由于网站属于静态网页,很容易就能获取到想要的内容,所以爬取过程就不详细介绍。
直接上代码:
import requests
from bs4 import BeautifulSoup as bs
import threading
import queue
class get_history(threading.Thread):
def __init__(self,task_q,result_q):
super().__init__()
self.task_queue=task_q
self.result_queue=result_q
def run(self):
while True:
if not self.task_queue.empty():
page=self.task_queue.get()
one_result=self.crawl(page)
self.result_queue.put(one_result)
self.task_queue.task_done()
print('##第{}页爬取完毕~~~~~'.format(page))
else:
break
def crawl(self,page):
url = 'http://www.lottery.gov.cn/historykj/history_{}.jspx?_ltype=dlt'.format(page)
headers = {
'user-agent': 'Mozilla / 5.0(Windows NT 10.0;Win64;x64) AppleWebKit / 537.36(KHTML, likeGecko) Chrome / 75.0.3770.142Safari / 537.36',
'Upgrade-Insecure-Requests': '1',
'Host': 'www.lottery.gov.cn'
r = requests.get(url, headers=headers)
text = bs(r.text, 'lxml')
result = text.find_all('div', class_='result')
result = result[0].find_all('tbody')
result = result[0].find_all('td')
result_list = []
for item in result:
result_list.append(item.get_text())
one_page=[]
one_page.append([result_list[19]] + result_list[0:8])
for i in range(1, 20):
open_data = result_list[19 + (20 * i)]
number_list = result_list[20 + (20 * (i - 1)):21 + (20 * (i - 1)) + 7]
one_page.append([open_data] + number_list)
return one_page
if __name__ == '__main__':
task_queue=queue.Queue()
result_queue=queue.Queue()
for i in range(1,94):
task_queue.put(i)
crawl=get_history(task_queue,result_queue)
crawl.setDaemon(True)
crawl.start()
task_queue.join()
with open('history.txt','a') as f :
while not result_queue.empty():
for one in result_queue.get():
one_line=''
for item in one:
one_line+=item
f.write(one_line+'\n')
由于最近多线程和队列用的比较多,所以这里一开始就也想用多线程+队列,但是后来发现,因为本身网页就是静态的获取数据非常简单,加上总共也才90多页,根本不需要多线程,单线程就能很快爬完。既然写了就当作对多线程和队列的巩固练习吧~
将爬取到的数据保存到history.txt
总共获取到了1860条数据,每条就是一期开奖结果,相当于1860期,从2007年到2019年十二年来的开奖数据。
利用pyecharts进行可视化分析
from collections import Counter
from pyecharts.charts import Bar,Page
from pyecharts import options as opts
def number_analyse():
red_balls = []
blue_balls = []
with open('history.txt', 'r') as f:
for i in range(1860):
oneLine_data = f.readline().strip()
red_balls.extend([int(oneLine_data[15 + (2 * i):15 + (2 * (i + 1))]) for i in range(5)])
blue_balls.append(int(oneLine_data[-4:-2]))
blue_balls.append(int(oneLine_data[-2:]))
red_counter = Counter(red_balls)
blue_counter = Counter(blue_balls)
print(red_balls)
print(blue_balls)
print(red_counter)
print(blue_counter)
print(red_counter.most_common())
print(blue_counter.most_common())
red_dict={}
blue_dict={}
for i in red_counter.most_common():
red_dict['{}'.format(i[0])]=i[1]
for j in blue_counter.most_common():
blue_dict['{}'.format(j[0])]=j[1]
print(red_dict)
print(blue_dict)
red_list=sorted(red_counter.most_common(),key=lambda number:number[0])
blue_list=sorted(blue_counter.most_common(),key=lambda number:number[0])
print(red_list)
print(blue_list)
red_bar=Bar()
red_x=['{}'.format(str(x[0])) for x in red_list]
red_y=['{}'.format(str(x[1])) for x in red_list]
red_bar.add_xaxis(red_x)
red_bar.add_yaxis('红色球出现次数',red_y)
red_bar.set_global_opts(title_opts=opts.TitleOpts(title='大乐透彩票',subtitle='近12年数据'),toolbox_opts=opts.ToolboxOpts()
,yaxis_opts=opts.AxisOpts(axislabel_opts=opts.LabelOpts(formatter="{value}/次")),
xaxis_opts=opts.AxisOpts(name='开奖号码'))
red_bar.set_series_opts(markpoint_opts=opts.MarkPointOpts(
data=[opts.MarkPointItem(type_='max',name='最大值'),opts.MarkPointItem(type_='min',name='最小值')]
blue_bar=Bar()
blue_x=['{}'.format(str(x[0])) for x in blue_list]
blue_y=['{}'.format(str(x[1])) for x in blue_list]
blue_bar.add_xaxis(blue_x)
blue_bar.add_yaxis('蓝色球出现次数',blue_y,itemstyle_opts=opts.ItemStyleOpts(color='blue'))
blue_bar.set_global_opts(title_opts=opts.TitleOpts(title='大乐透彩票',subtitle='近12年数据'),toolbox_opts=opts.ToolboxOpts()
,yaxis_opts=opts.AxisOpts(axislabel_opts=opts.LabelOpts(formatter="{value}/次")),
xaxis_opts=opts.AxisOpts(name='开奖号码'))
blue_bar.set_series_opts(markpoint_opts=opts.MarkPointOpts(
data=[opts.MarkPointItem(type_='max',name='最大值'),opts.MarkPointItem(type_='min',name='最小值')]
page=Page(page_title='大乐透历史开奖数据分析',interval=3)
page.add(red_bar,blue_bar)
page.render('大乐透历史开奖数据分析.html')
最后将图表保存到“大乐透历史开奖数据分析.html”,然后使用浏览器打开
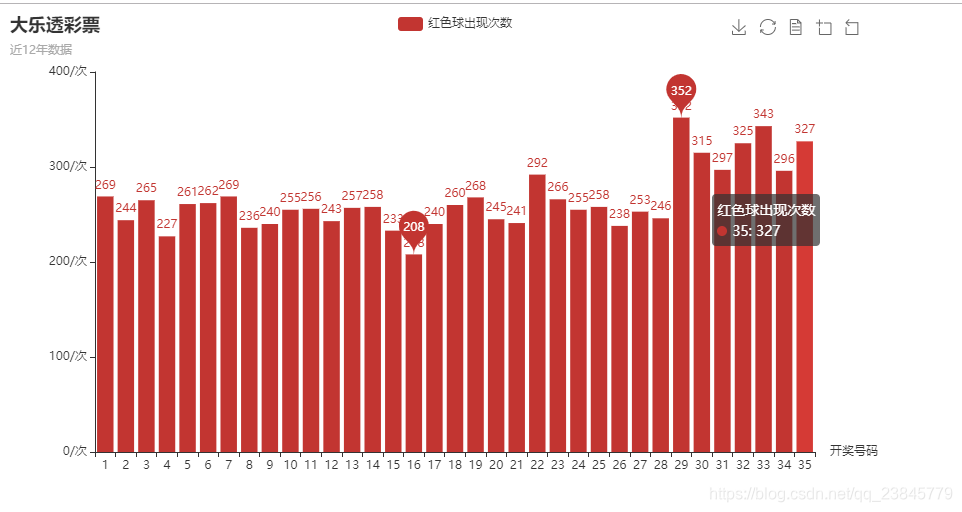
可以看到红色球中出现次数最多的是29,总共出现了352次,出现最少的是16,共出现了208次。
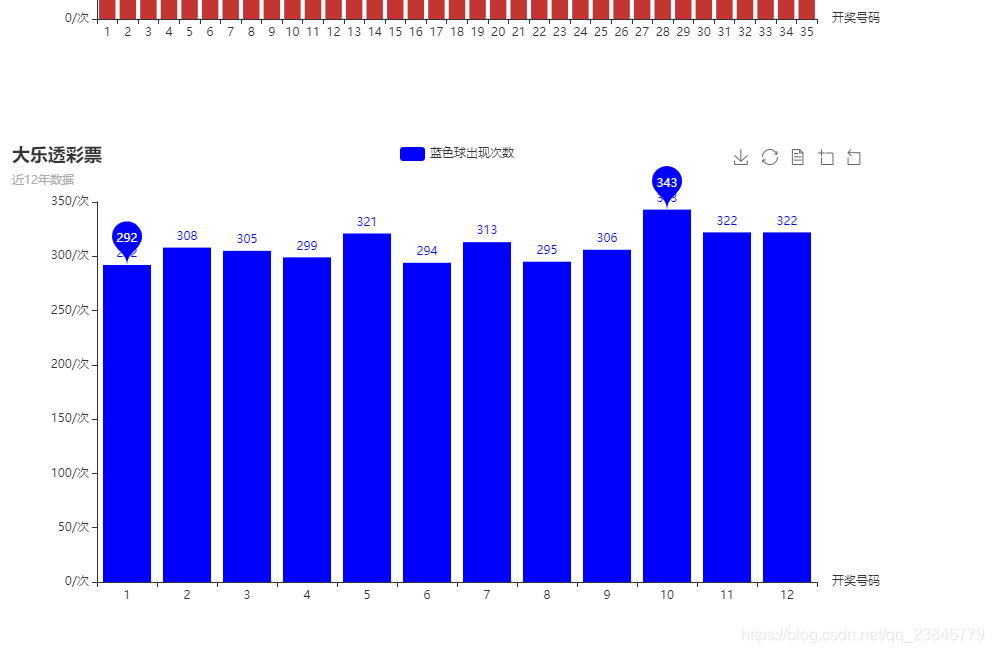
而蓝色球出现最多的是10,共出现343次,出现最少的是1,共出现292次。
关于sklearn的使用参考这篇文章:https://blog.csdn.net/lilianforever/article/details/53780613
一组开奖号码有7个数字,所以分别建立了7个模型,每个位置的开奖号码为一个模型,使用每期的开奖日期和期数当作特征值,每个位置的开奖号码数字为标签直对模型进行训练。
之后对每个模型分别输入下一期开奖日期和期号进行预测每个位置的号码,然后将7个号码组合起来就是最后预测的开奖号码。
from sklearn import svm
def forecast():
data=[]
period=[]
first_num=[]
second_num=[]
third_num=[]
fourth_num=[]
fifth_num=[]
sixth_num=[]
seventh_num=[]
with open('history.txt', 'r') as f:
for i in range(1860):
oneLine_data = f.readline().strip()
data.append(int(oneLine_data[0:10].replace('-','')))
period.append(int(oneLine_data[10:15]))
first_num.append(int(oneLine_data[15:17]))
second_num.append(int(oneLine_data[17:19]))
third_num.append(int(oneLine_data[19:21]))
fourth_num.append(int(oneLine_data[21:23]))
fifth_num.append(int(oneLine_data[23:25]))
sixth_num.append(int(oneLine_data[25:27]))
seventh_num.append(int(oneLine_data[27:29]))
x=[]
for j in range(len(data)):
x.append([data[j],period[j]])
first_model=svm.SVR(gamma='auto')
second_model=svm.SVR(gamma='auto')
third_model=svm.SVR(gamma='auto')
fourth_model=svm.SVR(gamma='auto')
fifth_model=svm.SVR(gamma='auto')
sixth_model=svm.SVR(gamma='auto')
seventh_model=svm.SVR(gamma='auto')
model_list=[first_model,second_model,third_model,fourth_model,fifth_model,sixth_model,seventh_model]
y_list=[first_num,second_num,third_num,fourth_num,fifth_num,sixth_num,seventh_num]
for k in range(7):
model_list[k].fit(x,y_list[k])
res_list=[]
for model in model_list:
res=model.predict([[20190803,19089]]).tolist()
res_list.append(res)
print(res_list)
forecast()
得到下期的预测号码:

关于深度学习,我也没学过,对于一些算法、原理我也暂时还不是很懂。这里只是稍微了解了一下就选了个模型直接进行使用。如果要更加严谨的操作,需要对多个模型进行交叉验证,选择出最优模型,和对模型做进一步调优,这里就不折腾了(其实是还不会)
这个预测彩票其实并不靠谱,原因我想大家都懂的~,而且开奖号码跟期数和开奖日期并没有半点相关性,用开奖期数+开奖日期来进行深度学习和预测本来就是毫无意义的事情。就当是娱乐娱乐的同时巩固和练习相关的python知识。
但是偶尔花个8块10块买个几注彩票(千万不要沉迷~)还是可以的,万一哪天踩了狗屎运中了,说不定就此改变命运 ~,俗话说梦想还是要有的,万一实现了呢!
废话不多说,先从获取历史开奖数据开始我们从中国体彩网爬取历史开奖数据。由于网站属于静态网页,很容易就能获取到想要的内容,所以爬取过程就不详细介绍。直接上代码:import requestsfrom bs4 import BeautifulSoup as bsimport threadingimport queueclass get_history(threading.Thre...
step1,安装anaconda(可参考https://zhuanlan.zhihu.com/p/32925500);
step2,创建一个conda环境,conda create -n your_env_name python=3.6;
step3,进入创建conda的环境 conda activate your_env_name,然后执行pip install -r requirements.txt;
step4,按照Getting Started执行即可,推荐使用PyCharm
Getting Started
python get_data.py --name ssq # 执行获取双色球训练数据
如果出现解析错误,应该看看网页 http://datachart.500.com/ssq/history/newinc/history.php 是否可以正常访问 若要大乐透,替换参数 --name dlt 即可
python run_train_model.py --name ssq # 执行训练双色球模型
开始模型训练,先训练红球模型,再训练蓝球
Python可以用来预测彩票大乐透,但是彩票的中奖结果是完全随机的,没有任何模式可言。因此,用Python预测彩票大乐透的中奖号码并没有特别的方法或技巧。
然而,我们可以使用Python编写一个程序来生成大乐透的随机组合,以提供给彩票购买者一个参考。可以利用Python的随机数生成函数来生成随机的大乐透号码。例如,可以使用"random"库中的"randint"函数生成1至35之间的5个随机号码作为前区号码,再使用同样的函数生成1至12之间的2个随机号码作为后区号码。
虽然使用Python生成随机号码并不能提高中奖的概率,但对于没有确定号码选择的彩票购买者来说,这个程序可以提供一种参考方法,帮助他们选择号码。
需要注意的是,购买彩票是一种娱乐活动,而非投资方式。在购买彩票时,应该理性对待,并且只花得起的闲置资金进行购买。无论使用任何方法,都没有办法确保中奖,彩票中奖概率极低,可能性非常小。因此,彩票购买者应该保持理性和节制。
open_data = result_list[19 + (20 * i)]
number_list = result_list[20 + (20 * (i - 1)):21 + (20 * (i - 1)) + 7]
one_page.append([open_data] + number_list)
except:
print("爬至末页,已无数据!")
然后第58行for循环的上限调整为大于103的数值:for i in range(1,103):就可以爬取到所有的数据

