-
一开始拼接的xml如下:
<?xml version ="1.0" encoding="UTF-8"?>
<S:Envelope xmlns:S='http://schemas.xmlsoap.org/soap/envelope/'>
<S:Body>
<n:uploadTestData xmlns:n="http://localhost:8080/TPService/TPServicePort?wsdl">
<a>test</a>
</n:uploadTestData>
</S:Body>
</S:Envelope>
-
此时代码大概如下:
import requests
from requests.structures import CaseInsensitiveDict
url = 'http://localhost:8080/TPService/TPServicePort?wsdl'
headers = CaseInsensitiveDict()
headers['Content-Type'] = 'text/xml'
payload = ‘’‘
<?xml version ="1.0" encoding="UTF-8"?>
<S:Envelope xmlns:S='http://schemas.xmlsoap.org/soap/envelope/'>
<S:Body>
<n:uploadTestData xmlns:n="http://localhost:8080/TPService/TPServicePort?wsdl">
<a>test</a>
</n:uploadTestData>
</S:Body>
</S:Envelope>
response = requests.post(url, headers=headers, data=payload, timeout=5)
print(response.status_code)
-
然后这时会报错500如下:
Couldn't create SOAP message due to exception: XML reader error: javax.xml.stream.XMLStreamException: ParseError at [row,col]:[2,14]
Message: The processing instruction target matching "[xX][mM][lL]" is not allowed.
com.sun.xml.ws.protocol.soap.MessageCreationException: Couldn't create SOAP message due to exception: XML reader error: javax.xml.stream.XMLStreamException: ParseError at [row,col]:[2,14]
-
按照提示,找到[2, 14]的位置,发现是xml version这里,去掉两个单词之间的空格,再次请求,报错500,但是服务端没有信息显示。
-
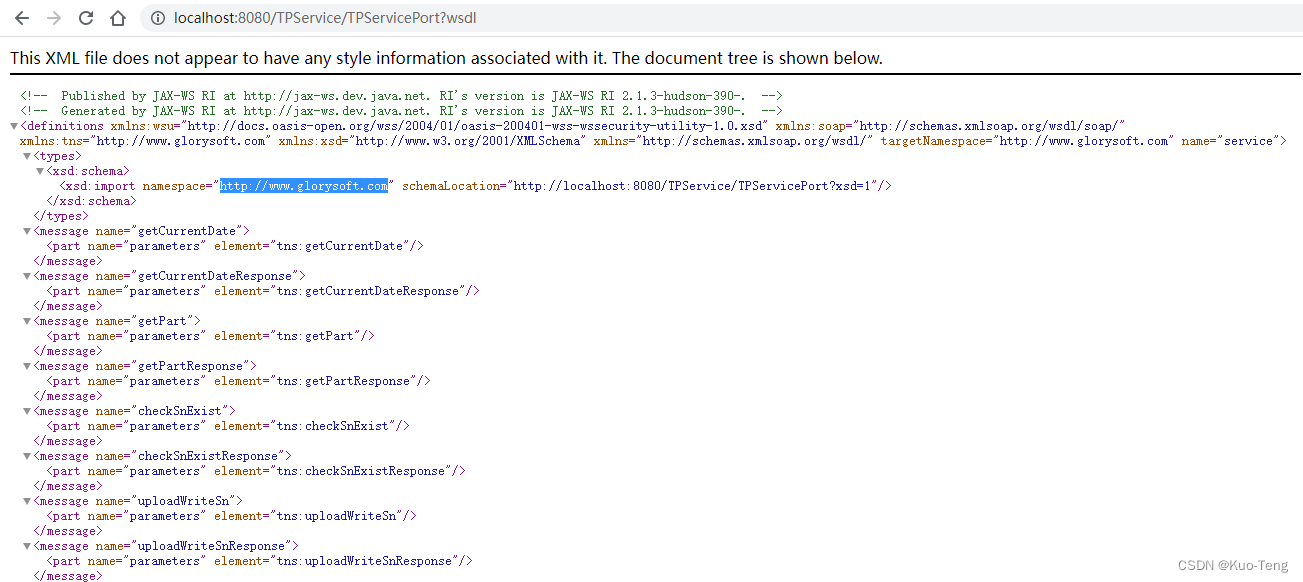
发现是请求地址写错了,请求地址应与localhost:8080/TPService/TPServicePort?wsdl中的namespace保持一致。将代码修改为:
import requests
from requests.structures import CaseInsensitiveDict
url = 'http://localhost:8080/TPService/TPServicePort?wsdl'
headers = CaseInsensitiveDict()
headers['Content-Type'] = 'text/xml'
payload = ‘’‘
<?xml version ="1.0" encoding="UTF-8"?>
<S:Envelope xmlns:S='http://schemas.xmlsoap.org/soap/envelope/'>
<S:Body>
<n:uploadTestData xmlns:n="http://www.xxxx.com">
<a>test</a>
</n:uploadTestData>
</S:Body>
</S:Envelope>
response = requests.post(url, headers=headers, data=payload, timeout=5)
print(response.status_code)
-
再次发起请求,返回结果如下:
<?xml version="1.0" ?>
<S:Envelope xmlns:S="http://schemas.xmlsoap.org/soap/envelope/">
<S:Body>
<ns2:uploadTestDataResponse xmlns:ns2="http://www.glorysoft.com">
<return> {"responseDate":"20210420114103554","resultCode":"OK","resultMessage":"success"}
</return>
</ns2:uploadTestDataResponse>
</S:Body>
</S:Envelope>
说明成功进行了通信。