


Python进阶笔记(二)Python内存管理(CPython解释器 底层变量模型、引用计数器、标记清除、分代回收、缓存机制)

前言
作为一个具有GC(Garbage Collection)的动态脚本语言,了解其内存管理机制必定是熟练掌握Python这门语言后期绕不开的一个弯。这不仅对我们编写代码具有启发作用(比如为什么常量使用tuple会比list更快),也能够在学习其他语言时猜测其GC的实现方式,做到一通百通。
所以这篇文章作为锦恢的第二篇Python进阶笔记,我想谈谈Python中非常重要的垃圾回收机制和在垃圾回收机制中涉及到的一点点优化方式,也就是缓存机制。
准备
在Python中,万物皆对象,就算是我们数字1,字符串'a',也都是对象,通过type函数可以查看一个对象所属的类:
>>> a = 1
>>> type(a)
<class 'int'>
>>> a = 'a'
>>> type(a)
<class 'str'>在C++和C中,堆上开辟的空间是需要手动释放的,否则会造成内存泄漏,但是在Python和现存几乎所有的主流开发语言中,我们都不需要手动释放对象所占用的内存,编程语言运行时内部的GC机制会自动释放对象占用的空间。
所以Python内部是如何实现这样一套GC的机制的呢?想要搞清楚这个问题,首先需要了解Python的对象在底层的存储方式。锦恢下面的说明全都基于CPython解释器来进行讲解,版本为3.11.0 alpha 3。GitHub上下载比较慢,幸好有好心人在gitee上拷贝了一份,克隆下方链接的项目即可获取构建跨平台CPython解释器的项目:
Python所有对象的C实现
在CPython源代码中,所有的Python对象,也就是object,是通过PyObject这个结构体实现的,去除宏后的C代码如下(Include/object.h)
typedef struct _object {
struct _object *_ob_next;
struct _object *_ob_prev;
Py_ssize_t ob_refcnt;
PyTypeObject *ob_type;
} PyObject;其中_ob_next和_ob_prev代表两个PyObject类型的指针;ob_refcnt是当前这个Python对象的引用计数器,通过它能够快速实现最简单的GC;ob_type则是一个描述对象类型的结构体。
我们的int,float,str等基本的变量类型都是基于PyObject实现的(相当于C++中的类的派生,基本都是在结构体中再加入一个原生C语言的数据类型)
但是很显然,PyObject是无法描述容器类型的数据类型的,所以CPython中还定义了能够派生出容器类的结构体PyVarObject,实现如下:
typedef struct {
PyObject ob_base;
Py_ssize_t ob_size; /* Number of items in variable part */
} PyVarObject;可以看到,与PyObject相比,PyVarObject加入了描述当前容器内变量数量的变量。
而基本容器类list,tuple,dict,set都是基于PyVarObject实现的
Python管理对象的底层模型——循环双向链表
通过上一节我们看到对于任何一个Python对象,都至少需要使用四个量来描述它:
- 指向上一个PyObject对象的指针
- 指向下一个PyObject对象的指针
- 引用计数器
- 对象类型
大一学得扎实的同学看到了结构体中塞双指针可能DNA就要动了,这不就是双向链表的实现吗?确实,Python底层所有的对象会存储在一个双向链表中,不过这个链表是首尾相连的循环双向链表。
我们可以举个例子,假设我们现在在单个Python进程中创建了如下几个变量:
a = 1
b = "hello"
c = 3.14
d = c那么在底层,Python的这几个PyObject对象会被穿成如下这个首尾相连的链子:

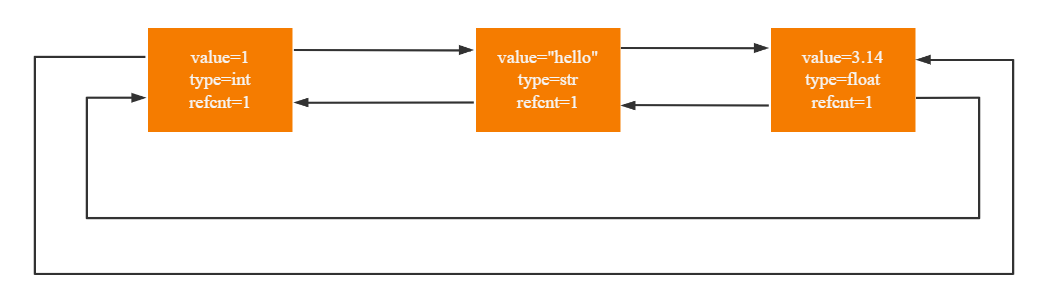
value代表值,type代表类型,refcnt代表引用数。(这几个量并不是真正的C代码中的变量名,只是笔者为了抽象而定义的)
通过这个链表,CPython可以很方便地对底层真正分配内存的变量进行管理。而实际上,Python会将上述三个真正存储内容的对象(1对象,"hello"对象,3.14对象)在堆上开辟空空间并创建它们,而我们的a,b,c都是创建在栈上的变量,实际上都是对相应堆上对象的引用,所以其实只存储着对应的堆对象在堆上的位置。因此整个Python变量的底层模型如下图所示:

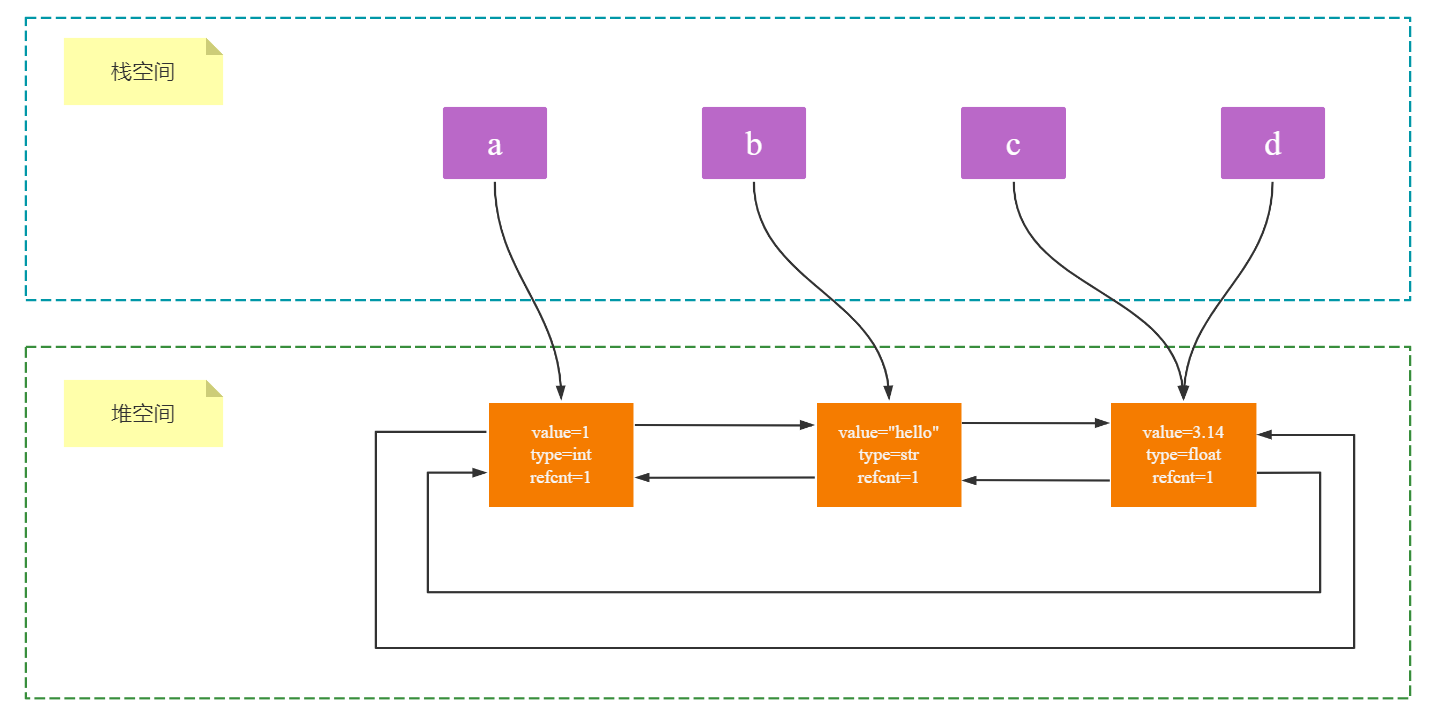
引用计数器
几乎所有含有GC的编程语言都会使用这项技术对类进行管理,这也能解决80%以上的自动回收的情况。它的基本思想很简单,在每个对象创立之初时,就将引用计数器refcnt初始化为1,每被引用一次,就将refcnt加1,引用它的变量每少一个,就将refcnt减1。如果一个对象的refcnt为0,说明这个对象不再被任何变量引用,那么解释器就会销毁该对象并释放该对象占用的内存。
通过Python内置库sys的函数getrefcount可以获取当前变量引用的底层对象被引用的次数。需要注意的是,由于传入的对象在函数getrefcount内部也被用到了一次,所以实际引用次数应该是sys.getrefcount() - 1
我们可以来试试:
>>> import sys
>>> a = 3.14
>>> sys.getrefcount(a) - 1
>>> b = a
>>> sys.getrefcount(a) - 1
>>> del b
>>> sys.getrefcount(a) - 1
>>> del a你会发现如果a赋值为比较小的整数或者单个字符串,getrefcount会返回很不正常的数字,这个在Python缓存中会解释
通过del删除变量后,我们会发现引用数确实变小了,当a和b都被删除后,float对象3.14的refcnt变为0,这个对象会从refchain中被移除并释放占用的空间。
通过这样的方式,CPython可以高效地对我们创建的对象进行管理,并自动释放没有用的对象。
只是这样就行了吗?。。。这么做是有bug的。
标记清除
在上一节中,锦恢埋下了一个伏笔,那就是只通过引用计数器来做对象的自动销毁是有bug的,比如下面这个情形:
>>> a = [1,2]
>>> b = [3,4]
>>> a.append(b)
>>> b.append(a)
>>> sys.getrefcount(a) - 1
>>> sys.getrefcount(b) - 1
2可以看到,此时a和b的引用计数器分别都是2,那么我们接下来分别删除a和b,也就是del a, del b,那么按照之前的规则,a和b的refcnt分别都减一,从2变成1,但是此时明明已经没有任何变量引用它们了,那两个列表对象此时应该被销毁,但是它们的refcnt并没有变为0,这就是发生了错误。
这种容器对象相互引用的现象我们称为 循环引用 ,很明显,引用计数器是无法解决循环引用的问题的,那么我们应该如何解决呢?
其实也很简单,我们想一下,当我们del b的时候,因为b中有a的一部分,那部分其实也构成了对a的一个索引,所以我们需要在del b时同时让a的refcnt减一。为了达到这样的效果,我们需要一个额外的数据结构来保存那些可能具有循环引用的对象,通过之前的分析,我们已经知道了在Python中,只有容器类对象才会存在循环引用,因此CPython解释器会将可能存在循环引用的对象(当然都是新创建的容器对象啦)放入一个新的循环双向链表中,而不是之前的refchain,他们的refcnt的增加操作与refchain中对象的refcnt的增加逻辑完全相同,也就是被引用,就将refchain加一。
为了防止循环引用,该链表中并不直接依据refcnt的值对对象进行释放,而是 周期性地 使用标记清除的算法进行变量地自动销毁。标记清除算法会将整个栈变量和堆变量一起建模成一个有向图,在删除了部分栈空间中的变量后,解释器会从遍历栈变量,从每个栈变量开始遍历整个有向图(这些栈变量也被称为root_object),被遍历到的节点会被标记为可达(reachable),在所有栈变量被遍历完后,整个有向图中未被标记为可达的节点对应的堆变量会被销毁释放。
锦恢尝试用manim动画还原了一个例子的底层执行过程,请过目:
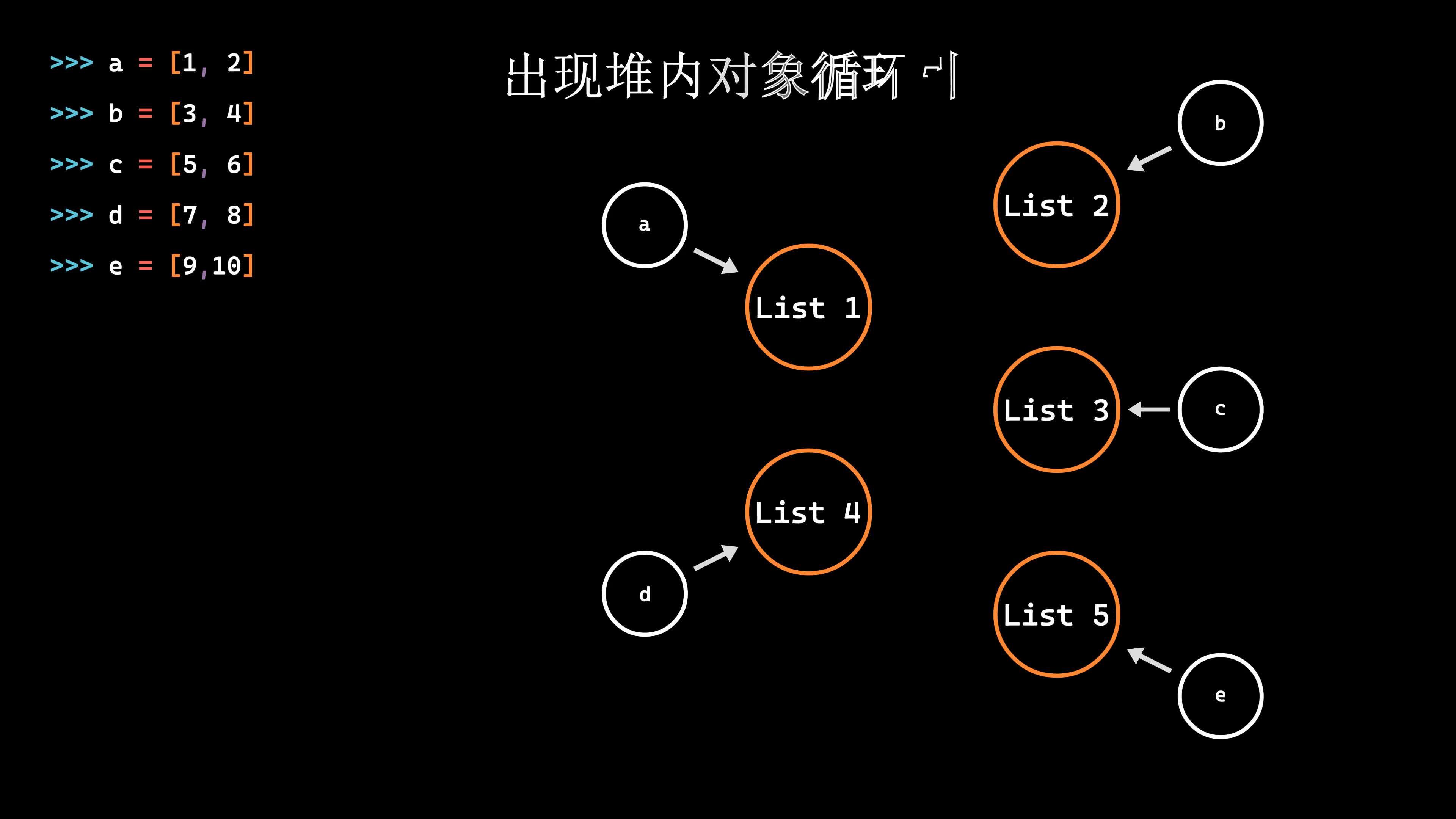 标记清除算法的manim动画演示
https://www.zhihu.com/video/1474187525892304896
标记清除算法的manim动画演示
https://www.zhihu.com/video/1474187525892304896
整个过程下来肯定会有同学发牢骚了:CPython这底层的销毁也太低效了吧:(
诚然,CPython的清除标记算法需要遍历整个栈空间和几乎整个堆空间,在变量较多的情况下是非常耗时的。因此,我们不可能在链表每次发生变动之后就直接使用一次标记清除算法。那么我们应该多久使用一次标记清除算法呢?
于是乎,CPython引入了 分代回收 的机制来规定了标记清除算法的使用周期,并对这个过程进行了一点点优化。
分代回收
分代回收技术将上一节中存放可能存在循环引用的对象的链表拆成了三个链表——0代,1代和2代,每一代都是一个循环双向链表。所有的可能存在循环引用的对象都会被存在这三个链表中。
那么如何将那些变量存入这三个链表中呢?标记清除的使用周期又是如何规定的呢?规则如下:
| 代数 | 标记清除使用周期 | 升代与回收规则 |
|---|---|---|
| 0代 | 0代中对象个数达到700个使用一次标记清除算法 | 标记为可达的编入1代,未可达的销毁 |
| 1代 | 0代使用了10次标记清除后1代使用一次标记清除算法 | 标记为可达的编入2代,未可达的销毁 |
| 2代 | 1代使用了10次标记清除后2代使用一次标记清除算法 | 标记为未可达的销毁 |
需要说明的是,分代回收的标记清除是向下兼容的——如果第i(i>0)代执行了标记清除算法,那么所有代小于i的链表也需要执行标记清除算法。比如说,如果当前判定2代链表需要执行标记清除算法,那么0代和1代也需要执行。
Python变量缓存机制
这个小节的缓存机制和上面所讲的所有内容不是一个层面上的优化,变量缓存也是对Python底层变量管理的一种优化,但是其优化的方面主要在于内存的申请上和管理上。
对于Python缓存机制的了解可以解释许多“奇怪”的Python的现象,所以这算是实用性最强的一节。
在之前的底层变量模型中,我们对Python创建一个变量有了比较清楚的认识:比如我们写下a=3.14,那么实际上Python首先会为堆空间申请一段内存空间,再用这段空间创建一个浮点类对象3.14,并在栈空间创建变量a,让a指向堆空间的浮点类对象3.14。如果3.14的refcnt变为0,那么Python会将3.14销毁并释放占用的空间。
这样的模式存在一定的缺点——如果我们频繁地申请内存空间并归还内存空间,很容易造成内存碎片,导致内存管理地低效。为了优化这个问题,CPython解释器引入了缓存机制,缓存机制中的技术主要有两项:
- 变量池:启动Python解释器时,会为一些常用的变量(比如较小的整数,较短的字符串)创建一个常量变量池。
- free_list:refcnt为0或者被判定为需要销毁的对象,不会立刻执行销毁并释放占用内存,而是会存入对应变量类型的free_list列表中。
很明显,这两项技术分别从申请内存和释放内存的角度出发,来尝试优化。锦恢下面就尝试来解释一下。
许多例子在Python3.7+上貌似不适用了,也就是说Python内部又作了一些优化,所以下面锦恢的目的只是在于帮助大家建立对Python内存缓冲机制的感性认识。
变量池
由于部分的常量我们会经常使用,直接在解释器初始化时就将它们创建在内存中可以使得后续的使用更加高效,在锦恢尝试后,这些变量主要有:
- -5到256的整数
- 单个ASSIC字符
- Boolean变量
我们可以通过下述的代码来验证这个机制:
>>> a = -5
>>> b = -5
>>> a is b
TruePython中的 is 关键字用于判断两个栈变量指向的是否是同一个堆变量,可以看到,由于-5是[-5,256]的整数,这个整数在解释器进程创建后就在内存中创建了,所以a=-5与b=-5都只是让栈中的a和b指向堆中预先创建好的-5对象。与之相对,我们来看一个例子:
>>> a = 1312
>>> b = 1312
>>> a is b
False这次是False了,因为1312不在区间[-5,256]之间,所以解释器看到a=1312后需要在堆中先开辟一段空间,再创建一个新的1312对象;对于b=1312同理也需要创建一个新的1312对象,那么两个在不同时间开辟内存的变量当然是堆上的两个不同的对象,所以a is b输出False
我再来给出几个例子,读者可以看看自己是否能够给出解释,如果可以,那么说明你对Python的变量池理解明白了:
>>> a = 3
>>> b = 3
>>> a is b
>>> a = 3.14
>>> b = 3.14
>>> a is b
False
>>> a = 'a'
>>> b = 'a'
>>> a is b
>>> a = '我'
>>> b = '我'
>>> a is b # 我不是ASSIC字符
False
>>> a = True
>>> b = True
>>> a is b
Truefree_list
这一节会告诉你为什么tuple比list更加高效
频繁地释放内存也会使得内存使用效率变低,那么我们干脆不释放了!
在CPython中,被判定为需要销毁的对象并不会直接从堆上抹除,而是从refchain中拿出来,再放入对应数据类型的free_list中,比如:
a = 3.14
del a那么对象3.14会移到float类的free_list中。
如果我们下面再创建一个新的浮点数对象,那么解释器不会去给堆空间申请新的内存空间,而是直接从float类的free_list中直接去找一个被“遗弃”的之前创建好,但是refcnt已经成0的对象,然后将refcnt赋为1,重新赋值后再加入refchain中。这样一来一回,刚好省去了一次释放内存和申请内存的时间开销。
再比如:
b = [1,2,3]
del b那么列表对象就会被移到list类的free_list中。和之前一样,等到我们创建新的列表时,解释器会优先去free_list找可用的列表对象而非申请新的内存。
每一个不同的数据类型的free_list的预设的大小都是不同的,比如float的free_list最多存储100个float对象;list的free_list最多存储80个list对象;dict 的 free_list 最多存储80个 dict 对象;tuple比较特殊,是以每个tuple的大小为key按照类似于哈希映射的机制将tuple存入free_list中的。
其中对于不同的数据类型还存在不同的一些优化的机制,比如str对象存在一种驻留机制,如果要创建一个新的字符串,且该字符串只含字母,数字和下划线,那么解释器会优先去refchain中去找,是否已经创建了该值的字符串,如果创建了,那么直接将栈变量指向当前的堆变量即可,否则申请内存,创建。举个例子:
>>> a = "kjawhfuih1431u4h1iehr1"
>>> b = "kjawhfuih1431u4h1iehr1"
>>> a is b
True你会发现a和b指向的堆变量是一样的,这是因为在创建b的那一句,解释器发现值为"kjawhfuih1431u4h1iehr1"的str对象已经存在于内存中了,那么不创建了,直接用现成的。需要说明:
- 这个机制中字符串不能有空格和非ASSIC字符,只能是字母,数字和下划线的组合:
>>> a = "hello world"
>>> b = "hello world"
>>> a is b
False2. 该机制与变量池中单个字符表现形式一样,但是是属于两个不同的机制,比如下面这两个例子虽然都输出True,但是请注意他们属于不同的两种机制:
>>> a = "a"
>>> b = "a"