|
00000000 <main>:
#include <cstdio>
int main()
{
0: 55 push %ebp
1: 89 e5 mov %esp,%ebp
3: 83 e4 f0 and $0xfffffff0,%esp
6: 83 ec 30 sub $0x30,%esp
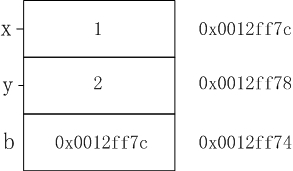
int x=1;
9: c7 44 24 28 01 00 00 movl $0x1,0x28(%esp)
将
1赋值给
x(
x在堆栈的
0x28处)
10: 00
int y=2;
11: c7 44 24 24 02 00 00 movl $0x2,0x24(%esp)
将
2赋值给
y(
y在堆栈的
0x24处)
18: 00
int &b=x;
19: 8d 44 24 28 lea 0x28(%esp),%eax
将
x的地址
0x28 传给寄存器
%eax
1d: 89 44 24 2c mov %eax,0x2c(%esp)
将
%eax的值赋给堆栈
0x2c处(这儿比较重要)
printf("&x=%x,&y=%x,&b=%x,b=%x\n",&x,&y,&y-1,*(&y-1));
21: 8d 44 24 24 lea 0x24(%esp),%eax
将堆栈
0x24处的地址传给寄存器
%eax
25: 83 e8 04 sub $0x4,%eax
将
%eax的值减掉
4
28: 8b 10 mov (%eax),%edx
将寄存器
%eax中地址所指向的内容传给寄存器
%edx
2a: 8d 44 24 24 lea 0x24(%esp),%eax
将堆栈
0x24处的地址传给寄存器
%eax
2e: 83 e8 04 sub $0x4,%eax
将
%eax的值减掉
4
31: 89 54 24 10 mov %edx,0x10(%esp)
将
%edx的内容传给堆栈
0x10处
35: 89 44 24 0c mov %eax,0xc(%esp)
将
%eax的内容传给堆栈
0xc处
39: 8d 44 24 24 lea 0x24(%esp),%eax
将堆栈
0x24处的地址传给寄存器
%eax
3d: 89 44 24 08 mov %eax,0x8(%esp)
将
%eax的内容传给堆栈
0x8处
41: 8d 44 24 28 lea 0x28(%esp),%eax
将堆栈
0x28处的地址传给寄存器
%eax
45: 89 44 24 04 mov %eax,0x4(%esp)
将
%eax的内容传给堆栈
0x4处
49: c7 04 24 00 00 00 00 movl $0x0,(%esp)
50: e8 fc ff ff ff call 51 <main+0x51>
return 0;
55: b8 00 00 00 00 mov $0x0,%eax
}
5a: c9 leave
5b: c3 ret
|