

SQL习题汇总(三)

1、【问题】导入数据后时间列显示的都是0000
【解决】导入数据时时间列选择的数据类型是时间类型导致的,正确方法是:
1)导入数据时,此列数据类型选varchar
2)导入数据后,再使用SQL语句修改时间戳这一列为日期
2、时间戳处理
(1)获取当前时间戳
current_timestamp, current_timestamp()
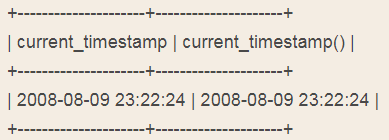
select current_timestamp, current_timestamp();结果为
(2)时间戳和日期转换
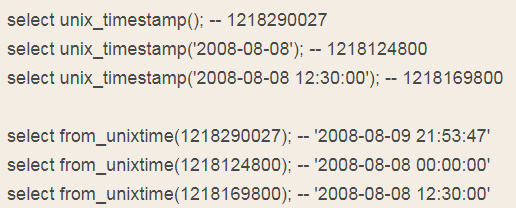
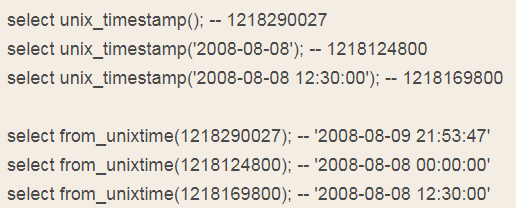
unix_timestamp(), unix_timestamp(date)——将日期时间转化为时间戳
from_unixtime(unix_timestamp), from_unixtime(unix_timestamp, format)——将时间戳转化为日期时间
1)从时间戳中抽取日期
#增加一列用于存放日期
alter tabel 表名 add 列名1 varchar(255);
#从时间戳抽取日期
update 表名
set 列名1=from_unixtime(时间戳列的列名,'%Y-%m-%d');2)从时间戳中抽取时间
#增加一列用于存放时间
alter tabel 表名 add 列名2 varchar(255);
#从时间戳抽取日期
update 表名
set 列名2=from_unixtime(时间戳列的列名,'%h:%i:%s');3)将日期转化为时间戳
#增加一列用于存放日期时间戳
alter tabel 表名 add 列名1 varchar(255);
#将日期转化为时间戳
update 表名
set 列名1=unix_timestamp(日期列的列名);4)将时间转化为时间戳
#增加一列用于存放时间戳
alter tabel 表名 add 列名1 varchar(255);
#将时间转化为时间戳
update 表名
set 列名1=unix_timestamp(时间列的列名);例如,
(3)时间戳增减函数
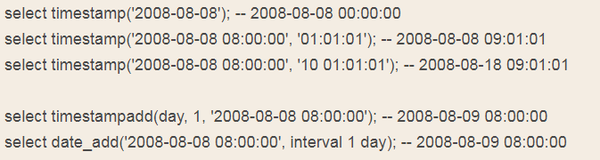
timestamp(date)——date to timestamp
timestamp(dt, time)——dt + time
timestampadd(unit, interval, datetime_expr)
timestampdiff(unit, datetime_expr1, datetime_expr2)
例如:
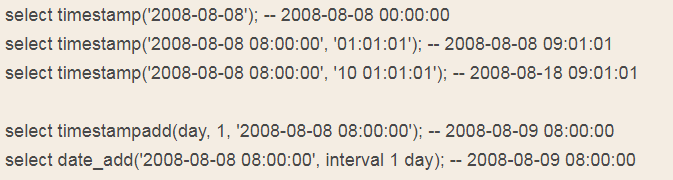
timestampdiff()函数类似于date_add()
例如:
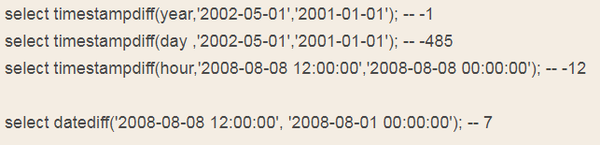
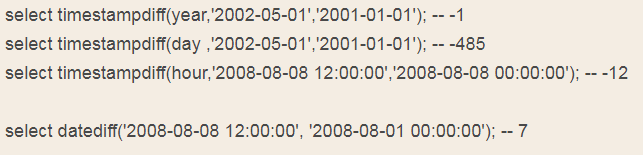
3、数据处理相关问题
(1)删除缺失值
delete from 表名 where 列名 is null;(2)填充缺失值
select coalesce(列名, 要填充的值) from 表名;(3)删除重复值
-- 第一步:创建临时表,用于存放要删除的重复值
create table 临时表名 as select 有重复值的列名 as 列名 from 原表;
-- 第二步:删除重复值
delete from 原表 where 有重复值的列名 in
(select 列名 from 临时表名 order by 列名 having count(列名)>1)
and id not in (select min(id) from 临时表名 order by 列名 having count(列名)>1);
-- 第三步:删除临时表
drop table 临时表名;4、视图和表的区别和联系
【区别】
1)视图是已经编译好的SQL语句,而表不是;
2)视图不占用物理空间,而表占用,因为视图只是逻辑概念的存在;
3)视图是窗口,表是内容;
4)视图没有实际的物理记录,而表有;
5)视图是外模式,表是内模式;
6)视图是查看数据表的一种方法,可以查询数据表中某些字段构成的数据,只是一些SQL语句的集合;
7)视图属于局部模式的表,是虚表,而表是全局模式的表,是实表;
8)视图的建立和删除只影响视图本身,不影响对应的基本表。
【联系】
视图是在基本表之上建立的表,结构(即所定义的列)和内容(即所有的数据行)都来自基本表,它依据基本表的存在而存在。一个视图可以对应一个基本表,也可以对应多个基本表。视图是基本表的抽象和在逻辑意义上建立的新关系。
5、有两张表employees和departments
employees表(employee_id, first_name, department_id, salary)
departments表(department_id, department_name, manager_id, location_id)
1)写出SQL得出每个部门的平均工资
select b.department_name, avg(a.salary)
from employees as a right join departments as b
on a.department_id=b.department_id
group by b.department_name;2)查询量表得出每个部门的最高工资
select a.first_name, max(a.salary), b.department_name
from employees as a right join departments as b
on a.department_id=b.department_id
group by b.department_name;6、数据表(tb)的基本字段:日期,订单
要求用SQL实现周次、订单总和、日均订单、极大值订单、极小值订单
select count(distinct date)/7 as 周次, count(order) as 订单总和,
count(order)/count(distinct date) as 日均订单, max(order) as 极大值订单, min(order) as 极小值订单
from tb;7、行列转换,并统计总分和平均分
原表table(姓名,科目,分数)
要求新表为(姓名,语文,数学,外语,总分,平均分)
select 姓名,
max(case 科目 when '语文' then 分数 else 0 end) as '语文',
max(case 科目 when '数学' then 分数 else 0 end) as '数学',
max(case 科目 when '外语' then 分数 else 0 end) as '外语',
sum(分数), avg(分数)
from table
group by 姓名;8、分月度销售统计
原表deptsales(deptid, subjmonth, sales, deptname)
意为:部门id,月份,销售额,部门名称
要求新表为(部门, 一月销售额,二月销售额,三月销售额,四月销售额)
select deptid as '部门',