原来的interactions_train_df.head()
users_items_pivot_matrix_df = interactions_train_df.pivot(index='personId',
columns='contentId',
values='eventType_strength').fillna(0)
users_items_pivot_matrix_df.head(10)
这里矩阵中values用eventType_strength填
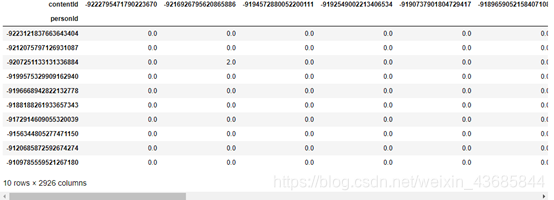
通常在做矩阵分解时,需要将原始数据转换为这种user-item矩阵格式
python pandas 库的dataframe pivot()函数用法解析:
简而言之,我理解的pivot()的用途就是,将一个dataframe的记录数据整合成表格(类似Excel中的数据透视表功能),而且是按照pivot(‘index=xx’,’columns=xx’,’values=xx’)来整合的。还有另外一种写法,
但是官方貌似并没有给出来,就是pivot(‘索引列’,‘列名’,‘...
pivot函数的说明
通过给定的索引(index)和列(column)的值重新生一个DataFrame对象。
根据列值对数据进行整形(生成一个“透视”表)。从指定的索引/列中使用唯一的值来形成结果数据帧的轴。此函数不支持数据聚合,多个值将导致列中的多索引。
pivo函数的参数
index:指定一列做为生成DataFrame对象的索引,如果为空则
大家好,今天和大家分享中四种有关数据透视的通用函数,在数据处理中遇到这类需求时,能够很好地应对。获取函数的主要作用是将从宽格式转换成长格式。参数含义:tuple, list, or ndarray,可选,作为标识符变量的列:tuple, list, or ndarray, 可选,透视列,如果未指定,则使用未设置为id_vars的所有列。:scalar,默认为None,使用variable作为列名:标量, default ‘value’,value列的名称:...
fill_value : 用来替换透视表的缺失值scalar, default None
margins : 添加所有行,列,例如在后面加个“总和”boolean, default False
dropna : 不要包含条目都是NaN的列boolean
文章目录十、数据透视表1.获取数据2.手工制作数据透视表3.数据透视表语法4.案例:美国人的生日
十、数据透视表
数据透视表将每一列数据作为输入,输出将数据不断细分成多个维度累计信息的二维数据表。
1.获取数据
本节用一份Seaborn 程序库采用泰坦尼克号的乘客信息数据库来演示(titanic)
2.手工制作数据透视表
使用groupby可以实现数据透视的效果,但是比较繁琐
3.数据透视表语...
最近在做基于python的数据分析工作,引用第三方数据分析库——pandas。
在做数据统计二维表转换的时候走了不少弯路,发现pivot()这个方法可以解决很多问题,让我少走一些弯路,节省了大量的代码。于是我这里对于pandas下dataframe的pivot()方法进行学习总结和应用,以便回顾和巩固知识。

