <= self._capacity: #小于桶容量继续存储
self._used_tokens += tokens
self._last_time = time()
return True
return False
def consume(self, tokens): #发送数据需要的令牌
if self._lock:
with self._lock:
return self._consume(tokens)
else:
return self._consume(tokens)
使用类似如上的方法调用
ck = LeakyBucket(capacity=20, leak_rate=5) #桶容量20,每秒泄露5
while True:
if ck.consume(1):
print('1111')
else:
print('2222')
sleep(1)
结果首先把桶内的泄露完,此后每秒泄露五个。如果修改泄露数为30,这样结果任然是最多20个泄露。
参考文章:https://www.cnblogs.com/yscl/p/12003359.html
https://www.cnblogs.com/chuxiuhong/p/8215719.html
https://zhuanlan.zhihu.com/p/68418134
https://www.jianshu.com/p/c02899c30bbd
原文作者:Misaki
原文链接:https://misakikata.github.io/2020/05/Python-%E8%BF%87%E6%BB%A4%E5%99%A8/
发表日期:May 27th 2020, 4:08:24 pm
更新日期:May 27th 2020, 4:11:28 pm
版权声明:本文采用知识共享署名-非商业性使用 4.0 国际许可协议进行许可