


利用python进行相关性分析

相关性分析是指通过对变量的分析,判定两个变量因素的相关程度,然后通过对其中一个因素的引导,来影响另一个因素。
需要注意是,一般讨论的相关性分析均指代“线性相关性”。
假设我们通过分析发现,用户的网页浏览行为和用户的购买行为呈现较强的正相关性,那么理论上,产品运营同学通过引导用户浏览更多的网页便可以带来更多的购买订单数,进而提升平台的收入。
那么怎么判定两者是否存在正相关关系呢?
用户在网页上留下了行为数据,我们随机选取了100组数据(X,Y),X为用户的浏览数据(日浏览门店数量),Y为用户的购买数据(日购买商品数)。
判定两者相关的方式有两种:
- 图形观测法:通过绘制散点图判断两者是否存在一定相关关系
- 科学计算法:通过计算相关性系数r
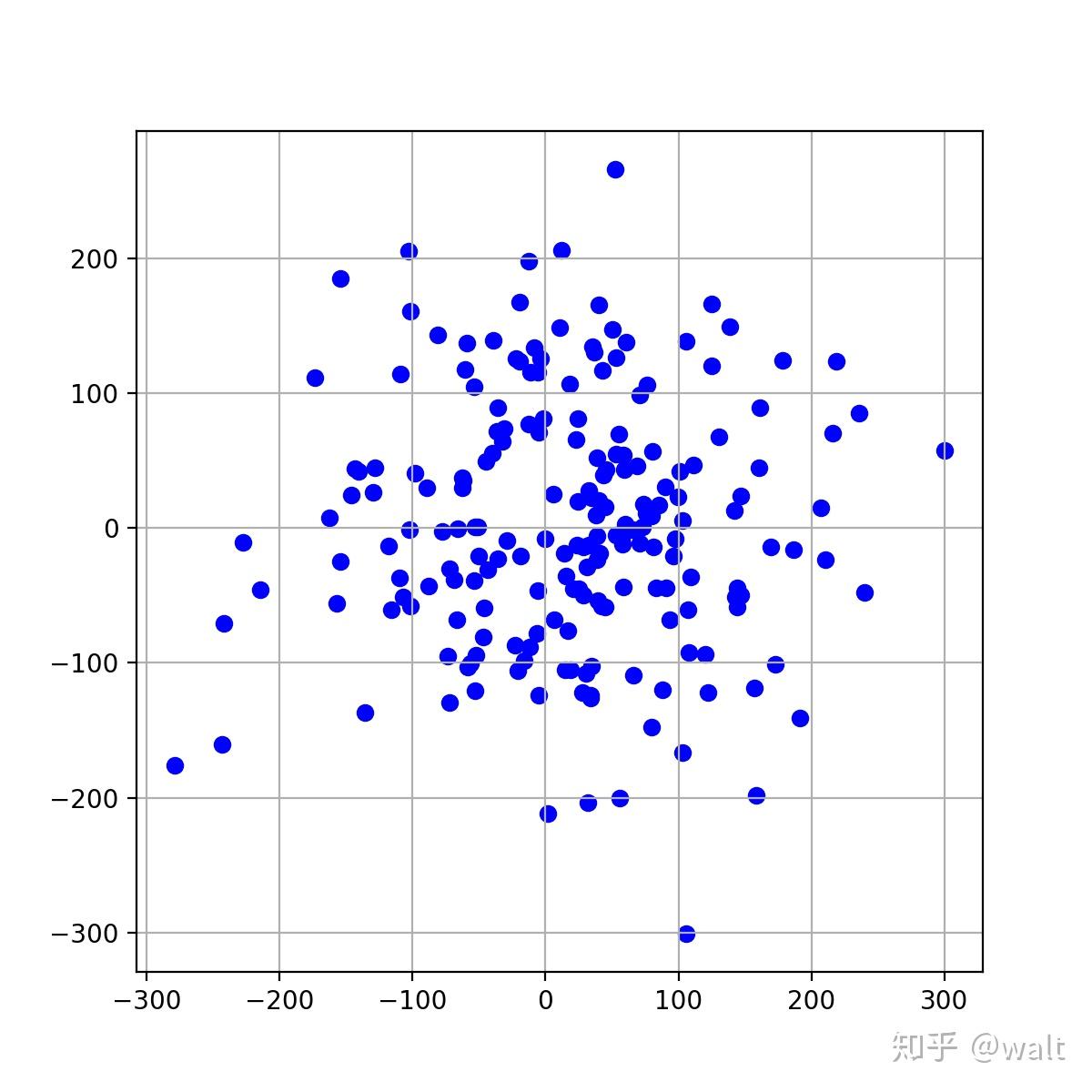
图形观测法 可以通过python直接绘制散点图来实现,形象可见,但是无法数据化。
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
# 随机生成一组数据(X,Y)
data = pd.DataFrame(np.random.randn(200,2)*100, columns=['X','Y'])
# 绘制散点图
plt.figure(figsize = (6,6)) # 图片像素大小
plt.scatter(data.X, data.Y,color="blue") # 散点图绘制
plt.grid() # 显示网格线
plt.show() # 显示图片
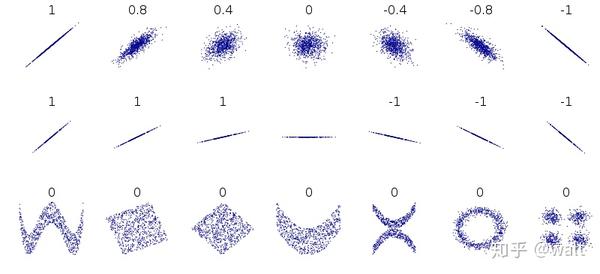
科学计算法 也可以通过python直接实现,但需要注意的是,该方法会得到两个指标:1)相关性系数r;2)显著性水平p。
两者的关系为:当p<0.05(或者0.01)的前提下,才可以参考r值,不能仅仅只看r值。
假设p=0.02,r=0.8,认为两组数据存在高度线性关系
假设p=0.5,r=0.8,认为两组数据不能进行相关性比较,更别提相关性是高还是低(此时的相关性表现可能是巧合)
好奇的商业分析师会问:什么是r?什么是p?为什么需要他们?
具体原因请参考: walt:说人话系列-相关性
# -----------------------------
# |r|<0.3 不存在线性关系
# 0.3<|r|<0.5 低度线性关系
# 0.5<|r|<0.8 显著线性关系
# |r|>0.8 高度线性关系
# ------------------------------
import numpy as np
import pandas as pd
import scipy.stats as stats
data = pd.DataFrame(np.random.randn(200,2)*100, columns=['X','Y'])
r,p = stats.pearsonr(data.X,data.Y) # 相关系数和P值
print('相关系数r为 = %6.3f,p值为 = %6.3f'%(r,p))得到:相关系数r为 = 0.021,p值为 = 0.766。
对于多维数据,需要计算两两之间的相关性
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import scipy.stats as stats
# 导入数据