


你知道机器学习中有哪些统计方法吗?学数据挖掘不得不知的统计知识(下)


在上一篇介绍了机器学习中的基础统计术语之后,本篇继续介绍一些统计学知识。这些统计概念在探索性数据分析,特征工程任务中非常有帮助。如果是初学者,可以先看看上一篇内容( 你知道机器学习中有哪些统计方法吗?学数据挖掘不得不知的统计知识(上) ),会让你明白一些统计学的基本术语,然后再来看看本篇内容。
1.Z-score
Z-score是描述特定值与一组值的平均值的关系的度量值。它是根据与平均值的标准偏差来衡量的。它是使用以下公式计算的。
Z-score有哪些作用?Z-score将帮助我们了解值与平均值之间的标准差;Z-score用于标准化,可以使用Z-score将变量中的值缩小到平均值;比较不同分布,并告诉哪个分布更好。比如假设我们得到了一组测试数据的平均分,最高分和标准偏差,基于此我们希望找到在2020年和2021年哪一年均值更大,我们可以使用Z-score来解决这种类型的问题(如下图)。

用Python计算Z-score:
import numpy as np
import scipy.stats as stat
arr = np.array([6, 7, 7, 12, 13, 13, 15, 16, 19, 22])
print(stat.zscore(arr, axis=0))2.置信区间
指由样本统计量所构造的总体参数的估计区间。简单来说,置信区间告诉在特定范围内发生的某些事件的置信度百分比。它是数据分析中证明我们的假设为真的重要方法之一。
CI = 点估计值±误差边际
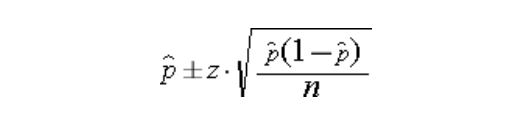
其中误差幅度基本上是一个标准差,点估计值是平均值。为了计算置信区间,我们计算点估计值,例如我们需要找到95%的置信度,因此我们将假设点估计值为0.95,并尝试找到位于这个范围之间的数据量。
使用 Python 计算置信区间:
import scipy.stats as stat
np.random.seed(10)
data = np.random.randint(10, 30, 50)
#构建人口平均体重95%置信区间
conf_interval = stat.norm.interval(alpha=0.95, loc=np.mean(data), scale=stat.sem(data))
print(conf_interval)真实总体均值的 95% 置信区间为(18.93, 22.10)。
3.假设检验
简单来说,假设是对你周围世界中某些事物的假设或猜测,猜测的结果有两种,是正确的或不正确的。在数据科学术语中,我们将假设检验称为我们尝试使用数据样本评估总体上的两个互斥陈述。
假设检验的步骤
1.做出初始假设:做出的初始假设称为原假设,用 H0 表示。在实验之前,H0 始终假定为真。与此相反,我们有一个由H1表示的替代假设。
2.收集数据:为了证明假设是正确的,收集了一些与之相关的数据。在处理机器学习问题陈述时,我们有数据,我们试图从中找到一些模式作为证据。
I 类错误和 II 类错误
当我们知道原假设为真的实际结果,但由于缺乏证据,我们不能证明它,我们必须拒绝它并选择替代假设,这被称为1类错误。而在相反的情况下,这同样适用于II类误差,当我们无法否定原假设时,就只能选择II类错误。你可以以Confusion Matrix(混淆矩阵)的形式更好地理解它。
假设检验的不同检验方法
1.P值测试
P值(P value)就是当原假设为真时,比所得到的样本观察结果更极端的结果出现的概率。如果P值很小,说明原假设情况的发生的概率很小,而如果出现了,根据小概率原理,我们就有理由拒绝原假设,P值越小,我们拒绝原假设的理由越充分。总之,P值越小,表明结果越显著。但是检验的结果究竟是“显著的”、“中度显著的”还是“高度显著的”需要我们自己根据P值的大小和实际问题来解决。
2.卡方检验
如果我们有 2 个类别变量,那么我们使用卡方检验。卡方是显示 2 个分类特征之间关系的非常好的方法。卡方是一种度量,它基本上告诉观察到的计数与总体中的 2 个变量之间没有关系时预期的计数之间存在的差异。
使用 Python 计算卡方检验的 P 值:
stat.chi2.pdf(3.84, 1)我们应用卡方变换并计算概率密度函数,从而给出 P 值。
3.T检验
当我们数据是连续特征时,我们使用的检验类型是T检验。T检验告诉两组的均值之间的显着差异,这两组可能与标签相关,也可能不相关。简而言之,t检验有助于我们比较两组的平均值,并确定它们是否来自同一群体。
为了计算T值,我们需要3个数据值。它包括平均值、标准差和多个观测值之间的差异。如果我们想对更连续的特征进行测试,那么我们将使用相关性。
4.协方差
协方差是我们在按顺序考虑数据预处理时非常重要的技术之一,量化两个随机变量之间的关系称为协方差。它类似于方差,方差告诉单个变量如何与平均值不同,协方差有助于了解两个变量如何一起变化。协方差不表示两个变量之间的强度,仅指示它们之间线性关系的方向。许多机器学习算法(如线性回归)都会使用到它。
Cov(x,y) = SUM [(xi – xm) * (yi – ym)] / (n – 1)
xm是数据集中的给定x值
xm是x值的平均值
Yi是数据集中与x对应的y值
ym是y值的平均值
n是数据点个数使用 Python 计算协方差:
arr = np.array([[2,6,8],[1,5,7],[3,6,9]])print("covariance: ", np.cov(arr))
5.相关性
相关性是用于表示两个变量之间相互关联的强度的度量,相关性是协方差的缩放形式。相关性范围介于-1到+1之间,如果相关性值接近+1,则意味着两个变量高度正相关。相反它的值接近-1意味着两个变量是负相关的。它基本上测量两个变量之间线性关系的强度和方向。
强度:如果我有两个变量作为X和Y,那么如果X增加,那么Y增加或减少,这只是相关性告诉我们的强度;
关系的方向:它意味着关系是正面还是负面的。
我们还在特征选择中使用相关性,以避免数据中的多重共线性。计算两个变量之间的相关系数有不同的方法。
1.皮尔逊相关系数
皮尔逊相关系数是计算相关系数最常用的技术,是两个变量的协方差除以其标准差的乘积。它的范围介于-1到+1 之间,它由ρ(rho)表示。
当存在完全线性关系时,皮尔逊相关系数的值将为+1(当X增加时,Y也增加)。
当 X(自变量)增加时,Y(因变量)减小,则值将为-1。
当存在非线性关系或 0 处的常数线时,该值为0。
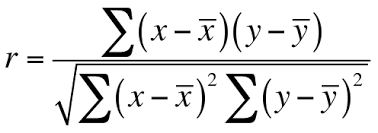
我们可以直接使用pandas DataFrame的corr方法来找到皮尔逊相关系数。
df.corr()2.斯皮尔曼秩相关系数
在斯皮尔曼秩相关性中,我们试图找到x秩和y秩的皮尔逊相关性,斯皮尔曼相关系数被定义成等级变量之间的皮尔逊相关系数。对于样本容量为n的样本,n个原始数据被转换成等级数据,计算斯皮尔曼相关系数的步骤是:
1.按第一列(Xi)对数据进行排序,并创建一个新列并为其分配从1,2,3开始的排名值,...n;
2.按第二列(Yi)对数据进行排序。创建另一列并对其进行排名;
3.创建一个新的列差(Di),用于保存两个排名列之间的差异;
4.最后,创建一个保存差值列的平方值的新列。
将值代入方程,你会得到一个相关系数:
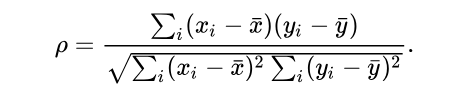
6.切比雪夫不等式
考虑一个随机变量X,它遵循高斯分布(正态),然后根据经验公式,我们可以判断出任何标准偏差中数据点的百分比。但是,如果某个随机变量假设Y不属于高斯分布,并且我们想要找到属于第一个标准差的数据点的百分比,那么为了找到这个,我们基本上使用切比雪夫不等式。
根据切比雪夫的不等式,
Pr(μ-kσ < X 1 – (1/k^2),k指定了我们必须找出下数据点百分比的标准偏差范围。例如,k = 2,Y不遵循高斯分布:
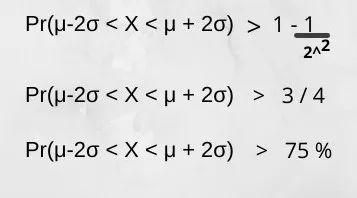
如果随机变量不遵循高斯分布,则属于Y随机变量的75%以上的数据点将落在第二个标准差的范围内。
7.Q-Q(分位数-分位数)图
分位数图通过绘制两个概率分布的分位数,在图形分析和比较两个概率分布方面起着非常重要的作用。它还用于特征转换,以检查特定特征是否正态分布。它是完全正态分布的,然后所有点都恰好位于一条直线上,即X == Y。
绘制 Q-Q 图的步骤
1.对数据要素值进行排序,并将百分位数从1变为100。
2.假设任何正态分布特征或随机正态分布变量。
3.只需在正态分布图上绘制百分位数即可。如果所有点都在线,那么它是正态分布的。
如果所有点都位于线的顶部(末端)或位于线的上方,则它是右偏斜数据。如果线的起点位于线的下方,则它是左偏斜数据。
使用 Python 绘制 Q-Q Plot
我们可以简单地使用scipy库绘制Q-Q图,以下使用泰坦尼克号数据集绘制的Q-Q图及乘客年龄列的直方图。
import pandas as pd
import matplotlib.pyplot as plt
import scipy.stats as stat
#probability plot
import pylab
data = pd.read_csv('titanic_train.csv',usecols=['Age','Fare','Survived'])
def plot_data(df,feature):
plt.figure(figsize=(10,6))
plt.subplot(1,2,1)
#1st plot
df[feature].hist()