

Spark - Structured API

本文对Spark Structured API进行深入研究,参考书籍<Spark The Definitive Guide>。
To Spark, DataFrames and Datasets represent immutable, lazily evaluated plans that specify what operations to apply to data residing at a location to generate some output.
Structured Spark Types
Spark为自己提供一套编程语言,在创建plan并处理的整个过程中,使用Catalyst engine维护自己的一套type information并在其上执行一系列优化。Spark提供lookup table将spark type映射到不同语言的类型,因此在不同语言中使用Structured API实际操作的是spark type,而不是这些语言的数据类型。
在Scala, Java, Python中借助于下面的package来使用spark type。
// Scala
import org.apache.spark.sql.types._
val b = ByteType
// Java
import org.apache.spark.sql.types.DataTypes;
ByteType x = DataTypes.ByteType;
// Python
from pyspark.sql.types import *
b = ByteType()
DataFrames Versus Datasets
两者都具有type,只是DataFrame只是在runtime时才验证其schema,而Dataset在compile time时就验证schema。Dataset只在JVM中可用,因此只能在Scala中以case class使用,或在Java中以bean形式使用。
我们大部分情况下使用DataFrame。DataFrame在scala中是类型为Row的Dataset。Row是Spark提供的对于计算进行内存格式优化的内部表示,避免JVM语言类型的垃圾回收和对象初始化开销。
Structured API Execution
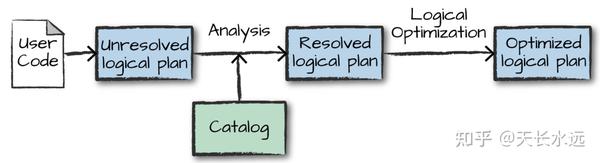
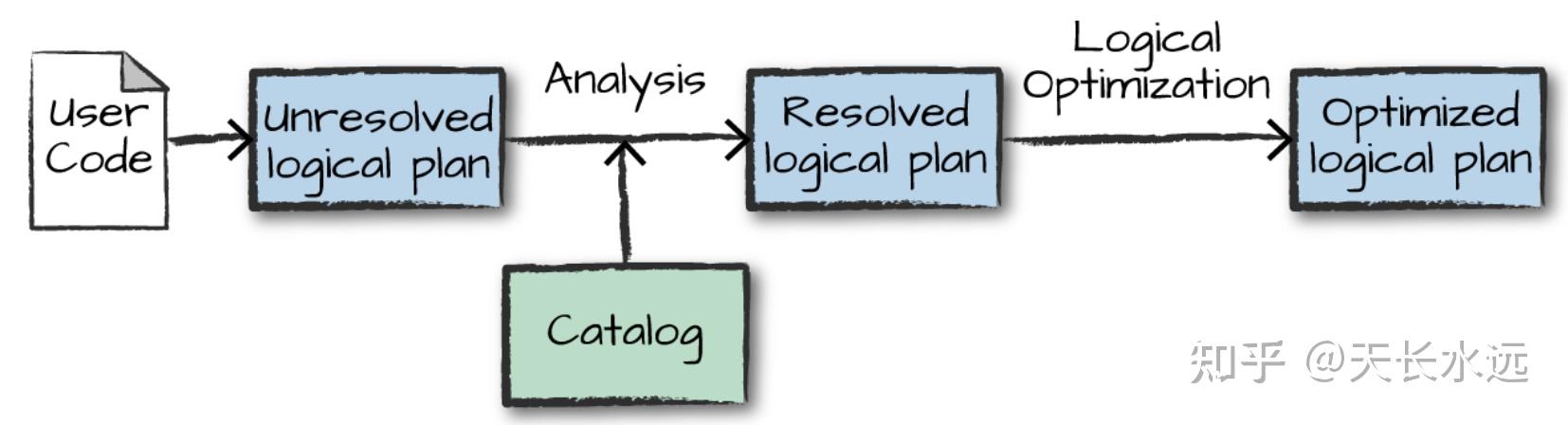
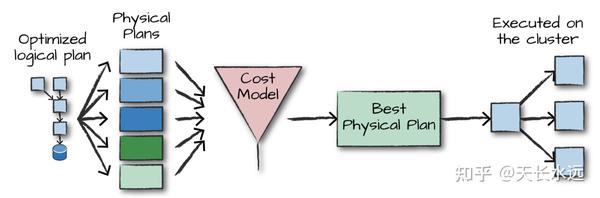
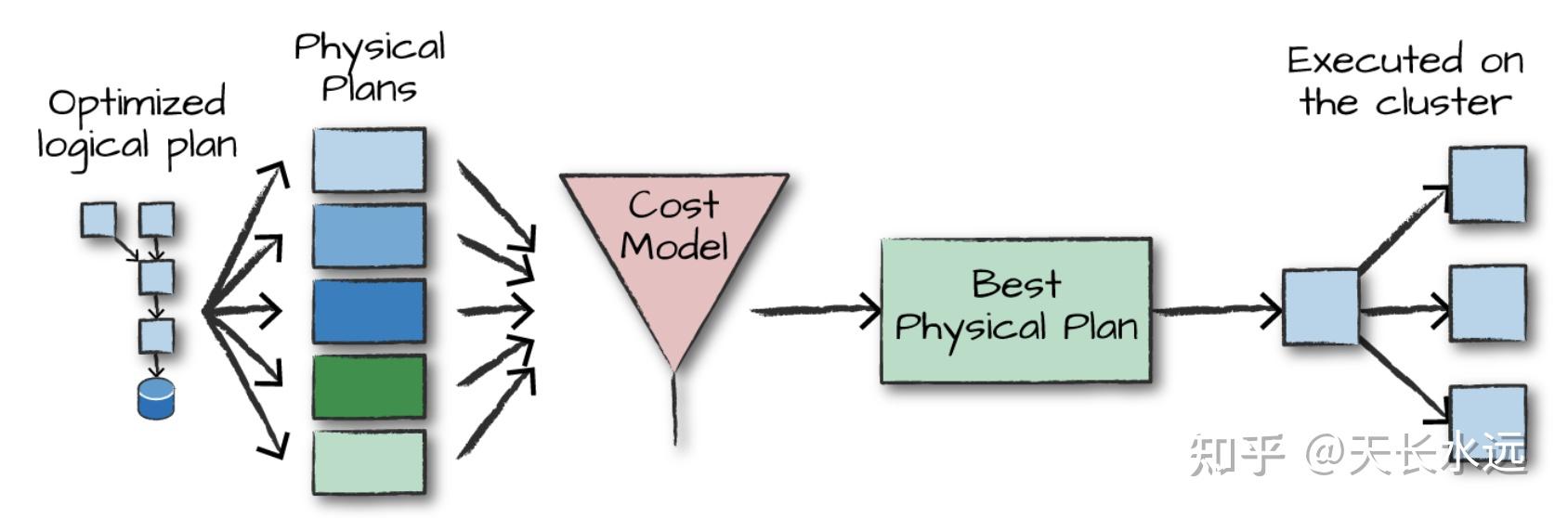
Structured API执行分为4步:1. 编写DataFrame/Dataset/SQL代码;2.代码有效,Spark将代码转化为Logic plan; 3.Spark将Logic plan转化为Physical plan并验证优化;4.在cluster上执行Physical plan。
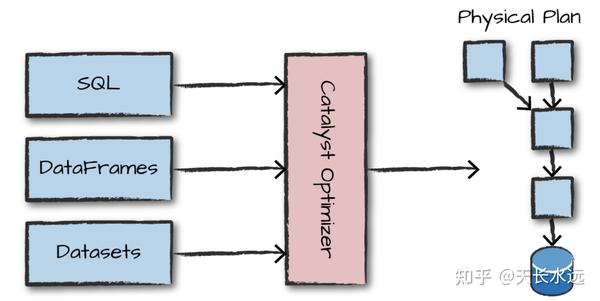
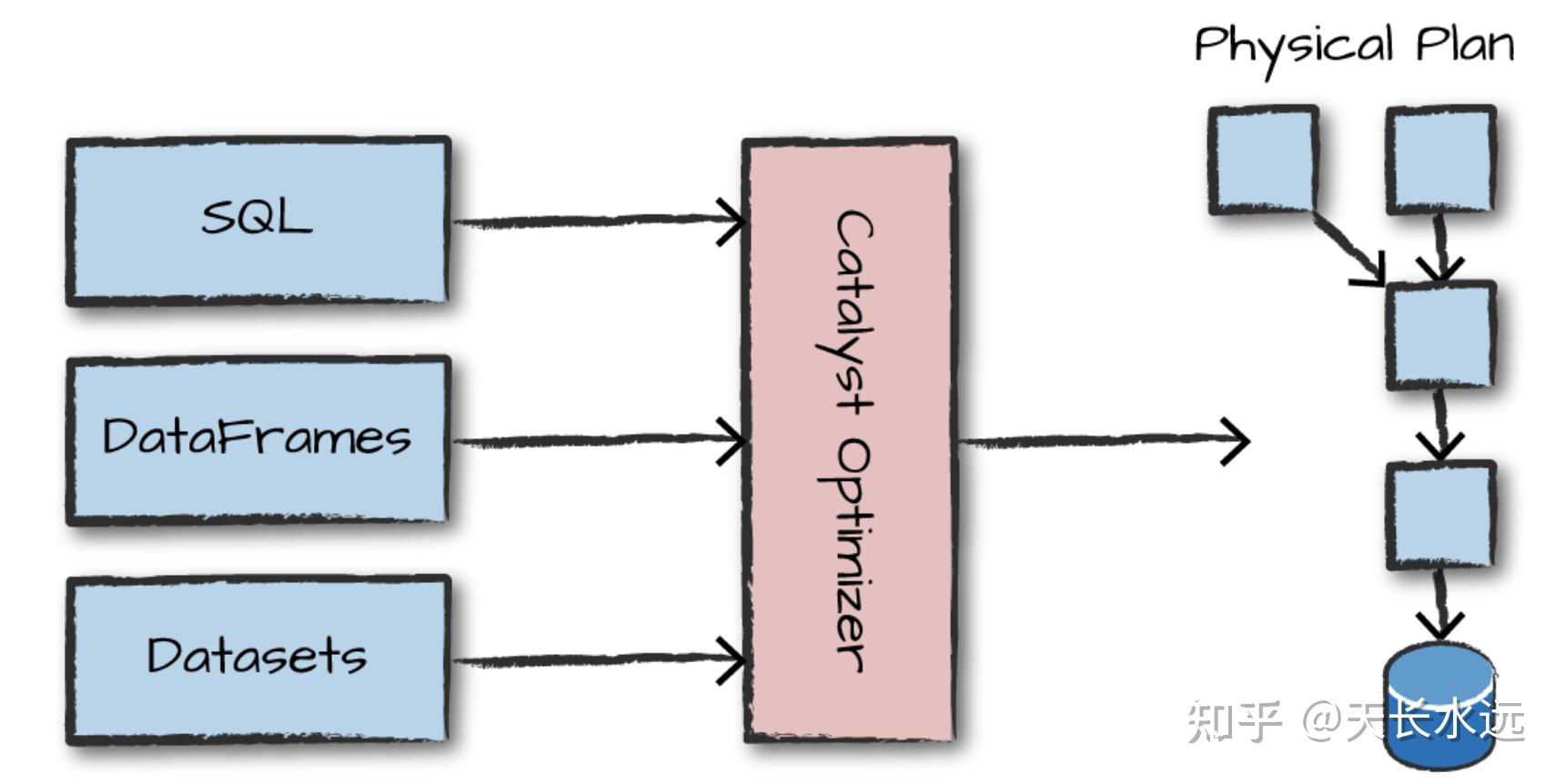
Logical plan只是表示抽象的transformations集合并不涉及executor或driver。Spark使用catalog(存放所有table和DataFrame信息的repo)来解决code中的所有table和column。Resolved logical plan传送给Catalyst optimizer使用rule集合进行优化。可以通过添加特定的rule来扩展Catalyst。
Physical plan,又称为Spark plan,指定logical plan怎么在cluster上执行。通过生成不同的physical execution strategies并用cost model进行比较来选择最好的physical plan。Physical plan生成一系列的RDD transformation。因此,Spark有时被称为compiler,将DataFrame, Dataset, SQL编译成RDD transformations。
Schema
Spark使用StructType来表示schema,其中每个column的信息使用StructField表示。下面是人工生成schema的示例,分别指定column name, type以及值是否可以为null。若运行时,数据的schema并不匹配DataFrame的schema, Spark将抛出error。
val schema = StructType(
StructField("Column_Name1", StringType, true),
StructField("Column_Name2", LongType, true),
StructField("Column_Name3", StringType, false))Spark中可以使用下面的函数来获取column。
df.col("name")
df.column("name")column是一种expression。Expression为在DataFrame的一个或多个column上执行的一系列transformation,使用函数expr()表示。下面两种表示方法相同。
(((col("name") + 5) * 200) - 6) < col("other")
expr("(("name" + 5) * 200) - 6 < other")DataFrame中每行都是一个record,表示为类型为Row的object,内部表示为字节的数组。需要注意的是,DataFrame中包含schema,Row中不包含schema。因此手动创建Row时,应注意field的顺序。访问Row中的数据需要指定position。
val row = Row("name", 1, null, false)
row(0) // type Any
row(0).asInstanceOf[String] // String
row.getString(0) //String
row.getInt(1) //IntDataFrame基本操作
函数select和selectExpr允许像SQL查询一样处理DataFrame。由于多种方式可以表示column,下面这些方式可以交替使用。
df.select("DEST_COUNTRY_NAME", "ORIGIN_COUNTRY_NAME").show(2)
df.select(
df.col("DEST_COUNTRY_NAME"),
col("DEST_COUNTRY_NAME"),
column("DEST_COUNTRY_NAME"),
'DEST_COUNTRY_NAME,
$"DEST_COUNTRY_NAME",
expr("DEST_COUNTRY_NAME"))
.show(2)避免将column object与string混合使用,下面这种混用将报错。
df
.select(col("DEST_COUNTRY_NAME"), "DEST_COUNTRY_NAME")下面的示例中,使用表达式来选择和生成column。
df.select(expr("DEST_COUNTRY_NAME AS destination")).show(2)
df.selectExpr(
"*", // include all original columns
"(DEST_COUNTRY_NAME = ORIGIN_COUNTRY_NAME) as withinCountry")
.show(2)
df.selectExpr("avg(count)", "count(distinct(DEST_COUNTRY_NAME))").show(2)
df.select(expr("*"), lit(1).as("One")).show(2)withColumn函数为DataFrame添加column,参数1为column name,参数2为column的值。
df.withColumn("numberOne", lit(1)).show(2)
df.withColumn("withinCountry", expr("ORIGIN_COUNTRY_NAME == DEST_COUNTRY_NAME"))
.show(2)withColumnRenamed函数重命名DataFrame中的column。
df.withColumnRenamed("DEST_COUNTRY_NAME", "dest").columns对于column name中的保留字符,如空格,-等,当在expression中使用时,需借助于`来转义。第一个示例的column name并不是expression,只是string,不需要转义。
dfWithLongColName.select(col("This Long Column-Name")).columns
dfWithLongColName.select(expr("`This Long Column-Name`")).columns默认情况下,Spark是大小写不敏感的,通过下面设置来设置Spark大小写敏感。
-- in SQL
set spark.sql.caseSensitive truedrop函数可以移除DataFrame中的column。
df.drop("ORIGIN_COUNTRY_NAME").columnscast函数用来转化column的数据类型。
df.withColumn("count2", col("count").cast("long"))使用filter和where函数可以对DataFrame进行过滤。Spark会同时处理多个filter,并不关系filter的顺序。
df.filter(col("count") < 2).show(2)
df.where("count < 2").show(2)
df.where(col("count") < 2).where(col("ORIGIN_COUNTRY_NAME") =!= "Croatia")
.show(2)distinct函数用来获得指定columns唯一的所有数据。
df.select("ORIGIN_COUNTRY_NAME", "DEST_COUNTRY_NAME").distinct().count()sample函数用来从数据中随机获取一些样本数据。
val seed = 5
val withReplacement = false
val fraction = 0.5
df.sample(withReplacement, fraction, seed).count()randomSplit函数用来按比例随机拆分DataFrame。
val dataFrames = df.randomSplit(Array(0.25, 0.75), seed)
dataFrames(0).count() > dataFrames(1).count() // Falseunion函数用来将2个DataFrame合并在一起,必须具有相同的schema。 目前,union使用location而不是schema来合并。
df.union(newDF)sort和orderBy函数用来对DataFrame进行排序,可以使用expression或string并作用在多个column上。默认以升序排序,显式指定desc或asc来指定排序顺序。
df.sort("count").show(5)
df.orderBy("count", "DEST_COUNTRY_NAME").show(5)
df.orderBy(col("count"), col("DEST_COUNTRY_NAME")).show(5)
df.orderBy(expr("count desc")).show(2)
df.orderBy(desc("count"), asc("DEST_COUNTRY_NAME")).show(2)指定asc_nulls_first,desc_nulls_first,asc_nulls_last, ordesc_nulls_last 来处理null的排序。
函数sortWithinPartitions来在partition中排序。
spark.read.format("json").load("/data/flight-data/json/*-summary.json")
.sortWithinPartitions("count")limit函数用来限制返回的record的数量。
df.limit(5).show()依据column对DataFrame进行partition来指定数据的物理存放位置,是一种重要的优化手段。Repartition将会导致全量数据的shuffle,不管是不是必要。
df.rdd.getNumPartitions // 1
df.repartition(5)
df.repartition(col("DEST_COUNTRY_NAME"))
df.repartition(5, col("DEST_COUNTRY_NAME"))Coalesce并不会导致全量数据的shuffle,下面示例将数据shuffle到5个partition,然后coalesce。
df.repartition(5, col("DEST_COUNTRY_NAME")).coalesce(2)使用collect,take以及show函数可以将DataFrame数据传送到driver。当数据量很大时,小心使用collect。
val collectDF = df.limit(10)
collectDF.take(5) // take works with an Integer count
collectDF.show() // this prints it out nicely
collectDF.show(5, false)
collectDF.collect()不同Data Type的处理
lit函数能够将其他语言的数据类型转换成相应的Spark表示。
import org.apache.spark.sql.functions.lit
df.select(lit(5), lit("five"), lit(5.0))Boolean表达式有and, or, true, false。Spark中,scala使用===和=!=来作为等于和不等于用于filter,也可以使用not和equalTo函数。
df.where(col("InvoiceNo").equalTo(536365))
df.where(col("InvoiceNo") === 536365)
df.where("InvoiceNo = 536365")
val priceFilter = col("UnitPrice"
) > 600
val descripFilter = col("Description").contains("POSTAGE")
df.where(col("StockCode").isin("DOT")).where(priceFilter.or(descripFilter))
val DOTCodeFilter = col("StockCode") === "DOT"
val priceFilter = col("UnitPrice") > 600
val descripFilter = col("Description").contains("POSTAGE")
df.withColumn("isExpensive", DOTCodeFilter.and(priceFilter.or(descripFilter)))
.where("isExpensive")
df.withColumn("isExpensive", not(col("UnitPrice").leq(250)))
.filter("isExpensive")
df.withColumn("isExpensive", expr("NOT UnitPrice <= 250"))
.filter("isExpensive")Spark为Number类型提供很多函数。
import org.apache.spark.sql.functions.{expr, pow}
val fabricatedQuantity = pow(col("Quantity") * col("UnitPrice"), 2) + 5
df.select(expr("CustomerId"), fabricatedQuantity.alias("realQuantity")).show(2)
df.selectExpr(
"CustomerId",
"(POWER((Quantity * UnitPrice), 2.0) + 5) as realQuantity").show(2)round函数用来对数字round,默认round up,使用bround来round down。
import org.apache.spark.sql.functions.{round, bround}
df.select(round(col("UnitPrice"), 1).alias("rounded"), col("UnitPrice")).show(5)
df.select(round(lit("2.5")), bround(lit("2.5"))).show(2)corr函数计算两个column之间的相关度。
import org.apache.spark.sql.functions.{corr}
df.stat.corr("Quantity", "UnitPrice")
df.select(corr("Quantity", "UnitPrice")).show()describe函数用来展示指定column或所有column的统计信息,包括数量,均值,方差,最大最小值。
df.describe().show()monotonically_increasing_id函数为每行生成一个递增字段,以0开始。
df.select(monotonically_increasing_id()).show(2)Spark提供很多函数来处理String。
initcap函数将字符串中每个word的首字母大写。lower和upper分别将字符串小写和大写。trim去除字符串左右两边的空格,pad在字符串左右两边添加字符。若lpad和rpad获取的元素少于字符串长度,去除字符串右边的字符。
import org.apache.spark.sql.functions.{initcap}
df.select(initcap(col("Description"))).show(2, false)
df.select(col("Description"),
lower(col("Description")),
upper(lower(col("Description")))).show(2)
df.select(
ltrim(lit(" HELLO ")).as("ltrim"),
rtrim(lit(" HELLO ")).as("rtrim"),
trim(lit(" HELLO ")).as("trim"),
lpad(lit("HELLO"), 3, " ").as("lp"),
rpad(lit("HELLO"), 10, " ").as("rp")).show(2)
-- in SQL
SELECT initcap(Description) FROM dfTable
SELECT Description, lower(Description), Upper(lower(Description)) FROM dfTable
SELECT
ltrim(' HELLLOOOO '),
rtrim(' HELLLOOOO '),
trim(' HELLLOOOO '),
lpad('HELLOOOO ', 3, ' '),
rpad('HELLOOOO ', 10, ' ')
FROM dfTableSpark使用Java提供的regular expression。regexp_extract和regexp_replace函数分别使用regular expression来提取字符串,替换字符串。
下面示例使用COLOR替换掉字符串中的颜色,或获取regular expression第一个匹配的字符串。
import org.apache.spark.sql.functions.regexp_replace
val simpleColors = Seq("black", "white", "red", "green", "blue")
val regexString = simpleColors.map(_.toUpperCase).mkString("|")
// the | signifies `OR` in regular expression syntax
df.select(
regexp_replace(col("Description"), regexString, "COLOR").alias("color_clean"),
col("Description")).show(2)
df.select(
regexp_extract(col("Description"), regexString, 1).alias("color_clean"),
col("Description")).show(2)
-- in SQL
SELECT
regexp_replace(Description, 'BLACK|WHITE|RED|GREEN|BLUE', 'COLOR') as
color_clean, Description
FROM dfTable
SELECT regexp_extract(Description, '(BLACK|WHITE|RED|GREEN|BLUE)', 1),
Description
FROM dfTabletranslate函数在字符级别,将字符用指定字符替换。示例中将LET分别用137替换。
import org.apache.spark.sql.functions.translate
df.select(translate(col("Description"), "LEET", "1337"), col("Description"))
.show
(2)
-- in SQL
SELECT translate(Description, 'LEET', '1337'), Description FROM dfTablecontains函数用来判断字符串中是否存在该子串。
val containsBlack = col("Description").contains("BLACK")
val containsWhite = col("DESCRIPTION").contains("WHITE")
df.withColumn("hasSimpleColor", containsBlack.or(containsWhite))
.where("hasSimpleColor")
.select("Description").show(3, false)
-- in SQL
SELECT Description FROM dfTable
WHERE instr(Description, 'BLACK') >= 1 OR instr(Description, 'WHITE') >= 1Spark中可以使用动态长度的参数,下面示例结合select函数使用。
val simpleColors = Seq("black", "white", "red", "green", "blue")
val selectedColumns = simpleColors.map(color => {
col("Description").contains(color.toUpperCase).alias(s"is_$color")
}):+expr("*") // could also append this value
df.select(selectedColumns:_*).where(col("is_white").or(col("is_red")))
.select("Description").show(3, false)Python中使用locate来实现相同功能。
# in Python
from pyspark.sql.functions import expr, locate
simpleColors = ["black", "white", "red", "green", "blue"]
def color_locator(column, color_string):
return locate(color_string.upper(), column)\
.cast("boolean")\
.alias("is_" + c)
selectedColumns = [color_locator(df.Description, c) for c in simpleColors]
selectedColumns.append(expr("*")) # has to a be Column type
df.select(*selectedColumns).where(expr("is_white OR is_red"))\
.select("Description").show(3, False)Spark中经常将date或timestamp保存为string并在运行时将string转换回date和timestamp。
Spark 2.1及之前,使用local machine的timezone来作为数据的timezone。Spark的TimestampType只支持秒级别的精度。
下面是处理date的一些函数示例。
- current_date和current_timestamp函数用来获取当前的日期和时间;
- date_sub和date_add函数用来获取指定日期多少天之前或之后的日期;
- datediff和months_between函数获取两个日期之间的天数和月数;
- to_date函数用于将特定格式的字符串转化为date, 转换失败时返回null并不报错 ;可以通过给to_date函数添加dateFormat来解决这个问题。to_timestamp函数强制要求提供dateFormat。
- date和timestamp的转化需要显式指定格式。
import org.apache.spark.sql.functions.{current_date, current_timestamp}
val dateDF = spark.range(10)
.withColumn("today", current_date())
.withColumn("now", current_timestamp())
dateDF.createOrReplaceTempView("dateTable")
dateDF.select(date_sub(col("today"), 5), date_add(col("today"), 5)).show(1)
import org.apache.spark.sql.functions.{datediff, months_between, to_date}
dateDF.withColumn("week_ago", date_sub(col("today"), 7))
.select(datediff(col("week_ago"), col("today"))).show(1)
dateDF.select(
to_date(lit("2016-01-01")).alias("start"),
to_date(lit("2017-05-22")).alias("end"))
.select(months_between(col("start"), col("end"))).show(1)
spark.range(5).withColumn("date", lit("2017-01-01"))
.select(to_date(col("date"))).show(1)
val dateFormat = "yyyy-dd-MM"
val cleanDateDF = spark.range(1).select(
to_date(lit("2017-12-11"), dateFormat).alias("date"),
to_date(lit("2017-20-12"), dateFormat).alias("date2"))
cleanDateDF.createOrReplaceTempView("dateTable2")
cleanDateDF.select(to_timestamp(col("date"), dateFormat)).show()
SELECT cast(to_date("2017-01-01", "yyyy-dd-MM") as timestamp)
cleanDateDF.filter(col("date2") > lit("2017-12-12")).show()
cleanDateDF.filter(col("date2") > "'2017-12-12'").show()推荐使用null来表示DataFrames中的缺失值或空值,Spark对null存在更多优化。
- coalesce函数返回一组column都不为null的第一条记录;
- ifnull函数返回第一个参数,若其为null,返回第二个参数;
- nullif函数当2个参数相同时返回null,否则,返回第二个参数;
- nvl函数返回第一个参数,若其为null,返回第二个参数;
- nvl2函数当第一个参数不为null是返回第二个参数,否则,返回第三个参数;
df.select(coalesce(col("Description"), col("CustomerId"))).show()
SELECT
ifnull(null, 'return_value'),
nullif('value', 'value'),
nvl(null, 'return_value'),
nvl2('not_null', 'return_value',
"else_value")
FROM dfTable LIMIT 1
+------------+----+------------+------------+
| a| b| c| d|
+------------+----+------------+------------+
|return_value|null|return_value|return_value|
+------------+----+------------+------------+drop函数可以用来删除包含null值的row,默认删除任何值为null的row。
// 任何值为null都drop该row
df.na.drop()
df.na.drop("any")
// 仅当所有值为null时才drop该row
df.na.drop("all")
// 仅适用于指定的columns
df.na.drop("all", Seq("StockCode", "InvoiceNo"))fill函数用来为值为null的column赋于指定的值。当然,也可以指定fill应用的columns。我们也可以使用map来实现该功能,key为column name, value为替换null的值。
//将所有String类型column的null值替换成这里的字符串
df.na.fill("All Null values become this string")
df.na.fill(5:Integer)
df.na.fill(5:Double)
df.na.fill(5, Seq("StockCode", "InvoiceNo"))
val fillColValues = Map("StockCode" -> 5, "Description" -> "No Value")
df.na.fill(fillColValues)replace函数用于将指定column中指定值替换成目标值。示例中,将column Description中所有""替换成"UNKNOWN".
df.na.replace("Description", Map("" -> "UNKNOWN"))Spark中存在3种复杂类型:structs, arrays以及maps。
structs可以被理解为DataFrame中包含DataFrame。我们可以组合多个column来生成structs。访问structs,需要借助于.或者getField函数,.*用于获取structs中所有columns。
df.selectExpr("(Description, InvoiceNo) as complex", "*")
df.selectExpr("struct(Description, InvoiceNo) as complex", "*")
val complexDF = df.select(struct("Description", "InvoiceNo").alias("complex"))
complexDF.select("complex.Description")
complexDF.select(col("complex").getField("Description"))
complexDF.select("complex.*")我们可以使用split函数将字符串变为数据,并通过[]来访问数组中每个元素,从0开始。size函数用于获取数组的大小。array_contains函数用于判断数组中是否具有指定元素。
df.select(split(col("Description"), " ").alias("array_col"))
.selectExpr("array_col[0]").show(2)
df.select(size(split(col("Description"), " "))).show(2) // shows 5 and 3
df.select(array_contains(split(col("Description"), " "), "WHITE")).show(2)explode函数以数组column作为输入,以数组中每个元素生成一行,每行中该column的值为数组中一个元素。

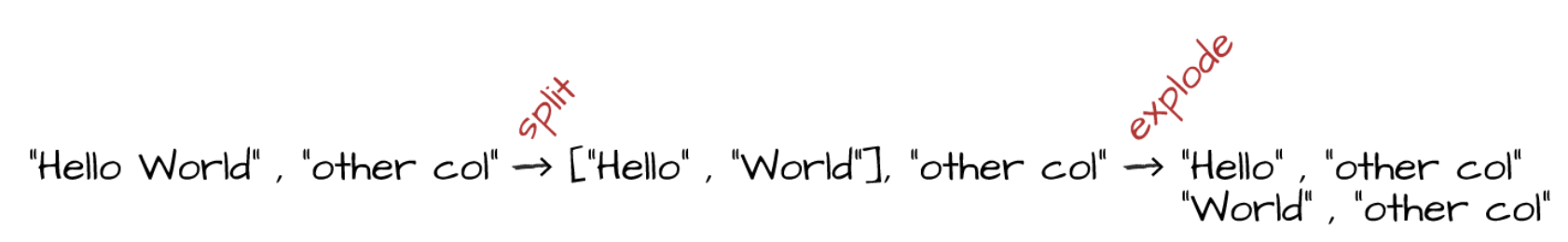
df.withColumn("splitted", split(col("Description"), " "))
.withColumn("exploded", explode(col("splitted")))
.select("Description", "InvoiceNo", "exploded").show(2)借助于map函数以及key-value columns可以生成Maps。
df.select(map(col("Description"), col("InvoiceNo")).alias("complex_map"))
.selectExpr("complex_map['WHITE METAL LANTERN']").show(2)
+--------------------------------+
|complex_map[WHITE METAL LANTERN]|
+--------------------------------+
| null|
| 536365|
+--------------------------------+Spark提供了对JSON数据的支持。get_json_object函数用来对JSON object进行inline query,json_tuple函数用来获取object中key对应的value。
val jsonDF = spark.range(1).selectExpr("""
'{"myJSONKey" : {"myJSONValue" : [1, 2, 3]}}' as jsonString""")
import org.apache.spark.sql.functions.{get_json_object, json_tuple}
jsonDF.select(
get_json_object(col("jsonString"), "$.myJSONKey.myJSONValue[1]") as "column",
json_tuple(col("jsonString"), "myJSONKey")).show(2)
+------+--------------------+
|column| c0|
+------+--------------------+
| 2|{"myJSONValue":[1...|
+------+--------------------+to_json函数用于将StructType转化为JSON string,from_json函数用于将JSON string生成对应StructType。
val parseSchema = new StructType(Array(
new StructField("InvoiceNo",StringType,true),
new StructField("Description",StringType,true)))
df.selectExpr("(InvoiceNo, Description) as myStruct")
.select(to_json(col("myStruct")).alias("newJSON"))
.select(from_json(col("newJSON"), parseSchema), col("newJSON")).show(2)
+----------------------+--------------------+
|jsontostructs(newJSON)| newJSON|
+----------------------+--------------------+
| [536365,WHITE HAN...|{"InvoiceNo":"536...|
| [536365,WHITE MET...|{"InvoiceNo":"536...|
+----------------------+--------------------+User-Defined Functions
UDF为用户定义的函数,处理data中的每个record。默认情况下,这些函数被注册为临时函数,应用于SparkSession或SparkContext中。
下面我们定义了简单的power3函数,输入输出都输Double类型。当将函数注册到Spark,Spark将在driver上序列化该函数并将其传送到所有executors。
// Define function
def power3(number:Double)
:Double = number * number * number
// Register function
val power3udf = udf(power3(_:Double):Double)
// Use function
udfExampleDF.select(power3udf(col("num"))).show()也可以将function注册到Spark SQL,注册的函数可以跨语言使用,即注册的scala函数可以在python代码中使用。
// Register and use function in scala
spark.udf.register("power3", power3(_:Double):Double)
udfExampleDF.selectExpr("power3(num)").show(2)
# Use function in Python
udfExampleDF.selectExpr("power3(num)").show(2)Aggregations
Spark中提供了很多aggregation函数,但数据量大的情况下,aggregation的性能可能比较差,这时选择在指定准确度范围内的approximate函数可以解决这个问题。
下面展示一些aggregation函数的使用。
count函数获取DataFrame的record数量,参数可以是指定column,也可以是所有column。count(*)/count(1)会统计column值为null的record,但是count(column)不统计null。
countDistinct函数统计指定column的值distinct的数量,数据量大时性能差;approx_count_distinct函数在允许误差下统计distinct的数量,性能好,示例中参数2指定最大误差是0.1。
first, last, min, max, sum, sumDistinct, avg, mean函数分别完成相关统计工作。
import org.apache.spark.sql.functions.count
df.select(count("StockCode")).show() // 541909
df.select(count("*")).show() // 541909
df.select(count(1)).show() // 541909
df.select(countDistinct("StockCode")).show() // 4070
df.select(approx_count_distinct("StockCode", 0.1)).show() // 3364
df.select(first("StockCode"), last("StockCode")).show()
df.select(min("Quantity"), max("Quantity")).show()
df.select(sum("Quantity")).show() // 5176450
df.select(sumDistinct("Quantity")).show() // 29310
df.select(
count("Quantity").alias("total_transactions"),
sum("Quantity").alias("total_purchases"),
avg("Quantity").alias("avg_purchases"),
expr("mean(Quantity)").alias("mean_purchases"))方差(variance)和标准差(standard deviation)用于表示数据的分布特征,spark提供2套公式来计算,样本方差和总体方差。当调用函数variance和stddev时,spark默认使用样本方差和样本标准差。
import org.apache.spark.sql.functions.{var_pop, stddev_pop}
import org.apache.spark.sql.functions.{var_samp, stddev_samp}
df.select(var_pop("Quantity"), var_samp("Quantity"),
stddev_pop("Quantity"), stddev_samp("Quantity")).show()偏度系数(Skewness)用来衡量数据相对均值的不对称性。峰度(kurtosis)用来衡量数据相对于正态分布的是heavy-tailed或light-tailed, kurtosis越大,越heavy-tailed。这2种方法用来衡量数据的极端值(extreme points)。
import org.apache.spark.sql.functions.{skewness, kurtosis}
df.select(skewness("Quantity"), kurtosis("Quantity")).show()相关度和协方差用来衡量两列的关系。相关度(Correlation,这里是Pearson correlation coefficient)取值范围为-1~1,使用函数corr来调用。协方差(covariance)根据输入数据的大小缩放。协方差分为样本协方差(sample covariance)和总量协方差(population covariance),分别对应函数covar_samp和covar_pop。
import org.apache.spark.sql.functions.{corr, covar_pop, covar_samp}
df.select(corr("InvoiceNo", "Quantity"), covar_samp("InvoiceNo", "Quantity"),
covar_pop("InvoiceNo", "Quantity")).show()Group使用指定columns作为key进行group并对其他column进行aggregate。
df.groupBy("InvoiceNo", "CustomerId").count().show()
df.groupBy("InvoiceNo").agg(
count("Quantity").alias("quan"),
expr("count(Quantity)")).show()
df.groupBy("InvoiceNo").agg("Quantity"->"avg", "Quantity"->"stddev_pop").show()User-defined aggregation functions (UDAFs)用来自定义aggregation函数。Spark使用AggregationBuffer来保存input中每个group的中间结果。实现UDAF需要继承基类UserDefinedAggregateFunction并实现下面几个函数:


下面是实现BooleanAnd的示例,实例化并注册该类后便可以使用。目前UDAF只能在Java和Scala中使用。
import org.apache.spark.sql.expressions.MutableAggregationBuffer
import org.apache.spark.sql.expressions.UserDefinedAggregateFunction
import org.apache.spark.sql.Row
import org.apache.spark.sql.types._
class BoolAnd extends UserDefinedAggregateFunction {
def inputSchema: org.apache.spark.sql.types.StructType =
StructType(StructField("value", BooleanType) :: Nil)
def bufferSchema: StructType = StructType(
StructField("result", BooleanType) :: Nil
def dataType: DataType = BooleanType
def deterministic: Boolean = true
def initialize(buffer: MutableAggregationBuffer): Unit = {
buffer(0) = true
def update(buffer: MutableAggregationBuffer, input: Row): Unit = {
buffer(0) = buffer.getAs[Boolean](0) && input.getAs[Boolean](0)
def merge(buffer1: MutableAggregationBuffer, buffer2: Row): Unit = {
buffer1(0) = buffer1.getAs[Boolean](0) && buffer2.getAs[Boolean](0)
def evaluate(buffer: Row)
: Any = {
buffer(0)
val ba = new BoolAnd
spark.udf.register("booland", ba)
import org.apache.spark.sql.functions._
spark.range(1)
.selectExpr("explode(array(TRUE, TRUE, TRUE)) as t")
.selectExpr("explode(array(TRUE, FALSE, TRUE)) as f", "t")
.select(ba(col("t")), expr("booland(f)"))
.show()Join
Join用于将两个dataset使用公用的column作为key进行join。下面列举所有join类型。


下面是准备join的数据集。Inner join是默认的join方式,也可以显示指定join type。left semi值保留left dataset的值,当left的key在right中出现,则出现在结果中。left anti join与left semi相反,当left的key不在right中出现,则出现在结果中。
Natural join隐式推测join使用的column,left, right, outer join都被支持。注意:隐式推断join column会产生危险。
Cross-join或笛卡尔积( cartesian products) 将left dataset的每一行来join right dataset中的每一个行。
val person = Seq(
(0, "Bill Chambers", 0, Seq(100)),
(1, "Matei Zaharia", 1, Seq(500, 250, 100)),
(2, "Michael Armbrust", 1, Seq(250, 100)))
.toDF("id", "name", "graduate_program", "spark_status")
val graduateProgram = Seq(
(0, "Masters", "School of Information", "UC Berkeley"),
(2, "Masters", "EECS", "UC Berkeley"),
(1, "Ph.D.", "EECS", "UC Berkeley"))
.toDF("id", "degree", "department", "school")
val sparkStatus = Seq(
(500, "Vice President"),
(250, "PMC Member"),
(100, "Contributor"))
.toDF("id", "status")
person.createOrReplaceTempView("person")
graduateProgram.createOrReplaceTempView("graduateProgram")
sparkStatus.createOrReplaceTempView("sparkStatus")
// Inner join
val joinExpression = person.col("graduate_program") === graduateProgram.col("id")
person.join(graduateProgram, joinExpression).show()
var joinType = "inner"//"outer", "left_outer", "right_outer", "left_semi, "left_anti", "cross"
person.join(graduateProgram, joinExpression, joinType).show()
person.crossJoin(graduateProgram).show()
SELECT * FROM person INNER JOIN graduateProgram
ON person.graduate_program = graduateProgram.id
SELECT * FROM person FULL OUTER JOIN graduateProgram
ON graduate_program = graduateProgram.id
SELECT * FROM graduateProgram LEFT OUTER JOIN person
ON person.graduate_program = graduateProgram.id
SELECT * FROM person RIGHT OUTER JOIN graduateProgram
ON person.graduate_program = graduateProgram.id
SELECT * FROM gradProgram2 LEFT SEMI JOIN person
ON gradProgram2.id = person.graduate_program
SELECT * FROM graduateProgram LEFT ANTI JOIN person
ON graduateProgram.id = person.graduate_program
SELECT * FROM graduateProgram NATURAL JOIN person
SELECT * FROM graduateProgram CROSS JOIN person
ON graduateProgram.id = person.graduate_program任何返回值为Boolean的表达式都可以作为join expression。因此可以容易生成复杂的join。
person.withColumnRenamed("id", "personId")
.join(sparkStatus, expr("array_contains(spark_status, id)")).show()
-- SQL
SELECT * FROM
(select id as personId, name, graduate_program, spark_status FROM person)
INNER JOIN sparkStatus ON array_contains(spark_status, id)若join的2个dataset具有相同的column name,结果中这两个column同时存在,导致出现2个具有相同column name的column。下面是3中解决方法。
// 将自动去除一个column
person.join(gradProgramDupe,"graduate_program").select("graduate_program").show()
// join后删除一个column
person.join(gradProgramDupe, joinExpr).drop(person.col("graduate_program"))
.select("graduate_program").show()
// join之前重命名column
val gradProgram3 = graduateProgram.withColumnRenamed("id", "grad_id")
val joinExpr = person.col("graduate_program") === gradProgram3.col("grad_id")
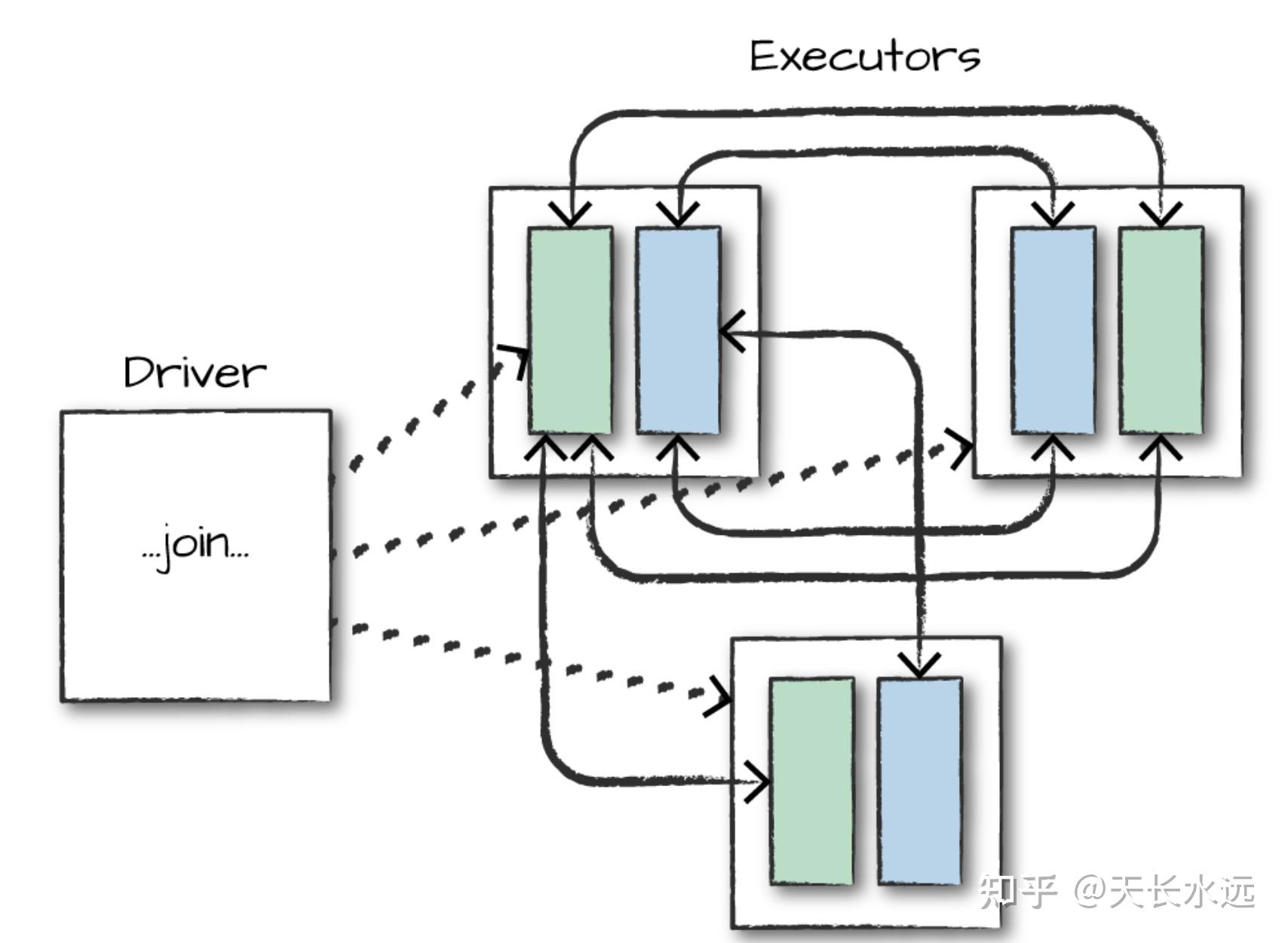
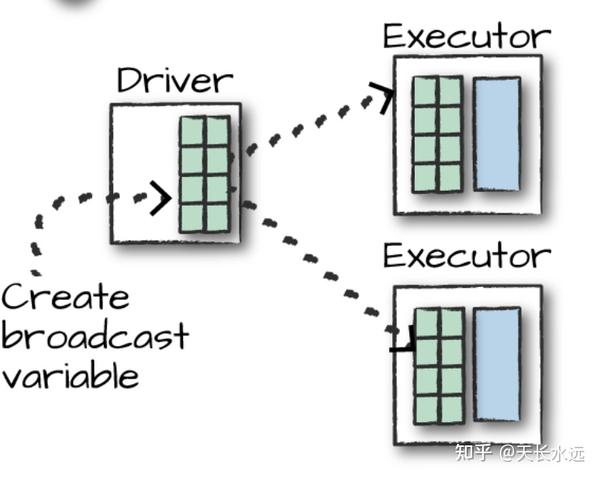
person.join(gradProgram3, joinExpr).show()Join时,Spark存在2种join: shuffle join和broadcast join。前者导致全cluster node之间的网络沟通,两个big table进行join时应用。后者适用于一个table比较小,将小table广播到各个node进行join,减少网络沟通。
Join时可以给optimizer一些hint来使用broadcast join,但不一定真实这样执行。推荐在执行join之前正确的partition数据。
val joinExpr = person.col("graduate_program") === graduateProgram.col("id")
person.join(broadcast(graduateProgram), joinExpr).explain()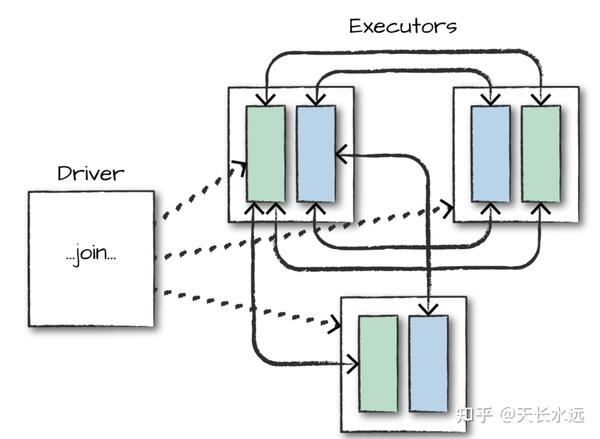
Data Source
Spark有6个核心的数据源:CSV, JSON, Parquet, ORC, JDBC/ODBC connections, Plain-text files.
下面是读取数据的核心API,这里format是optional的,默认为Parquet。
DataFrameReader.format(...).option("key", "value").schema(...).load()
spark.read读取数据时难免遇到mal-formated数据,read mode用来指定当遇到这些数据时怎么处理,默认为permissive。


下面是写数据的核心API,这里format是optional的,默认为Parquet。
DataFrameWriter.format(...).option(...).partitionBy(...).bucketBy(...).sortBy(
...).save()
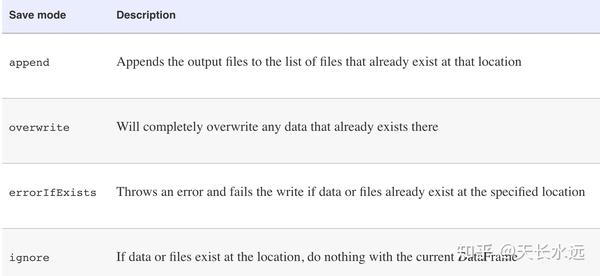
dataFrame.write写数据时可以指定save mode,默认为errorIfExists。
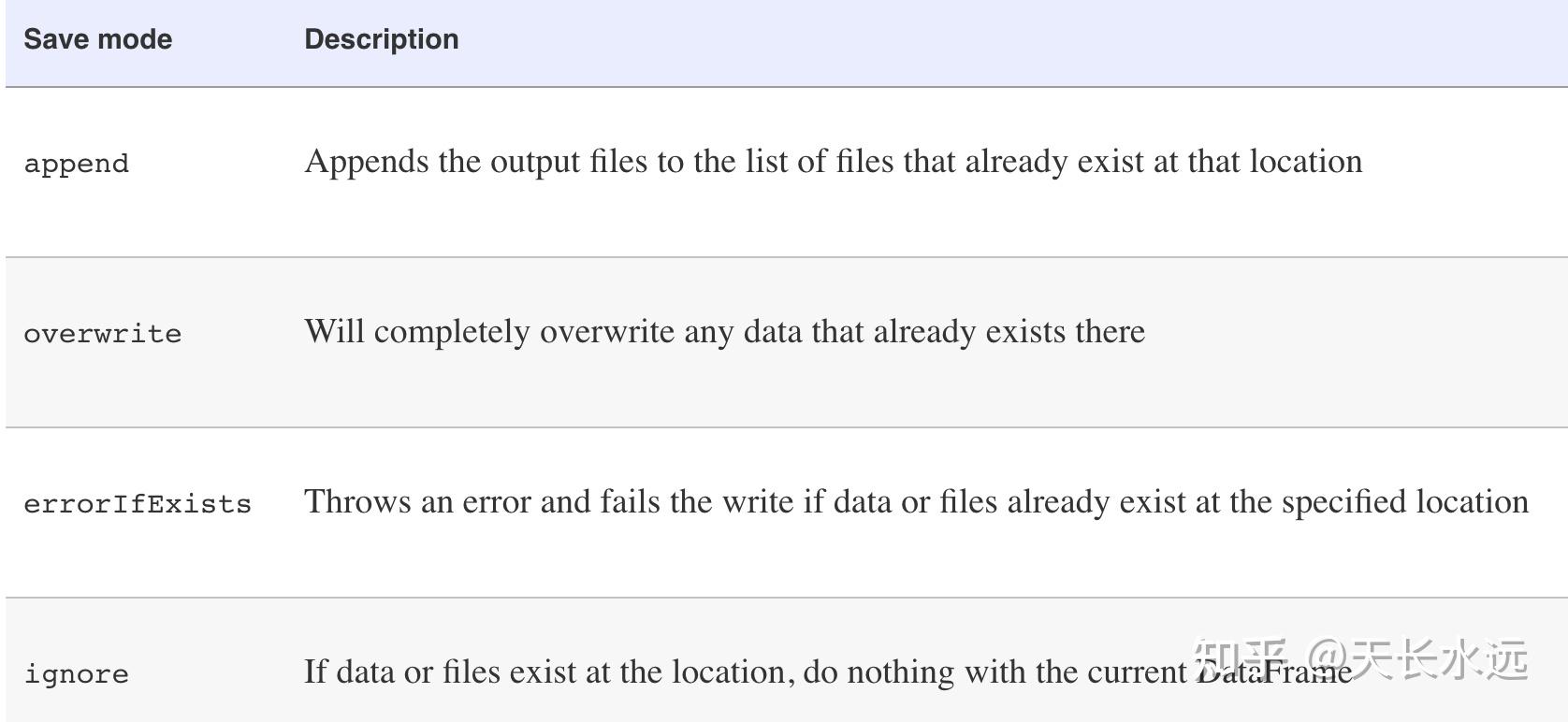
-CSV
CSV表示commma-separated values。
下面是读写CSV文件的代码示例。
spark.read.format("csv")
.option("header", "true")
.option("mode", "FAILFAST")
.option("inferSchema", "true")
.load("some/path/to/file.csv")
val csvFile = spark.read.format("csv")
.option("header", "true")
.option("mode", "FAILFAST")
.schema(myManualSchema)
.load("/data/flight-data/csv/2010-summary.csv")常用的option:

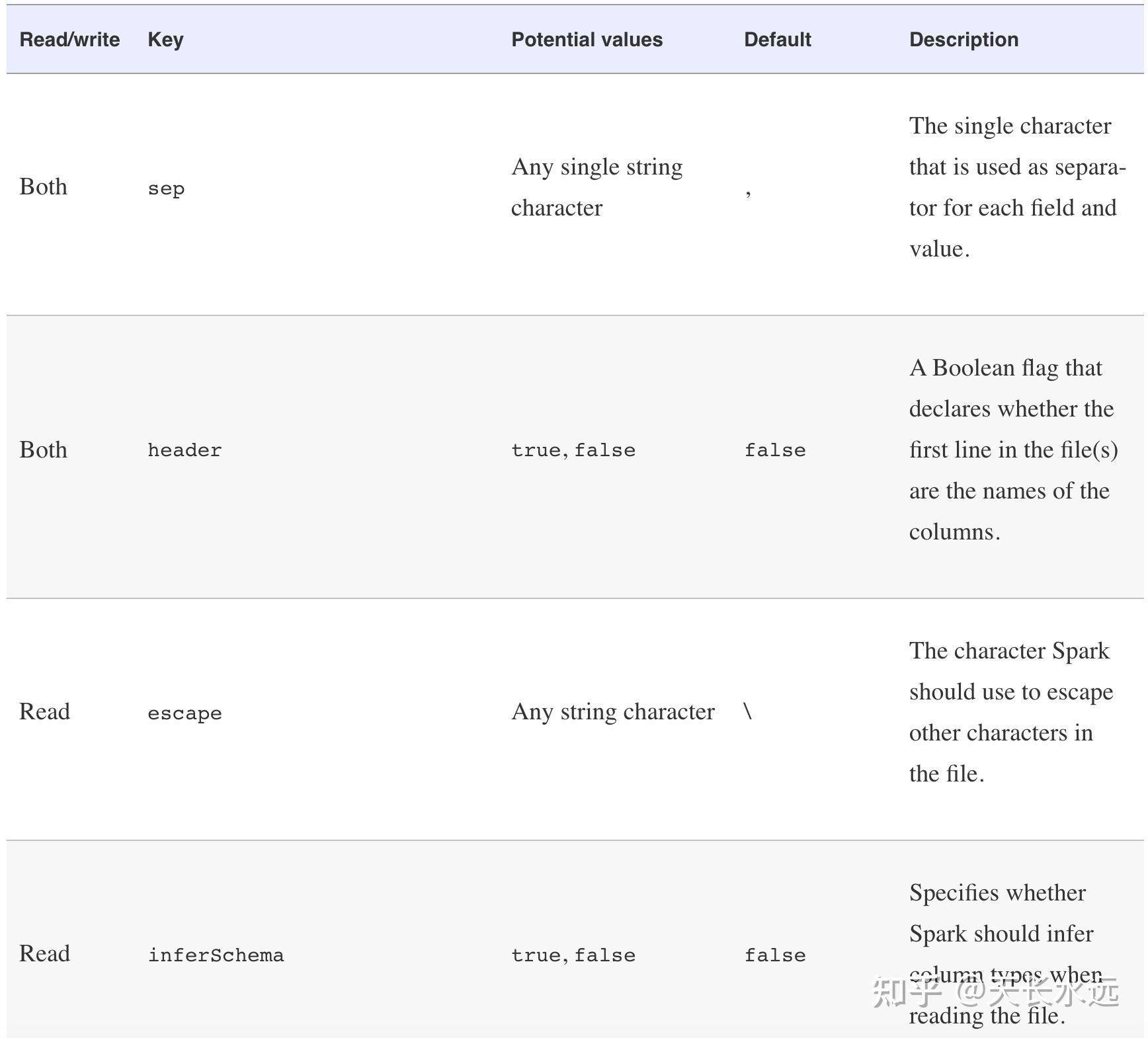
-JSON
下面是读写JSON的代码示例。
spark.read.format("json").option("mode", "FAILFAST").schema(myManualSchema)
.load("/data/flight-data/json/2010-summary.json").show(5)
csvFile.write.format("json").mode("overwrite").save("/tmp/my-json-file.json")-Parquet
Parquet是开源的基于列的数据存储,提供很多数据存储的优化,尤其是分析数据的负载均衡。Parquet允许列式压缩,允许读取单个column而不用读取整个文件。推荐使用Parquet来保存数据,因为读取Parquet数据效率比CSV,JSON性能好。同时,Parquet对复杂数据类型支持更好。Parquet files中保存schema信息。
下面是读写Parquet的代码示例。
spark.read.format("parquet")
.load("/data/flight-data/parquet/2010-summary.parquet").show(5)
csvFile.write.format("parquet").mode("overwrite")
.save("/tmp/my-parquet-file.parquet")

-ORC
ORC是一种自描述,type-aware的列文件格式,对于large streaming read进行了优化。ORC与Parquet很像,只是Parquet针对Spark进行优化,而ORC针对Hive进行优化。
下面是读写ORC格式数据文件的代码示例。
spark.read.format("orc").load("/data/flight-data/orc/2010-summary.orc").show(5)
csvFile.write.format("orc").mode("overwrite").save("/tmp/my-json-file.orc")-SQL Databases
SQL用来连接各种不同的SQL databases。这种方式option比较多,下面是常用的几种。


使用SQL database需要设置连接属性,下面是读写SQL database的代码示例。需要自己先验证提供的连接属性是否能连接到database。
val pgDF = spark.read
.format("jdbc")
.option("driver", "org.postgresql.Driver")
.option("url", "jdbc:postgresql://database_server")
.option("dbtable", "schema.tablename")
.option("user", "username").option("password","my-secret-password").load()
pgDF.select("DEST_COUNTRY_NAME").distinct().show(5)
val pushdownQuery = """(SELECT DISTINCT(DEST_COUNTRY_NAME) FROM flight_info)
AS flight_info"""
val dbDataFrame = spark.read.format("jdbc")
.option("url", url).option("dbtable", pushdownQuery).option("driver", driver)
.load()
val props = new java.util.Properties
props.setProperty("driver", "org.sqlite.JDBC")
val predicates = Array(
"DEST_COUNTRY_NAME = 'Sweden' OR ORIGIN_COUNTRY_NAME = 'Sweden'",
"DEST_COUNTRY_NAME = 'Anguilla' OR ORIGIN_COUNTRY_NAME = 'Anguilla'")
spark.read.jdbc(url, tablename, predicates, props).show()
val newPath = "jdbc:sqlite://tmp/my-sqlite.db"
csvFile.write.mode("overwrite").jdbc(newPath, tablename, props)-Text Files
下面是读写text file的代码示例。
spark.read.textFile("/data/flight-data/csv/2010-summary.csv")
.selectExpr("split(value, ',') as rows").show()
csvFile.limit(10).select("DEST_COUNTRY_NAME", "count")
.write.partitionBy("count").text("/tmp/five-csv-files2.csv")Executors可以并行的从多个文件中读取数据,写入时生成的文件数量依赖于DataFrame当时的partition数量,默认每个partition生成一个文件。
保存数据时按指定column进行partition保存,使得数据以每个column value作为文件夹名称进行保存。这样,读取特定column value只会读取相应文件夹下的数据文件。
csvFile.limit(10).write.mode("overwrite").partitionBy("DEST_COUNTRY_NAME")
.save("/tmp/partitioned-files.parquet")
$ ls /tmp/partitioned-files.parquet
DEST_COUNTRY_NAME=Costa Rica/
DEST_COUNTRY_NAME=Egypt/
DEST_COUNTRY_NAME=Equatorial Guinea/
DEST_COUNTRY_NAME=Senegal/
DEST_COUNTRY_NAME=United States/Bucketing是另一种文件组织方式,用来控制数据写入指定文件,避免读取数据时shuffe,因为具有相同bucket id的数据写入相同的physical partition。
val numberBuckets = 10
val columnToBucketBy = "count"
csvFile.write.format("parquet").mode("overwrite")
.bucketBy(numberBuckets, columnToBucketBy).saveAsTable("bucketedFiles")并不是所有文件类型都支持复杂类型,Parquet和ORC支持复杂类型,CSV不支持。
我们需要控制数据文件大小,当存在很多小文件时,Spark和Hadoop不能很好处理,但当文件很大时,并行度不高,性能差。可以使用option maxRecordsPerFile来控制每个文件中record数量来控制文件大小。
df.write.option("maxRecordsPerFile", 5000)Spark SQL
在Spark出现之前,Hive作为大数据的SQL访问层,可以使用SQL来操作大数据。Spark 2.0之后,提供native SQL parser来支持ANSI-SQL以及HiveQL。现在大量用户使用Spark SQL来使用Spark。
Spark SQL和Hive具有很大关系,因为Spark SQL可以连接Hive metastores。Hive metastores是Hive跨session保存table information的方式。
Spark提供多种接口来执行SQL query,但最常用的还是Spark SQL编程接口。
spark.read.json("/data/flight-data/json/2015-summary.json")
.createOrReplaceTempView("some_sql_view") // DF => SQL
spark.sql("""
SELECT DEST_COUNTRY_NAME, sum(count)
FROM some_sql_view GROUP BY DEST_COUNTRY_NAME
""")
.where("DEST_COUNTRY_NAME like 'S%'").where("`sum(count)` > 10")
.count() // SQL => DFSpark SQL中最高级的抽象是Catalog,存放table数据的metadata以及其他有用信息,如database, table, view, functions.
Table逻辑上等价于DataFrame,区别是DataFrame在编程语言中定义,而Table在database中定义。Spark 2.x中,table中总是包含数据,没有临时表的概念,只有view中可以不包含数据。
Table分为managed table和unmanaged table,前者保存table data和table metadata,后者只保存table data. 定义在disk files上的table只保存数据,而DataFrame上执行saveAsTable创建managed table。默认情况下,table数据保存在默认的Hive warehouse location /user/hive/warehouse,可以在创建SparkSession时指定spark.sql.warehouse.dir来设置。
下面是创建table的代码示例。USING指定格式,OPTIONS指定配置。也可以从query中创建table。
CREATE TABLE flights (
DEST_COUNTRY_NAME STRING, ORIGIN_COUNTRY_NAME STRING, count LONG)
USING JSON OPTIONS (path '/data/flight-data/json/2015-summary.json')
CREATE TABLE flights_csv (
DEST_COUNTRY_NAME STRING,
ORIGIN_COUNTRY_NAME STRING COMMENT "remember, the US will be most prevalent",
count LONG)
USING csv OPTIONS (header true, path '/data/flight-data/csv/2015-summary.csv')
CREATE TABLE flights_from_select USING parquet AS SELECT * FROM flights
CREATE TABLE IF NOT EXISTS flights_from_select AS SELECT * FROM flights
CREATE TABLE partitioned_flights USING parquet PARTITIONED BY (DEST_COUNTRY_NAME)
AS SELECT DEST_COUNTRY_NAME, ORIGIN_COUNTRY_NAME, count FROM flights LIMIT 5对于External table,Spark只管理其metadata,不负责管理数据文件。下面是创建external table的代码示例。
CREATE EXTERNAL TABLE hive_flights (
DEST_COUNTRY_NAME STRING, ORIGIN_COUNTRY_NAME STRING, count LONG)
ROW FORMAT DELIMITED FIELDS TERMINATED BY ',' LOCATION '/data/flight-data-hive/'
CREATE EXTERNAL TABLE hive_flights_2
ROW FORMAT DELIMITED FIELDS TERMINATED BY ','
LOCATION '/data/flight-data-hive/' AS SELECT * FROM flights写入table使用insert,可以指定要写入的partition。
INSERT INTO flights_from_select
SELECT DEST_COUNTRY_NAME, ORIGIN_COUNTRY_NAME, count FROM flights LIMIT 20
INSERT INTO partitioned_flights
PARTITION (DEST_COUNTRY_NAME="UNITED STATES")
SELECT count, ORIGIN_COUNTRY_NAME FROM flights
WHERE DEST_COUNTRY_NAME='UNITED STATES' LIMIT 12显示table schema:
DESCRIBE TABLE flights_csv
SHOW PARTITIONS partitioned_flightsRefresh table将更新所有缓存的entry。Repair table用于更新catalog中维护的partition信息。
REFRESH table partitioned_flights
MSCK REPAIR TABLE partitioned_flights不能delete table,只能drop table,若是managed table, data和metadata都被删除;若是unmanaged table,data不会被删除,但不能通过该table name访问这些数据。drop不存在的table会抛异常。
DROP TABLE flights_csv;
DROP TABLE IF EXISTS flights_csv;tablek也被cache和uncache。
CACHE TABLE flights
UNCACHE TABLE FLIGHTSView指定table上的一系列transformations,Spark只在query时执行。View可以是global的,database的,也可以是session相关的。Temp view只在当前session有效,并没有注册到database. Global temp view在整个spark application中可见并在session结束前删除。
Drop view只会删除view definition,并不会删除data。
CREATE VIEW just_usa_view AS
SELECT * FROM flights WHERE dest_country_name = 'United States'
CREATE TEMP VIEW just_usa_view_temp AS
SELECT * FROM flights WHERE dest_country_name = 'United States'
CREATE GLOBAL TEMP VIEW just_usa_global_view_temp AS
SELECT * FROM flights WHERE dest_country_name = 'United States'
CREATE OR REPLACE TEMP VIEW just_usa_view_temp AS
SELECT * FROM flights WHERE dest_country_name = 'United States'
EXPLAIN SELECT * FROM flights WHERE dest_country_name = 'United States'
DROP VIEW IF EXISTS just_usa_view;Database用来组织table,若定义table时没指定database,使用default database。
SHOW DATABASES
CREATE DATABASE some_db
USE some_db
SHOW tables
SELECT * FROM flights
SELECT * FROM default.flights
SELECT current_database()
DROP DATABASE IF EXISTS some_db;下面是SELECT的语法。
SELECT [ALL|DISTINCT] named_expression[, named_expression, ...]
FROM relation[, relation, ...]
[lateral_view[, lateral_view, ...]]
[WHERE boolean_expression]
[aggregation [HAVING boolean_expression]]
[ORDER BY sort_expressions]
[CLUSTER BY expressions]
[DISTRIBUTE BY expressions]
[SORT BY sort_expressions]
[WINDOW named_window[, WINDOW named_window, ...]]
[LIMIT num_rows]CASE WHEN THEN END语法:
SELECT
CASE WHEN DEST_COUNTRY_NAME = 'UNITED STATES' THEN 1
WHEN DEST_COUNTRY_NAME = 'Egypt' THEN 0
ELSE -1 END
FROM partitioned_flights复杂数据类型。collect_list函数用于生成value list,collect_set用来生成value set,都只能在aggregation时使用,其值可以使用数组方式访问。可以使用explode函数将数组展平。
CREATE VIEW IF NOT EXISTS nested_data AS
SELECT (DEST_COUNTRY_NAME, ORIGIN_COUNTRY_NAME) as country, count FROM flights
SELECT * FROM nested_data
SELECT country.DEST_COUNTRY_NAME, count FROM nested_data
SELECT country.*, count FROM nested_data
SELECT DEST_COUNTRY_NAME as new_name, collect_list(count) as flight_counts,
collect_set(ORIGIN_COUNTRY_NAME) as origin_set
FROM flights GROUP BY DEST_COUNTRY_NAME
SELECT DEST_COUNTRY_NAME, ARRAY(1, 2, 3) FROM flights
SELECT DEST_COUNTRY_NAME as new_name, collect_list(count)[0]
FROM flights GROUP BY DEST_COUNTRY_NAME
SELECT explode(collected_counts), DEST_COUNTRY_NAME FROM flights_agg下面命令展示所有Functions。Spark SQL中可以直接调用UDF。
SHOW FUNCTIONS
SHOW SYSTEM FUNCTIONS
SHOW USER FUNCTIONS
SHOW FUNCTIONS "s*";
SHOW FUNCTIONS LIKE "collect*";
def power3(number:Double):Double = number * number * number
spark.udf.register("power3", power3(_:Double):Double)
SELECT count, power3(count) FROM flightsSpark SQL中可以使用subquery,分为Uncorrelated subquery和Correlated subquery。前者在inner query中不使用outer query的信息,而后者使用。
SELECT * FROM flights
WHERE origin_country_name IN (SELECT dest_country_name FROM flights
GROUP BY dest_country_name ORDER BY sum(count) DESC LIMIT 5)
SELECT * FROM flights f1
WHERE EXISTS (SELECT 1 FROM flights f2
WHERE f1.dest_country_name = f2.origin_country_name)
AND EXISTS (SELECT 1 FROM flights f2
WHERE f2.dest_country_name = f1.origin_country_name)Dataset
当使用DataFrame时,object被encoder成Row。当使用Dataset时,Spark将Row转化为使用case class或Java class表示的object。这种转化会影响性能但能提供更多灵活性。
使用Dataset而不是DataFrame只有2种场景:1. 需要使用特定函数encode而不是DataFrame的方式;2. Dataset是type-safe的,编译时就能识别出类型问题,不用等待运行时。
Java方式创建Dataset:
import org.apache.spark.sql.Encoders;
public class Flight implements Serializable{
String DEST_COUNTRY_NAME;
String ORIGIN_COUNTRY_NAME;
Long DEST_COUNTRY_NAME;
Dataset<Flight> flights = spark.read
.parquet("/data/flight-data/parquet/2010-summary.parquet/")