问题:pandas组内排序,并在每个分组内按序打上序号
描述:
pandas dataframe 对dep_id组内的salary排序。希望给下面原本只有前三列的dataframe,添加上第四列。
等价于sql里的排序函数 row_number() over() 功能
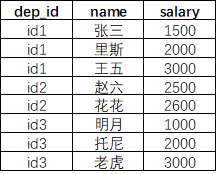
假设我已经建好了仅有前三列的dataframe,数据集命名为 MyData,那么解决方案如下:
MyData['sort_id'] = MyData['salary'].groupby(MyData['dep_id']).rank()
结果如下:

pandas组内排序,并在每个分组内按序打上序号pandas dataframe 对dep_id组内的salary排序。希望给下面原本只有前三列的dataframe,添加上第四列。等价于sql的row_number()假设我已经建好了仅有前三列的dataframe,数据集命名为 MyData,那么解决方案如下:MyData[‘sort_id’] = MyData[‘salary’].gr...
摘要:本文主要是讲解一下,如何进行排序。分为两种情况,不分组进行排序和组内进行排序。什么意思呢?具体来说,我举个栗子。
****注意****
如果只是单纯想对某一列进行排序,而不进行打序号的话直接使用.sort_values就可以了。下文是关于如何把序号也打上的
————————————————————————————
我们有一个数据集如下:
我们下面想进行两种排序。先说第一种比较简单的也是很常用的,简单的对某一列进行排序然后添加一列序号。
例如,我们队comment_num这一列进行从大到小的排序,然后给出序号。如下图:
可以看到,sort_num这一列就是我们队comment_num的
import pandas as pd
df = pd.DataFrame({'class':['a','a','b','b','a','a','b','c','c'],'score':[3,5,6,7,8,9,10,11,14]})
摘要:本文主要是讲解一下,如何进行排序。分为两种情况,不分组进行排序和组内进行排序。什么意思呢?具体来说,我举个栗子。
****注意****
如果只是单纯想对某一列进行排序,而不进行打序号的话直接使用.sort_values就可以了。下文是关于如何把序号也打上的
————————————————————————————
我们有一个数据集如下:
我们下面想进行两种排序。先说第一种比
如果只是单纯想对某一列进行排序,而不进行打序号的话直接使用.sort_values就可以了。下文是关于如何把序号也打上的
1·首先是不分组进行排序 (按user_id排序)
数据格式如下:
data1['sort_num']=data1['user_id'].rank(ascending=1,method='first')
data1['sort_num']=data1['user_id']...
排名(ranking)跟排序关系密切,切它会增设一个排名值(从1开始,一直到数组中有效数据的数量)。
它跟numpy.argsort产生的间接根据索引排序差不多,只不过它可以根据某种规则破坏平级关系。
默认情况下,rank是通过 “为各...
整理了一下一行数据的排序和得出序号的各类方法,包括正序和倒序。当然还有pandas包的sort_value和sort_index两个method没有包含在这里。如果是多维的数据,需要将axis=0或者1包含进去。
import numpy as np
import pandas as pd
# ================================================...
pandas的DataFrame极大地简化了数据分析过程中一些烦琐操作,它是一个表格型的数据结构, 每一列代表一个变量,而每一行则是一条记录。简答地说,DataFrame是共享同一个index 的Series的集合。DataFrame数据的排序分为三类:
对于索引排序,涉及到对行的索引和对列的索引进行升序或者降序排序函数df.sort_index(axis= , ascending= , inplace=),需要特别注意这三个参数。axis表示对行的索引排序,还是对列的索引进行排序;ascending表
data = [['a','3'],['b','1'],['c','2']]
df = pd.DataFrame(data)
df = df.sort_values(by = 1,axis = 0,ascending = False)
print(df)
对一个dataframe的列排序后,他的行索引是乱的
咱们就可以用
def sort_and_rank(group):
sorted_group = group.sort_values(ascending=False)
ranked_group = pd.Series(range(1, len(group)+1), index=sorted_group.index)
return ranked_group
# 对每个组应用排序函数并新建序号列
df['rank'] = df.groupby('group')['value'].apply(sort_and_rank)
# 输出结果
print(df)
输出结果如下:
group value rank
0 A 3 1
1 A 1 2
2 B 4 2
3 B 2 3
4 B 5 1
5 C 6 1
其中,rank列即为新建的序号列,表示每个组内按照value值从大到小排名的结果。

