


带你入门 Java Persistence API


背景
JPA(Java Persistence API)是 Java EE 标准中的一部分,它通过提供提供一套对象关系模型(ORM)来帮助在开发应用过程中高效的管理关系型数据。和 JDBC 一样,JPA 本身只是一套标准接口,目前比较成熟的 JPA 实现有 Hibernate 、 EclipseLink 等。
聊聊 ORM
在进一步介绍 JPA 之前,先聊聊对象关系模型 ORM,既然前面说它是帮助我们更高效的管理关系型数据,那么在没有 ORM 的情况下,我们如果使用 JDBC 进行数据库操作的话是怎么样的呢?
package me.leozdgao.demo.jdbc;
import java.sql.*;
public class Application {
public final static String JDBC_URL = "jdbc:mysql://localhost:3306/learnjdbc";
public final static String JDBC_USER = "root";
public final static String JDBC_PASSWORD = "******";
public static void main(String[] args) {
try (Connection connection = DriverManager.getConnection(JDBC_URL, JDBC_USER, JDBC_PASSWORD)) {
try (PreparedStatement ps = connection.prepareStatement("SELECT id, grade, name, gender FROM students WHERE gender=? AND grade=?")) {
ps.setObject(1, "M");
ps.setObject(2, 3);
try (ResultSet rs = ps.executeQuery()) {
while (rs.next()) {
Student student = new Student();
student.setId(rs.getLong("id"));
student.setGrade(rs.getLong("grade"));
student.setName(rs.getString("name"));
student.setGender(rs.getString("gender"));
// 后续处理逻辑...
} catch (Exception e) {
e.printStackTrace();
我们可以看到,直接使用 JDBC 进行数据库操作的话:
- 需要手动控制 Connection、PreparedStatement、ResultSet 等实例的生命周期
- 每次执行都必须手动拼写 SQL 并设置变量,较为繁琐,代码维护成本高
- 每次执行结果都需要手动转换为业务层的类,以便适配后续的业务逻辑处理
那么面对上述代码繁琐的问题,我们肯定可以通过编写一些 DbUtils 类来将繁琐的逻辑进行封装,或者针对某个特定的实体类,来针对性的编写访问数据库进行读写的方法。
更进一步 ORM 是解决上述问题的通用解决方案,对象关系模型通过声明式的手段声明实体类,定义了实体类中字段与数据库字段的映射关系,以及实体类之间的关系,并基于这些关系提供了遍历的管理实体进行读写的操作,可以在大部分场景下不再需要手动编写 SQL。
那么接下来就通过一个例子来进一步介绍 JPA,例子中 JPA 的实现使用的是 Hibernate。
JPA 0-1 实战
首先我们给我们的项目引入必要的依赖,这里使用的版本是 JPA 2.2 和 Hibernate 5.3.7.final:
<dependencies>
<dependency>
<groupId>javax.persistence</groupId>
<artifactId>javax.persistence-api</artifactId>
<version>2.2</version>
</dependency>
<dependency>
<groupId>org.hibernate</groupId>
<artifactId>hibernate-core</artifactId>
<version>5.3.7.Final</version>
</dependency>
</dependencies>
JPA 配置
JPA 的配置需要定义在文件 META-INF/persistence.xml 中,一份简单的定义是这样的:
<persistence xmlns="http://xmlns.jcp.org/xml/ns/persistence" version="2.2">
<persistence-unit name="PERSISTENCE">
<description>Hibernate JPA Demo</description>
<provider>org.hibernate.jpa.HibernatePersistenceProvider</provider>
<properties>
<property name="javax.persistence.jdbc.Driver"
value="com.mysql.cj.jdbc.Driver"/>
<property name="javax.persistence.jdbc.url"
value="jdbc:mysql://localhost:3306/classicmodels" />
<property name="javax.persistence.jdbc.user"
value="root" />
<property name="javax.persistence.jdbc.password"
value="******" />
<property name="hibernate.show_sql"
value="true" />
<property name="hibernate.hbm2ddl.auto"
value="validate"/>
</properties>
</persistence-unit>
</persistence>
我们需要配置一个 persistence-unit 来对应一个持久化目标及其配置,我们通过 provider 来配置具体使用哪个 JPA 的实现,由于我们选择了 Hibernate,于是我们配置 org.hibernate.jpa.HibernatePersistenceProvider 这个类的全限定名。同时还可以定义一些属性来配置这个持久化目标的行为,在标准中定义了 JPA 标准属性,其中就包括和数据库的连接:
- javax.persistence.jdbc.Driver :定义使用哪一个 JDBC Driver。
- javax.persistence.jdbc.url :代表数据库连接的 JDBC URL。
- javax.persistence.jdbc.user :连接数据库的用户。
- javax.persistence.jdbc.password :连接数据用户的密码。
persistence.xml
文件的定义以及 JPA 标准属性,可以直接参考 JSR 338(JPA 2.2)标准的 8.2.1 节的内容。
每个 JPA 的实现可以有一些自己额外的属性,比如在例子中用到了 Hibernate 的属性配置:
- hibernate.show_sql:在执行过程中输出执行的 SQL 语句,便于调试。
- hibernate.hb2ddl.auto:实体元信息与数据库表结构同步机制,可选的值包括:
- create-drop:每次启动都会根据实体元信息定义重新生成表,并在生命周期结束时删除表,通常仅用于测试环境。
- create:每次启动都会根据实体元信息定义重新生成表,应用的重启就会造成数据丢失。
- update:每次启动都会根据实体元信息定义更新存量的表(没有则创建)。
- valdiate:校验实体元信息与数据库表结构是否匹配,不匹配则直接报错,生产环境可以通过这个配置来检验当前部署的代码是否和数据库结构匹配。
hibernate.hb2ddl.auto 是一个挺危险的配置,设置出错很有可能直接导致因为数据库表被删除造成的数据丢失问题,基本成熟的公司都会有一套数据库结构变更和数据变更的管控系统,所以如果希望关闭这个功能,可以将值设置为 none。
关于 Hibernate 可以配置的属性,可以参考它的 官方文档 。
JPA 模块组成
通过上面一份简单的配置,我们的准备工作就已经可以了,在编写代码之前,我们对 JPA 提供的功能模块做一个概览:
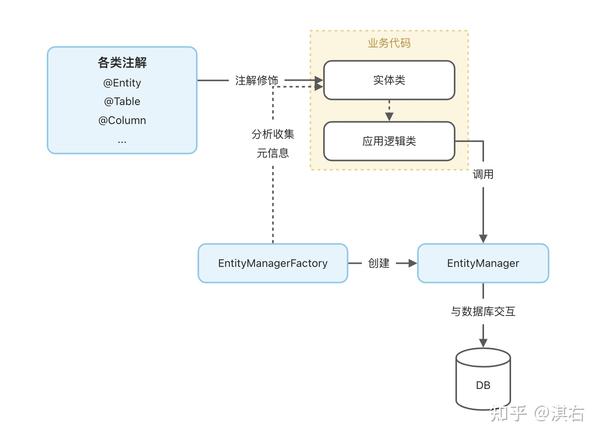
- EntityManager:对应了一个持久化上下文,通过这个上下文中的方法,就可以实现和数据库的交互,是使用 JPA 过程中最常用的 API。
-
EntityManagerFactory:对应了一个 persistence-unit,用于创建 EntityManager,和 EntityManager
是一对多关系。 - 实体元数据配置:定义了实体类字段与数据库表结构字段的映射关系,支持通过 XML 或者 Java 注解的方式定义,后续的例子都采用注解的方式。
同时也可以看出 JPA 提供的 ORM 能力是基于 Data Mapper Pattern 的思想设计的,将实体的设计和具体的数据库行为解耦,由一个 EntityManager 实例来进行实体与数据库的链接。
有兴趣的可以了解一下两种 ORM Pattern 的区别: Active Record 和 Data Mapper 的区别
实体元信息定义
我们通过例子来介绍实体元信息的定义,比如我们定义实体类 Employee 代表雇员,那么首先我们定义 Employee 实体类,对实体类唯一的要求就是有一个支持无参构造函数的 Java Bean:
@Entity
@Table(name = "employees")
@Data
public class Employee {
@GeneratedValue(strategy = GenerationType.IDENTITY)
@Column(name = "employeeNumber")
private Integer id;
private String lastName;
private String firstName;
private String email;
private String jobTitle;
我们看到这个实体类上的注解:
- @Entity,它标注这个是需要被扫描的实体类,这个实体类的元信息需要被收集。
- @Table 代表了实体类关联的数据表信息,通过 name 指定关联的表名,你还可以在 @Table 上通过 uniqueConstraints 定义表的唯一索引,在这里略过。
接下来就是对应数据库字段的注解,实际上这类注解既可以加在类的字段上,也可以加在 getter 方法上,但一个实体类中必须使用同一种方式,在上面的例子中选择加在字段上。
首先我们介绍一下 @Basic 注解,这个注解就代表了一个类字段和数据库字段具有映射关系,且数据库字段名即为类字段名。但我们发现例子中根本没有使用 @Basic 注解?因为如果这个类被施加了 @Entity 注解,那么所有字段默认都会加上 @Basic 注解, 即默认情况下所有类字段都会映射为一个数据表字段 。如果希望某个类字段不要建立和数据库字段的映射,则可以加上 @Transient 注解 。
主键与主键生成策略
然后是用于标记主键的 @Id 注解,代表这个字段对应数据库表的主键,通常 @GeneratedValue 注解会配合使用,代表主键值生成的方式,通过 strategy 指定使用的生成策略,支持如下几种选项:
- AUTO:(默认)根据实际连接的数据库类型,选择是 IDENTITY、SEQUENCE 或者 TABLE。
- IDENTITY:使用数据库的 ID 自增的方式生成主键,Oracle 不支持。
- SEQUENCE:使用数据库的序列生成功能生成主键,MySQL 不支持。
- TABLE:使用其他数据库表的值作为当前表的主键值,一定程度影响扩展性和性能。
由于我们使用的数据库是 MySQL,我们指定的主键生成策略为 GenerationType.IDENTITY。当然 JPA 不同的实现会提供一些针对主键生成的扩展,比如 Hibernate 有 uuid 的主键生成策略,每次生成的主键都是一个唯一的 UUID,并且也支持通过实现 IdentifierGenerator 接口去实现自己的主键生成器。
列映射
通过 @Column 注解可以补充一些额外的数据库字段映射信息,默认情况下 Java 字段名与映射的列名相同,但如果想要手动指定映射到一个不一样的列名,比如上例中通过:
@Column(name = "employeeNumber")将 id 字段映射到了 employeeNumber 列。
在映射过程中还需要注意 Java 类型和数据库字段类型的映射,Hibernate 中 Java 类型和数据库字段类型的映射可 参考此文档 。
针对字符串类型和浮点数类型,还可以通过 @Column 的 length 指定长度或 precision 和 scale 指定精度,亦或是直接通过 columnDefinition 指定数据库列定义:
@Entity
@Table(name = "orderdetails")
public class OrderDetail {
@GeneratedValue
private Integer orderNumber;
@Column(name = "productCode", length = 12)
private String productCode;
private Integer quantityOrdered;
@Column(name = "priceEach", precision = 10, scale = 2)
private BigDecimal priceEach;
@Column(name = "priceEachPromotion", columnDefinition = "DEICMAL(10, 2)")
private BigDecimal priceEachPromotion;
private Integer orderLineNumber;
其实只要类型兼容的情况下,不一定需要给类字段补充 columnDefinition,但也有一些必要的场景,比如由于 @Column 注解的 length 默认值为 255,那么对于在数据库中是 text 类型的长文本字段,就会因为不兼容的问题导致映射失败了,这个情况下通过手动设置 length 的话并不优雅,就需要通过 columnDefinition 来补充数据库字段定义了。
@Entity
@Table(name = "orders")
@Data
class Order {
// ...
@Column(name = "comments", columnDefinition = "TEXT")
private String comments;
// ...
映射为自定义类型
有的时候,默认的 Java 字段类型与数据库字段类型的映射,不能满足需求, 希望将数据库字段的值转换为 Java 的枚举类型,或者转换成某个自定义的类。比如我们继续拿上面 Employee 实体举例,比如希望加入一个代表员工类型的枚举 employeeType:
package me.leozdgao.easyerp.entity;
import javax.persistence.AttributeConverter;
import java.util.stream.Stream;
* @author leozdgao
public enum EmployeeType {
// 老板
BOSS(0),
// 管理者
MANAGER(1),
// 打工人
WORKER(2);
private Integer id;
EmployeeType(Integer id) {
this.id = id;
public Integer getId() {
return id;
public static class Converter implements AttributeConverter<EmployeeType, Byte> {
@Override
public Byte convertToDatabaseColumn(EmployeeType attribute) {
return attribute.getId().byteValue();
@Override
public EmployeeType convertToEntityAttribute(Byte dbData) {
if (dbData == null) {
return null;
return Stream.of(EmployeeType.values())
.filter(v -> dbData.equals(v.getId().byteValue()))
.findFirst()
.orElseThrow(IllegalArgumentException::new)
如果要实现列到自定义数据类型的转换,需要实现 AttributeConverter<X, Y> 接口,分别实现 convertToDatabaseColumn 方法用于将自定义类型转化为可映射为数据库类型的 Java 类型,以及 convertToEntityAttribute 方法将数据库中的数据,转化为自定义类型。
最后通过 @Convert 注解指定转换器即可:
@Entity
@Table(name = "employees")
public class Employee {
// ...
@Convert(converter = EmployeeType.Converter.class)
@Column(name = "employeeType", columnDefinition = "TINYINT")
private EmployeeType employeeType;
// ...
上例拿枚举类型做了例子,另一个常见的场景就是将数据库中存的 json 串做一些转换等,这里就不再继续展开。
实体 关系描述
在画 ER 图的过程中,我们会通过 1对1 、 1对多 、 多对多 的方式来描述实体间的关系,JPA 提供的 ORM 对象关系模型就可以表达这种关系,通过代码管理实体的过程中,也基于实体间的这些关系,决定了映射到数据库执行读写时的行为。
我们可以使用以下注解来代表实体的关系:
- @OneToOne 代表一对一的实体关系。
- @OneToMany 代表一对多的实体关系。
- @ManyToOne 代表多对一的实体关系。
- @ManyToMany 代表多对多的实体关系。
一对一关系
我们来具体举一个例子,前面展示过的 ER 图的例子中,每个雇员都拥有一个独立的办公室,那么实体 Employee
和 Office 就是一个一对一的关系,我们的代码可以这样表达:
// Employee.java
@Entity
@Table(name = "employees")
@Data
public class Employee {
@GeneratedValue(strategy = GenerationType.IDENTITY)
@Column(name = "employeeNumber")
private Integer id;
private String lastName;
private String firstName;
private String email;
@OneToOne
@JoinColumn(name = "officeCode")
private Office office;
private String jobTitle;
// Office.java
@Entity
@Table(name = "offices")
@Data
public class Office {
@Column(name = "officeCode")
private String code;
private String city;
private String phone;
private String addressLine1;
private String addressLine2;
我们可以看到,在 Employee 实体中有一个类型为 Office 的字段 office,通过在这个字段上加上 @OneToOne 注解代表了实体间的一对一关系。
但是这怎么映射到数据库中去呢?通常数据库设计时是将一张表的主键作为另一张表的外键的形式代表一对一关系的,查询时通过 JOIN 语句进行查询。对应的为了可以完成对数据库表结构的映射,我们通过 @JoinColumn 注解并通过 name 指定表的外键字段名的方式,定义了在数据库的结构中如果关联到另一个实体的数据。
一对多关系
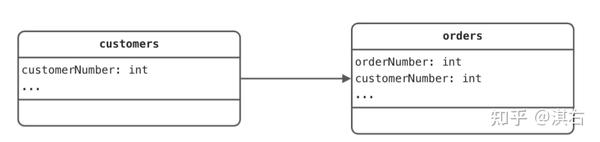
我们假设消费者下单的场景,那么这个情况下有两个实体:消费者 Customer 和订单 Order,并且是一对多的关系。这种情况下,我们希望可以通过 Customer 实体获取到订单列表,也希望通过 Order 实体查询到关联的消费者。那我们如果实现这种关系与数据库的映射呢?我们在数据库中表示一对多关系,其实有两种情况:
一种情况是让多的那个实体记录与另一个实体的关系:
@Entity
@Table(name = "customers")
public class Customer {
@GeneratedValue(strategy = GenerationType.IDENTITY)
@Column(name = "customerNumber")
private Integer id;
@OneToMany(mappedBy = "customer")
private List<Order> orders;
// ...
@Entity
@Table(name = "orders")
public class Order {
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Integer orderNumber;
@ManyToOne
@JoinColumn(name = "customerNumber")
private Customer customer;
// ...
我们在 Customer 实体中声明了 orders 字段,类型为 List<Order>,并加上了 @OneToMany 注解 ,通过 mappedBy 配置了在 Order 实体中的 customer 字段持有了关联关系。再看 Order 实体,我们在 customer 字段上加上了 @ManyToOne 注解表示了和 Customer 实体的关系,由于关联字段在数据库表上的字段为 customerNumber,于是加上 @JoinColumn 注解在完成这个映射。
另一种情况是引入额外的表来记录两个实体之间的关联,这种情况下:
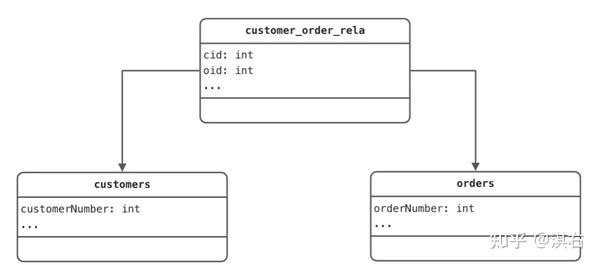
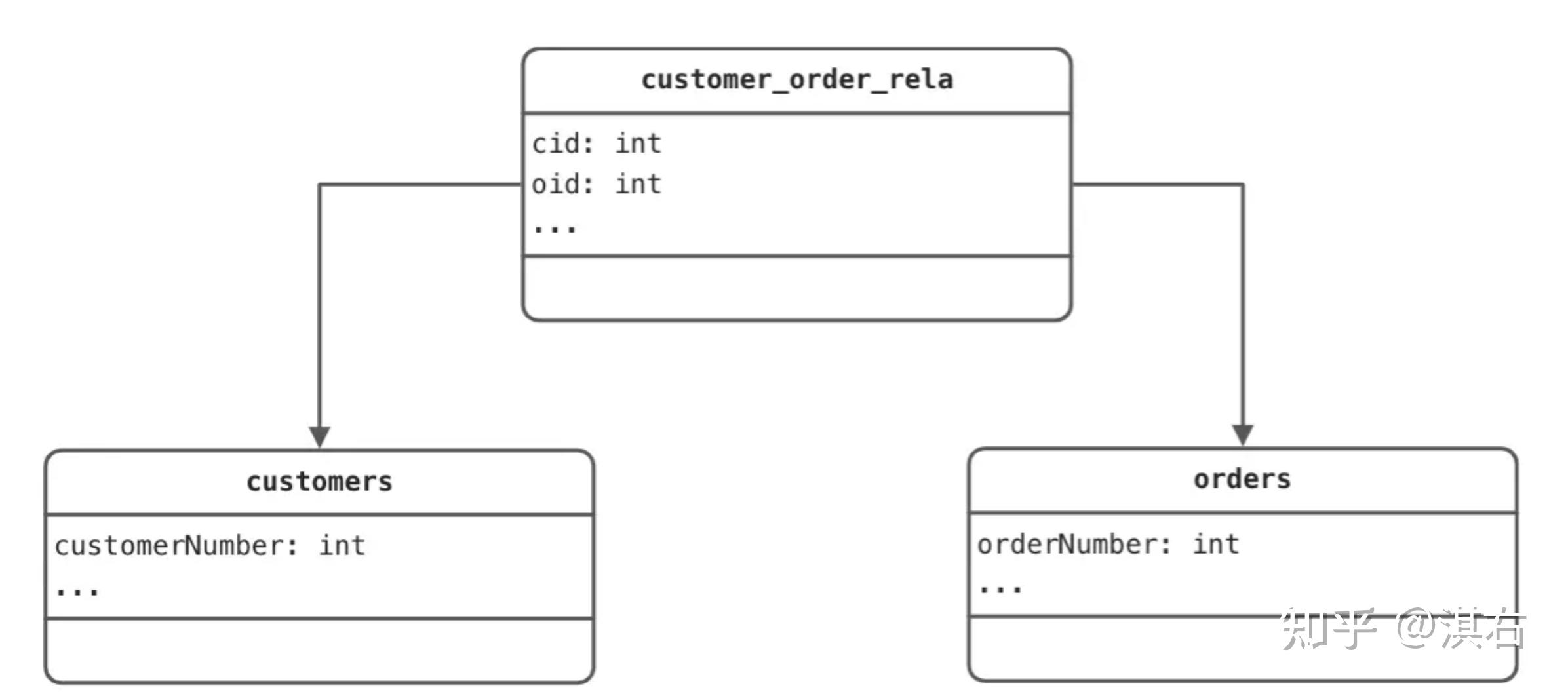
@Entity
@Table(name = "customers")
public class Customer {
@GeneratedValue(strategy = GenerationType.IDENTITY)
@Column(name = "customerNumber")
private Integer id;
@OneToMany(mappedBy = "customer")
@JoinTable(
name = "customer_order_rela",
joinColumns = @JoinColumn(name = "cid", referencedColumnName = "customerNumber"),
inverseJoinColumns = @JoinColumn(name = "oid", referencedColumnName = "orderNumber")
private List<Order> orders;
// ...
我们在 orders 字段上加上了 @OneToMany 注解,通过 @JoinTable 注解来指定关联表以及关联表与实体表的字段映射关系。
多对多关系
还有一种关系是多对多关系,比如产品 Product 和订单 Order 就是一种多对多的关系,我们在数据库中的多对多关系通常使用额外的一张关联表来记录关联关系,这个和上面一对多关系中使用额外关联表的方式基本一致:
@Entity
@Table(name = "products")
public class Product {
public String productCode;
@ManyToMany
@JoinTable(
name = "orderdetails",
joinColumns = @JoinColumn(name = "productCode", referencedColumnName = "productCode"),
inverseJoinColumns = @JoinColumn(name = "orderNumber", referencedColumnName = "orderNumber")
public List<Order> orders;
// ...
我们表示关系的注解变成了 @ManyToMany,同样也是通过 @JoinTable 注解来指定关联表以及与实体表的字段映射关系。
使用 EntityManager 进行 数据管理
介绍了实体元信息以及实体关系描述后,就基本已经了解了 JPA 提供 ORM 能力是如何和数据库表结构进行映射的了,那么接下来我们看看如果通过 JPA 来进行数据管理,由于 JPA 提供的数据管理能力中的细节非常多,这里不会全部展开,仅做概览式的介绍。
前面有提到 JPA 应用的是 ORM 的 Data Mapper Pattern ,EntityManager 实例通过一个持久化上下文( Persistence Context )负责管理实体与数据库的链接,被管理的实体的数据状态最终可以被映射到数据库中,也可以通过 API 解除对实体的管理,解除管理后,实体的数据状态就不会再被映射到数据库中去。
JPA 规定,其提供的所有的数据写操作,都必须在一个事务下进行,我们可以通过 :
entityManager.getTransaction()来获取事务对象进行事务的管理。接下来我们看看 EntityManager 提供了哪些操作数据的能力:
首先 CRUD 的部分:
- find:基于主键找到一个实体,在已知主键的情况下是一个比较遍历的查询 API。
- persist:一个新的实例加入进来被 EntityManager 管理,并插入到数据库。
- remove:移除实体,对应会删除数据库记录。
没有专门更新的 API,数据的更新直接操作实体即可,在事务提交阶段会同步数据的变更。
public class Application {
public static void main(String[] args) {
EntityManagerFactory factory = Persistence.createEntityManagerFactory("PERSISTENCE");
EntityManager entityManager = factory.createEntityManager();
// 基于主键查询
Product product = entityManager.find(Product.class, "S10_1678");
System.out.println(product);
// 打开一个事务
entityManager.getTransaction().begin();
// 更新已有数据
product.setProductName("Another Name");
// 插入新数据
Product newProduct = new Product();
newProduct.setProductCode("NEW_CODE_123");
entityManager.persist(newProduct);
// 事务提交
entityManager.getTransaction().commit();
entityManager.close();
factory.close();
你也可以手动控制被管理实体与数据的状态同步:
- flush:立刻将被管理实体的数据状态变更同步到数据。
- refresh:立刻将被管理实体的数据状态同步为当前数据库的数据,没有提交的对实体的数据变更将被放弃。
以及几个额外的针对 EntityManager 管理状态的 API:
- contains:查询传入的实体是否有被 EntityManager 管理。
- detach:将实例从 EntityManager 的管理中移除,后续对实例的操作不再同步到数据库。
- merge:返回的新实例被 EntityManager 纳入管理,事务提交后可能会发生数据插入或数据更新,同时会移除 EntityManager 传入实例的管理。
通过 SQL 进行数据管理
除了通过 EntityManager 提供 API 进行数据管理外,如果你希望更精细的控制 SQL 语句的执行,你还可以直接和 SQL 打交道。我们可以通过:
entityManager.createNativeQuery()或者:
entityManager.createQuery()得到 Query 对象,进而进行 SQL 的执行。下面的内容来介绍 JPA 中几种直接通过 SQL 进行数据管理的方式
Criteria
JPA Criteria API 是一种通过面向对象的风格来构造 SQL 语句的方式,可以把它看做 SQL Builder 的一种实现。我们可以通过:
entityManager.getCriteriaBuilder()获取 CriteriaBuilder Criteria 构造器实例,可以构造的 Criteria 对象包括 CriteriaQuery 用于查询,CriteriaUpdate 用于更新,CriteriaDelete 用于删除,同时 CriteriaBuilder 还提供了一些面向对象风格的表达式构造方式:
public class Application {
public static void main(String[] args) {
EntityManagerFactory factory = Persistence.createEntityManagerFactory("PERSISTENCE");
EntityManager entityManager = factory.createEntityManager();
CriteriaBuilder cb = entityManager.getCriteriaBuilder();
// ================= 应用 CriteriaQuery =================
CriteriaQuery<Product> cr = cb.createQuery(Product.class);
Root<Product> qRoot = cr.from(Product.class);
cr.select(qRoot).where(cb.gt(qRoot.get("buyPrice"), 1000));
TypedQuery<Product> query = entityManager.createQuery(cr);
List<Product> results = query.getResultList();
// ================= 应用 CriteriaUpdate =================
CriteriaUpdate<Product> criteriaUpdate = cb.createCriteriaUpdate(Product.class);
Root<Product> uRoot = criteriaUpdate.from(Product.class);
criteriaUpdate.set("productName", "AnotherName");
criteriaUpdate.where(cb.equal(uRoot.get("productCode"), "TARGET_CODE"));
entityManager.getTransaction().begin();
// 执行更新
entityManager.createQuery(criteriaUpdate).executeUpdate();
entityManager.getTransaction().commit();
// ================= 应用 CriteriaDelete =================
CriteriaDelete<Product> criteriaDelete = cb.createCriteriaDelete(Product.class);
Root<Product> dRoot = criteriaDelete.from(Product.class);
criteriaDelete.where(cb.greaterThan(dRoot.get("productCode"), "TARGET_CODE"));
entityManager.getTransaction().begin();
// 执行删除
entityManager.createQuery(criteriaDelete).executeUpdate();
entityManager.getTransaction().commit();
entityManager.close();
factory.close();
JPQL
JPQL 是一种 DSL,语法类似 SQL 但也有面向对象的思想在其中,如果说 SQL 面向的是数据库表的话,JPQL 就是面向实体的,比如:
SELECT p FROM Product p WHERE p.productCode = 'S12_1099'
我们可以看到我们的查询对象并不是从数据库表,而是实体,我们也可以通过 :keyword 语法根据参数名插值,或者是 ?0 语法根据参数索引值插值。
SELECT p FROM Product p WHERE p.productCode = :code
SELECT p FROM Product p WHERE p.productCode = ?0
JPQL 还提供一些常用的内置函数,这里简单举几个例子:
// 字符串拼接
select concat('产品', p.productName) from Product p
// 获取子字符串
select substring(p.productName, 1, 1) from Product p
// 去头尾
select trim(leading 产品' from p.productName) from Product p
// 当前时间常量
select CURRENT_DATE, CURRENT_TIME, CURRENT_TIMESTAMP from Product p
我们来看一个应用的例子:
public class Application {
public static void main(String[] args) {
EntityManagerFactory factory = Persistence.createEntityManagerFactory("PERSISTENCE");
EntityManager entityManager = factory.createEntityManager();
TypedQuery<Product> query = entityManager.createQuery("SELECT p FROM Product p WHERE p.productCode = :code", Product.class);
query.setParameter("code", "S12_2823");
List<Product> result = query.getResultList();
entityManager.close();
factory.close();
需要注意的是,由于 JPQL 的数据管理操作时面向实体的,所以由于存在实体关系,为了让一条 JPQL 得到正确的结果,可能背后可能会有多条 SQL 语句执行。
这里不再对 JPQL 语法做更多探讨,有兴趣的话可以参考更完整的 JPQL 语法说明可参考 Oracle 官方文档 。
Native SQL
最后就是完全手写 SQL,同样的可以通过 :keyword 语法根据参数名插值,或者是 ?0 语法根据参数索引值插值。如果不传实体类参数,返回的每一项都是 Object 数组,和数据库字段一一对应,如果传了实体类参数,除了会执行提交的 SQL 外,还会根据实体元信息进行额外的映射或者根据实体关系执行额外的 SQL:
public class Application {
public static void main(String[] args) {
EntityManagerFactory factory = Persistence.createEntityManagerFactory("PERSISTENCE");
EntityManager entityManager = factory.createEntityManager();
// 手写 SQL
Query query = entityManager.createNativeQuery("SELECT * FROM employees WHERE employeeNumber = :number");
query.setParameter("number", 1002);
List results = query.getResultList();
// 或者
Query query = entityManager.createNativeQuery("SELECT * FROM employees WHERE employeeNumber = ?0", Employee.class);
query.setParameter(0, 1002);
List<Employee> results = (List<Employee>) query1.getResultList();
entityManager.close();